一种多特征自动分级聚合辅助下的遥感影像样本库快速标记方法与流程
本发明属于图像数据处理方法,具体涉及一种多特征自动分级聚合辅助下的遥感影像样本库快速标记方法。
背景技术:
构建有标记样本库是开展数据驱动的遥感影像分析与应用的一个关键问题。近年来,随着遥感技术和人工智能领域的快速发展,深度学习技术在遥感影像的智能化分析解译中发挥着越来越重要的作用。深度学习技术依赖大规模的有标记训练数据,而目前遥感影像样本库太小,不足以支撑完整的深度学习过程。此外,遥感影像类型丰富,对于大规模遥感影像样本库来说,仅仅通过人工劳动不可能为每种类型的遥感影像进行快速有效的标注。
为了降低人工标注成本,目前的遥感影像样本库标记主要有两类方法:一种方法为利用开放街道地图(osm)中的兴趣点和矢量数据来表示遥感图像中的地理空间对象,并通过提取以所指示的地理空间为中心的场景来完成场景标注。另一种为利用专家知识的交互式主动聚类方法。然而,基于osm的方法仍然需要人工检查来修改开放街道地图中的误差,而主动聚类的方法仍然需要数百次的专家反馈来增强标注精度。除了上述两种方法之外,半监督学习方法对于样本库标记也有不错的效果,但是由于半监督方法中只可接受几种类型的特征描述符,不足以全面表征遥感影像。如果盲目增加特征数量,则会产生维数灾难的问题。
技术实现要素:
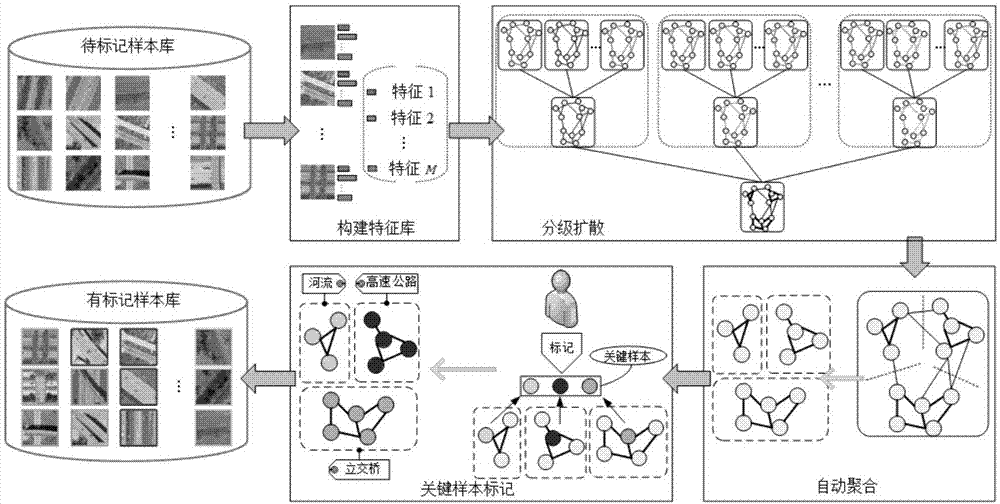
本发明提出了一种多特征自动分级聚合辅助下的遥感影像样本库快速标记方法,旨在解决遥感领域大规模标记样本库方法匮乏的问题。该方法首先对样本库中的影像提取多个特征,然后利用分级结构的图扩散模型对多个特征进行融合扩散。针对扩散结果,利用谱聚类将原有样本库自动聚合为若干个簇。最后以簇为基本标注单元,通过相似性分析确定每个簇中的关键样本,利用关键样本对簇进行标注,从而完成对整个样本库的全标记。
本发明所采用的技术方案是:一种多特征自动分级聚合辅助下的遥感影像样本库快速标记方法,包括以下步骤:
步骤1,构建样本特征库:对于包含n幅遥感影像的样本库,首先利用已有的特征提取方法进行图像特征提取,得到样本库的特征库f;其中提取m种类型特征,则整个样本库的特征库可以表示为f={f1,f1,…,fm},其中
步骤2,分级融合扩散,包括如下子步骤,
步骤2.1,构建相似性图:根据特征库f,针对特征库每个特征建立样本之间的相似性图其中相似性图包含的个数与特征数m相等;
步骤2.2,子树分配:首先确定子树个数
步骤2.3,生成局部连接图:根据全连接图,即步骤2.1中的相似性图,构建局部连接图,其中局部连接图中的每个顶点仅仅与它最相近l个邻接顶点相连;
步骤2.4,第一级融合扩散:利用交叉扩散模型,根据全连接图的状态矩阵和局部连接图的核矩阵,对每个子树内的d个多特征进行第一级的融合扩散,获得每个子树的混合多特征相似性矩阵;
步骤2.5,第二级融合扩散:根据步骤2.4得到共h个子树的融合扩散结果,利用交叉扩散模型进行第二级融合扩散,得到最终的相似性矩阵;
步骤3,样本库标记,包含以下子步骤:
步骤3.1,自动聚合:结合步骤2得到的最终的相似性矩阵,利用谱聚类算法对待标记样本库进行自动聚合获得簇;
步骤3.2,关键样本标记:根据3.1得到的簇,在每个簇中选取关键样本作为参考对簇进行标记最终得到每一类的有标记标志性样本。
进一步的,步骤1中已有的特征提取方法包括vgg网络迁移特征,无监督k-means学习特征,lbp特征,hog特征。
进一步的,步骤2.1中相似性图的具体构建方法如下,
设相似性图g=(v,e,w),相似性图的顶点v={1,2,...,n}表示样本库中的影像,边
其中||·||2表示欧氏距离,
进一步的,步骤2.2中计算不同特征之间的不相似性计算方法如下,
其中s为标量,表示特征之间的不相似性,n表示子树内顶点的个数,即子树内样本的个数,ws表示子树内已经选择特征的相似性矩阵的均值,wh表示候选特征的相似性矩阵,s值越大表示特征之间的不相似性越大,即互补性越强。
进一步的,步骤3.1中利用谱聚类算法对待标记样本库进行自动聚合获得簇的具体实现方式如下,
假设聚类数量为c,那么待标记样本库自动聚合为c个聚类a1,a2,...,ac,
其中
进一步的,步骤3.2中关键样本的选取方式如下,
对于第α个簇,关键样本由下式计算:
其中aα∈rn×n为第α个簇相似性矩阵,n为簇中样本的个数,
与现有技术相比,本发明的优点和有益效果:采用自动聚合辅助下的标注方法,将原始样本库分为若干个簇,对每个簇进行标记,大大降低了标记的时间消耗;采用了多个特征对影像进行表征,使得图像表达更加准确;利用分级扩散模型,将互补性较强的特征分配到同一子树内,使得多特征融合效果更好,使得自动聚合与标注结果更加准确。
附图说明
图1是本发明的流程图;
图2是分级融合扩散示例。图的顶点代表数据集中的样本,每个数字代表对应由不同特征构造的连接图。图中两个节点之间的连接反映了它们之间的相似性,而边的厚度反映了相似性的强度。需要注意的是,图中每对节点之间应该存在链接;但是,本例仅显示了一些关键链接作为示例;
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种基于高分辨率遥感影像的城市阴影检测去除方法,包括以下步骤:
(1)构建样本特征库步骤
对于包含n幅遥感影像的样本库,首先需要利用已有的特征提取方法进行图像特征提取,得到样本库的特征库f。其中提取m种类型特征,则整个样本库的特征库可以表示为f={f1,f1,…,fm},其中
(2)分级融合扩散步骤,包括以下子步骤
(2.1)构建相似性图:根据特征库f,可以针对特征库每个特征建立样本之间的相似性图g=(v,e,w),其中相似性图包含的个数与特征数m相等,初始构建的相似性图为全连接图,全连接图每个顶点与其他所有顶点都有连接。相似性图的顶点v={1,2,...,n}表示样本库中的影像。边
其中||·||2表示欧氏距离,
(2.2)子树分配:首先确定子树个数
其中s为标量,表示特征之间的不相似性,n表示子树内顶点的个数,即子树内样本的个数。ws表示子树内已选择特征的相似性矩阵的均值,wh表示候选特征的相似性矩阵。s值越大表示特征之间的不相似性越大,即互补性越强。根据计算结果,选择s值最大的候选特征的相似性矩阵加入到子树中,最终将不同特征所构建的相似性图分到不同的子树当中。
(2.3)生成局部连接图:根据全连接图,构建局部连接图
其中v为全连接图的顶集合,定义在步骤(2.1)中。
(2.4)第一级融合扩散:利用交叉扩散模型,对每个子树内的d个多特征进行第一级的融合扩散。
其中d=1,2,...,d,t=1,2,...,t,pd(0)表示初始状态矩阵,pd(t)表示第d个子树第t次迭代的扩散结果,
第一次融合扩散结果得到每个子树的混合多特征相似性矩阵
(2.5)第二级融合扩散:根据步骤2.4得到共h个子树的融合扩散结果。对第一次融合扩散结果,按照(2.2)中的方法再次构建新的局部连接图,再次计算特征融合之后的状态矩阵与核矩阵,利用交叉扩散模型进行第二级融合扩散。
其中h=1,2,...,h,t=1,2,...,t,ph(t)表示第t次迭代的扩散结果,i表示判别矩阵。根据融合扩散结果,得到最终的相似性矩阵
(3)样本库标记,包含以下子步骤:
(3.1)自动聚合:结合步骤2得到的相似性矩阵,利用谱聚类算法对待标记样本库进行自动聚合。假设聚类数量为c,那么待标记样本库自动聚合为c个聚类a1,a2,...,ac。
其中
(3.2)关键样本标记:根据3.1得到的簇,在每个簇中选取关键样本作为参考对簇进行标记最终得到每一类的有标记标志性样本。对于第α个簇,关键样本可以由下式计算:
其中aα∈rn×n为第α个簇相似性矩阵,
实施例:
1、构建样本特征库
对待标记样本库中的样本进行多特征提取,常用的特征有深度学习迁移特征,如vgg网络迁移特征;无监督特征,如无监督k-means学习特征;人工特征,如lbp特征,hog特征。
2、分级扩散
首先针对特征库每个特征建立样本之间的相似性图;然后根据特征数量,确定子树的以及子树内包含的特征个数;然后在每个子树内,计算根据不同特征所构建的相似性图之间的不相似性,挑选出互补性最强的特征加入子树内。如图2所示,其中相似性图中每一个顶点表示样本库中的一幅影像,而边的粗细表示两个样本之间相似性大小。
其中第一次融合扩散在每个子树内进行,经过第一次融合扩散,得到每个子树的融合后增强的相似性图。紧接着,通过第二次融合扩散得到最终的融合结果。
3、自动聚合
通过谱聚类算法,将增强后的相似性图根据可以自动聚合为不同的簇,同一类别样本大部分被跟到同一簇内。
4、关键样本标记
在每一簇内,分析样本之间的相似性,得到关键样本。人工标记关键样本,每一簇内的关键样本类别即代表整个簇内的类别,最终得到整个样本库的全部样本标记。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!