一种基于布尔矩阵的后验双阈值电力大数据Apriori并行方法与流程
本发明属于电力技术领域,尤其是一种基于布尔矩阵的后验双阈值电力大数据apriori并行方法。
背景技术:
随着经济技术的发展,电力系统已经成为了社会发展的重要基础,掌握电力大数据应用的关键技术,将有利于电力行业的可持续发展和建立坚强的智能电网。经过多年的发展与沉淀,目前国家电网积累了全网相当多的客户档案数据和海量供电服务信息,以及公司营销、电网生产等数据。因此,如何对海量的电网业务数据进行快速计算分析,为智能电网的快速建设提供参考依据,对智能电网的安全、可靠运行具有重要的研究意义。
在面对大量数据时,传统apriori算法需要进行多次数据库遍历以及可能建立大量候选项的缺陷会导致系统内存占用量大、磁盘i/o读写操作频繁,算法运行效率低。
针对电力数据计算效率较低的问题,近年来国内外学者已经取得了一定的研究成果。高盼等提出了一种基于hadoop的电力大数据apriori并行计算方法,提出一种面向电力大数据的apriori并行化改进算法,通过设置最小支持度和构建频繁集矩阵,使数据处理效率得到提高。
但是,上述方法只是将apriori算法进行了并行化处理,在算法的执行阶段采取可分而治之的策略,虽然对算法的运行效率有了改进,但是在数据的处理和读取阶段没有对数据进行相应的处理,会导致算法频繁的去扫描数据库,增加过多的冗余操作。
谢志明等提出了一种基于mapreduce架构的并行矩阵apriori算法,将基于矩阵关联规则算法与mapreduce相结合,并通过实验验证移植到云计算平台的apriori_m算法对海量数据挖掘的有效性带来更高的工作效率。
但是,虽然该方法在一些研究方面取得了很显著的成效,但是算法数据简洁性不够好,可能会产量大量的频繁性候选集,导致输出的结果的不准确,降低了算法的准确度。
另外,目前对于电力大数据的频繁项集额挖掘算法研究的较少,故基于布尔矩阵后验双阈值后验双阈值电力大数据apriori算法的研究也是相对较少。
技术实现要素:
本发明目的在于针对现有技术的不足之处,提供一种基于布尔矩阵的后验双阈值电力大数据apriori并行方法,该方法采取了后验双阈值的apriori并行算法,并且引入布尔矩阵和去除率的概念来对数据的处理进行剪枝和压缩存储,实现算法的运算并将其应用于电力大数据,达到减少计算次数的目的,最终实现电力大数据高效并行化计算,有效地解决了电力大数据的计算瓶颈问题,有效地提升了电力大数据的准确度、效率和数量。
为了实现上述目的,本发明所采用的技术方案如下:
一种基于布尔矩阵的后验双阈值电力大数据apriori并行方法,其特征在于:所述方法包括如下步骤:
在数据处理阶段,采用布尔矩阵实现对事务矩阵的压缩,减少计算次数,从而达到提高算法计算效率的目的;
在数据读取阶段引入去除率概念,利用去除率的概念对事务数据库进行剪枝操作,在对数据进行读取时会根据去除率去抛弃一部分数据;
在算法执行阶段首先采用并行处理,将事务数据库d划分成n个非重叠的子事务数据库,保证了各事务的同等重要性,被挖掘的机会均等;
再者采用双支持度,通过增加一个非频繁项集支持度阈值来提取非频繁项集,以此降低其维度;
在算法执行结束后,验证最终的频繁项集是否为所期望得到的,故引入提升度的概念去验证,因为在数据读取阶段采用去除率,会抛弃一部分数据,用提升度概念去验证,如果验证正确,便输出最终频繁项集,如果验证不正确,则返回算法第一步继续执行,直到验证正确为止。
而且,具体步骤如下:
步骤一:用布尔矩阵对数据进行压缩
该步骤基于boole矩阵的apriori算法,通过剪枝操作,实现对事务矩阵的压缩,减少计算次数,从而达到提高算法计算效率的目的;其基本步骤如下:
step1:扫描事物数据库,将事务数据库转换为0-1形式的boole矩阵:
step2:由上式(1)计算出项集ii的支持度计数即矩阵中1的个数:
因此,ii和ij的支持度计数为ij支持度计数基础上列同时为1的个数:
由此式计算出的支持度计数与最小支持度比较,若小于最小支持度,则删除所在行;
step3:计算频繁k-项集中项集的个数|lk|;
step4:判断|lk|和(k+1)的大小,当前者大于后者时,结束算法流程,反之则删除事务长度小于k+1的事务所在的行;
step5:由频繁k-项集连接得到(k+1)-项集,并进行剪枝操作,计算(k+1)-项集的支持度;
步骤二:引入去除率进行剪枝
原数据中元素种类有n项,支持度设置为10%;引入一个去除率概念,预选项集经过对数据遍历、统计后去除数据所占百分比p;假设满足最小支持度的k阶频繁项数为m项;项数m计算公式如下:
m=n*p
对已生成的频繁1项集进行k+1项组合得到新的k+1阶预选项组合;k+1阶预选项组合数计算公示为数据的排列;
c(m,k+1)=m!/(k+1)!(m-(k+1))!
对于k+1阶频繁预选项集组合再次进行数据对比统计,去除不符合最小支持度的组合;重复如上连接去除步骤,直到没有更高阶的频繁预选项项组合,得到最终的频繁项集;
步骤三:进行双阈值并行处理
并行处理:采用将改进后的apriori算法应用于大数据平台并行化处理,实行分而治之的思想;将事务数据库d划分成n个非重叠的子事务数据库;
双阈值处理:提出双阈值的概念,双阈值的含义是运用频繁项集和非频繁项集从两个方面设立阈值来进行apriori算法的数据挖掘,频繁项集就是根据apriori算法的支持度和最小置信度来设立阈值,非频繁项集就是根据apriori算法的支持度和最小置信度的补给来设立阈值,挖掘得到数据的非频繁项集;
项集的支持度是一个与语料库规模有关的度量;假定一个在100个事务中项集x的支持度为0.4,这就意味着40%的事务包含这个项集x;因此,支持度是项集的一种相对度量,不能仅仅依靠支持度来选择重要的项集;提出一种双支持度阈值的频繁、非频繁项集提取方法,通过增加一个非频繁项集支持度阈值来提取非频繁项集,以此降低其维度;
非频繁项集的支持度用fsup表示,fsup=1-sup,非频繁项集的支持度的含义与频繁项集的支持度的含义相同,通过两个不同的支持度来获得频繁和非频繁项集,以此来过滤掉一些不感兴趣的非频繁项;
步骤四:利用提升度对结果进行验证
提升度的定义为:提升度表示含有y的条件下,同时含有x的概率,与x总体发生的概率之比,用lift(x<=y)表示,其表达式为:
在得到频繁项集后,利用提升度去验证,具体验证过程如下:
(1)若提升度大于1,则x<=y是有效的强关联规则,故输出结果,算法结束;
(2)若提升度小于1,则x<=y是无效的强关联规则,故返回数据读取阶段,重新执行算法;
(3)若提升度等于1,则x与y相互独立,此时p(x/y)=p(x),故返回数据读取阶段,重新执行算法。
本发明取得的优点和积极效果为:
1、本发明方法针对电力数据计算效率较低的问题,提出一种基于布尔矩阵的后验双阈值电力大数据apriori并行方法,该方法采取了后验双阈值的apriori并行算法,并且引入布尔矩阵和去除率的概念来对数据的处理进行剪枝和压缩存储,实现算法的运算并将其应用于电力大数据,达到减少计算次数的目的,最终实现电力大数据高效并行化计算;通过该方法有效地解决了电力大数据的计算瓶颈问题,有效地提升了电力大数据的准确度、效率和数量。
2、本发明方法在数据处理阶段,采用布尔矩阵和去除率对数据进压缩存储和剪枝操作,实现对事务矩阵的压缩和冗余数据的取出,减少扫描和计算次数,从而达到提高算法计算效率的目的。
3、本发明方法在算法执行阶段,采用了双阈值并行处理,不仅保证了算的执行效率,还用双阈值降低降低其维度,保证了算法的效率和简洁性。
4、本发明方法采取了后验的方式,引入了提升度的概念,对算法得到的结果利用提升度进行验证,保证了得到的数据在经过前期剪枝处理后的准确性,使算法在保证简洁性的同时,准确度也有了保证。
附图说明
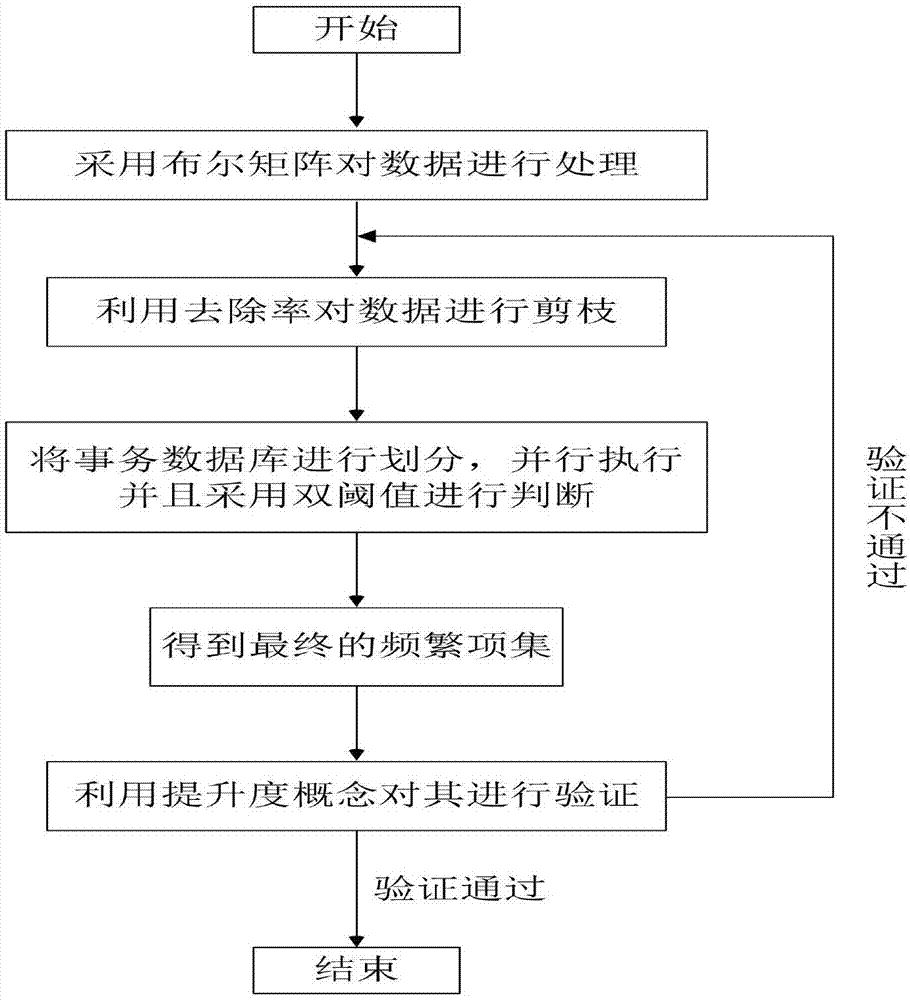
图1为本发明基于布尔矩阵的后验双阈值电力大数据apriori算法流程图;
图2为本发明验证检测时apriori算法改进前后集群运行效率对比图。
具体实施方式
下面结合实施例,对本发明进一步说明;下述实施例是说明性的,不是限定性的,不能以下述实施例来限定本发明的保护范围。
本发明中所使用的器件,如无特殊规定,均为本领域内常用的器件;本发明中所使用的方法,如无特殊规定,均为本领域内常用的方法。
一种基于布尔矩阵的后验双阈值电力大数据apriori并行方法,所述方法包括如下步骤:
本发明对apriori算法的各个环节都进行了优化改进,如图1所示。在数据处理阶段,采用布尔矩阵实现对事务矩阵的压缩,减少计算次数,从而达到提高算法计算效率的目的。在数据读取阶段引入去除率概念,利用去除率的概念对事务数据库进行剪枝操作,在对数据进行读取时会根据去除率去抛弃一部分数据,此操作保证了apriori算法最后不会出现较大的频繁预选项集,对之后的数据分析提供了方便。在算法执行阶段首先采用并行处理,将事务数据库d划分成n个非重叠的子事务数据库,使各子事务数据库大小差异较小,从而保证了各事务的同等重要性,被挖掘的机会均等。再者采用双支持度,通过增加一个非频繁项集支持度阈值来提取非频繁项集,以此降低其维度。在算法执行结束后,验证最终的频繁项集是否为所期望得到的,故引入提升度的概念去验证,因为在数据读取阶段采用去除率,会抛弃一部分数据,用提升度概念去验证,如果验证正确,便输出最终频繁项集,如果验证不正确,则返回算法第一步继续执行,直到验证正确为止。
一种基于布尔矩阵的后验双阈值电力大数据apriori并行方法,具体步骤如下:
步骤一:用布尔矩阵对数据进行压缩
apriori算法在寻找强关联规则过程中存在迭代扫描次数过多、占据数据库容量过大等问题,该步骤基于boole矩阵的apriori算法,通过剪枝操作,实现对事务矩阵的压缩,减少计算次数,从而达到提高算法计算效率的目的。其基本步骤如下:
step1:扫描事物数据库,将事务数据库转换为0-1形式的boole矩阵:
step2:由上式(1)计算出项集ii的支持度计数即矩阵中1的个数:
因此,ii和ij的支持度计数为ij支持度计数基础上列同时为1的个数:
由此式计算出的支持度计数与最小支持度比较,若小于最小支持度,则删除所在行;
step3:计算频繁k-项集中项集的个数|lk|;
step4:判断|lk|和(k+1)的大小,当前者大于后者时,结束算法流程,反之则删除事务长度小于k+1的事务所在的行;
step5:由频繁k-项集连接得到(k+1)-项集,并进行剪枝操作,计算(k+1)-项集的支持度。
步骤二:引入去除率进行剪枝
在apriori算法计算过程中,当支持度设置较小或数据中元素种类数目较大时,算法可生成较大的频繁预选项集。
原数据中元素种类有n项,支持度设置为10%。引入一个去除率概念,预选项集经过对数据遍历、统计后去除数据所占百分比p。假设满足最小支持度的k阶频繁项数为m项。项数m计算公式如下:
m=n*p
对已生成的频繁1项集进行k+1项组合可以得到新的k+1阶预选项组合。k+1阶预选项组合数计算公示为数据的排列。
c(m,k+1)=m!/(k+1)!(m-(k+1))!
对于k+1阶频繁预选项集组合再次进行数据对比统计,去除不符合最小支持度的组合。重复如上连接去除步骤,直到没有更高阶的频繁预选项项组合。得到最终的频繁项集。
步骤三:进行双阈值并行处理
apriori算法的改进种类较多,由于在算法执行过程中采用了串行方法,导致改进后的方法在处理大数据时仍存有缺陷。因此,本发明设计采用将改进后的apriori算法应用于大数据平台并行化处理,实行分而治之的思想。将事务数据库d划分成n个非重叠的子事务数据库,使各子事务数据库大小差异较小,从而保证了各事务的同等重要性,被挖掘的机会均等。由于采用的是并行化挖掘,所以整个事务数据库的挖掘时间由耗时最长的子事务数据库的挖掘时间决定。这样一来可以减少算法的执行时间。(并行处理)
本发明提出了双阈值的概念,双阈值的含义是运用频繁项集和非频繁项集从两个方面设立阈值来进行apriori算法的数据挖掘,频繁项集就是根据apriori算法的支持度和最小置信度来设立阈值,非频繁项集就是根据apriori算法的支持度和最小置信度的补给来设立阈值,挖掘得到数据的非频繁项集。
因为数据集中提取的项集(无论是频繁还是非频繁项集)数量都十分巨大,但是其中只有很少的一部分可以用于生成感兴趣的关联规则。因此,选择这些有用的信息具有重要意义。项集的支持度是一个与语料库规模有关的度量。假定一个在100个事务中项集x的支持度为0.4,这就意味着40%的事务包含这个项集x。因此,支持度是项集的一种相对度量,不能仅仅依靠支持度来选择重要的项集。本发明提出了一种双支持度阈值的频繁、非频繁项集提取方法。通过增加一个非频繁项集支持度阈值来提取非频繁项集,以此降低其维度。
非频繁项集的支持度用fsup表示,fsup=1-sup,非频繁项集的支持度的含义与频繁项集的支持度的含义相同,通过两个不同的支持度来获得频繁和非频繁项集,以此来过滤掉一些不是很感兴趣的非频繁项。(双阈值处理))
apriori算法的支持度sup是apriori算法的基础,技术人员可以轻松得到,故fsup=1-sup也容易得到。
步骤四:利用提升度对结果进行验证
提升度的定义为:提升度表示含有y的条件下,同时含有x的概率,与x总体发生的概率之比,用lift(x<=y)表示,其表达式为:
在得到频繁项集后,利用提升度去验证,具体验证过程如下:
(1)若提升度大于1,则x<=y是有效的强关联规则,故输出结果,算法结束。
(2)若提升度小于1,则x<=y是无效的强关联规则,故返回数据读取阶段,重新执行算法。
(3)若提升度等于1,则x与y相互独立,此时p(x/y)=p(x),故返回数据读取阶段,重新执行算法。
本发明方法的相关验证检测:
(1)方法:
为验证改进的本发明apriori算法在电力数据计算过程的有效性,利用hadoop集群环境进行测试验证,测试平台采用c/s模式,通过在服务器端部署大数据平台hadoop,该平台搭建的集群环境包含了1个master主节点,3个slave任务节点,其中主节点作为中心服务器管理节点,负责集群的资源分配和作业调度,任务节点负责具体的任务运行,当任务作业提交至主节点后,主节点将其分成若干小任务并分配至各任务节点。
将未改进的apriori并行化算法与本发明改进后的算法的性能进行对比,实验选取某电力信息采集部门历史数据,并对选取的数据集进行简单的预处理,上传业务数据至hdfs,编写apriori并行化算法与基于布尔矩阵的的后验双阈值电力大数据apriori并行化算法代码,在shell脚本下分别对算法进行调用,得出算法改进前后的集群运行效率。
(2)结果:
对比分析图如图2所示,由图2可知,在对相同力数据进行计算分析的时候,集群的并行化运行时间与所采用的具体算法有关,当采取的apriori并行化算法由基于布尔矩阵的后验双阈值电力大数据apriori并行算法取代后,集群对业务数据的处理时间明显缩短,处理效率得到有效提高;并且在进行大量数据处理时,处理时间有了明显的缩短,体现了算法的优越性。
- 还没有人留言评论。精彩留言会获得点赞!