一种基于改进DQN的视频游戏模拟方法与流程
本发明涉及视频游戏模拟方法,涉及人工智能技术领域。
背景技术:
谷歌公司的人工智能研究团队deepmind近两年公布了两项令人瞩目的研究成果:基于atari视频游戏的深度强化学习算法[1]和计算机围棋初弈号[2]。这些工作打破了传统学术界设计类人智能学习算法的桎梏,作为一种崭新的机器学习方法,深度强化学习将深度学习和强化学习技术结合起来,使智能体能够从高维空间感知信息,并根据得到的信息训练模型、做出决策,可用于解决智能体在复杂高维状态空间中的感知决策问题[3]。
2015年,mnih等人[1]提出了一种深度q网络(deepqnetwork,dqn)模型,它是将卷积神经网络和q学习结合,并集成经验回放技术实现的[4]。dqn模拟人类玩家进行游戏的过程,直接将游戏画面作为信息输入,游戏得分作为学习的强化信号[5]。研究人员对训练收敛后的算法进行测试,发现其在49个视频游戏中的得分均超过人类的高级玩家。通过经验回放技术和固定目标q网络,dqn有效解决了使用神经网络非线性动作值函数逼近器带来的不稳定和发散性问题,极大提升了强化学习的适用性。经验回放增加了历史数据的利用率,同时随机采样打破了数据间的相关性,与目标q网络的结合进一步稳定了动作值函数的训练过程[6]。但dqn使用的经验回放技术没有考虑历史数据的重要程度,而是同等频率的回放。文献[7]提出一种带优先级经验回放的dqn,对经验进行优先次序的处理,增加重要历史数据的回放频率来提高学习效果,同时也加快了学习进程。dqn并不擅长解决战略性深度强化学习任务,当存在延迟的奖赏而导致需要长时间步规划才能优化策略的情形中,dqn的表现就会急剧下降。文献[8]提出一种基于视觉注意力机制的深度循环q网络模型,使用双层门限循环单元构成的循环神经网络模块来记忆较长时间步内的历史信息,通过视觉注意力机制自适应地将注意力集中于面积较小但更具价值的图像区域,提升了模型在一些战略性任务上的性能表现和稳定性。dqn的另一个不足是训练时间长,agent学习策略速度慢,为此文献[9]针对训练dqn耗时大的问题,开发出一种大型的并发式架构(gorila),从而缩短网络的训练时间;文献[10]提出一种约束优化算法来保证策略最优和奖赏信号快速传播,该算法极大提高了agent学习到最优策略的速度。dqn还有一个不足是游戏得分低,为此文献[11]提出将蒙特卡罗树搜索与dqn结合,实现了atari游戏的实时处理,游戏得分也普遍高于原始dqn;作为dqn的一种变体,分类dqn算法从分布式的角度分析深度强化学习[12],它将奖赏看作一个近似分布,并且使用贝尔曼等式学习这个近似分布,在atari视频游戏上的平均表现要优于原始dqn。
虽然目前dqn算法在大部分atari视频游戏上达到了人类玩家的控制效果,在接近于真实场景的各类任务上表现出了强大的适用性,但是dqn算法仍然存在游戏得分低,学习策略速度慢的问题。
技术实现要素:
本发明为了解决利用dqn进行视频游戏模拟存在学习策略速度慢、游戏得分低等问题,进而提出一种基于改进dqn的视频游戏模拟方法。
本发明为解决上述技术问题采取的技术方案是:
一种基于改进dqn的视频游戏模拟方法,所述方法的实现过程为:
步骤一、dqn算法中激活函数的改进
结合relu激活函数和softplus激活函数构造一个非饱和修正线性激活函数用于dqn算法,改进的激活函数记为relu-softplus;
步骤二、gabor滤波器的改进
对传统的gabor滤波器式(5)引入曲度系数c,并对其中的y'进行耦合,改进后的gabor滤波器x’和y’坐标为:
式中,c为表征图像弯曲程度的曲度系数;改进后的gabor滤波器x’和y’坐标代入公式(5)得到改进后的gabor滤波器;
传统的gabor滤波器的复数表达形式如式(5)所示:
传统的gabor滤波器中x’和y’定义为:
式中,σ为gabor函数的尺度参数,表示gabor函数在x轴和y轴上的标准差;u=1/σ;θ为滤波器提取特征的方向,不一样的θ取值表示提取的是数据不同方向上的特征;x,y表示视频游戏图像的像素点在x轴和y轴上对应坐标;
步骤三、实现视频游戏模拟,其过程:
1)将连续k帧游戏图像和改进后的gabor滤波器做卷积,得到不同θ取值下的多个特征图x1,x2,x3,……,xm;
2)将得到的m个特征图x1,x2,x3,……,xm进行特征融合,得到特征图xn;
3)将特征图xn和dqn算法中原有的若干个可训练学习的滤波器进行卷积,通过relu激活函数映射得到dqn的卷积层c1的特征集xp;
4)将卷积得到的特征集xp采用均值采样的方式进行抽样,通过relu激活函数映射得到卷积层c2的特征集xq;
5)将特征集xq以全连接的方式输出,通过改进的relu-softplus激活函数映射得到样本的实际输出q值,然后根据当前模型的最优方案选择一个动作a;
6)将经验数据(s,a,r,s’)放入历史经验队列并随后从历史经验队列中采样出mini-batch大小的经验样本,s表示视频游戏的当前状态,a表示在当前状态下选择的动作,r表示在当前状态下选择一个动作得到的奖励,s’表示在当前状态s下选择一个动作a后转移到的下一个状态;
7)将采样出的经验样本转化为dqn训练的元组,利用最小平方误差代价函数计算实际q值和目标q值之间的差异,通过反向传播算法自顶向下传递残差,利用权值更新公式更新权值得到训练模型,实现视频游戏模拟。
在步一骤中,在数据小于等于0时使用softplus激活函数;在数据大于0时使用relu激活函数,并将其函数图像向上平移ln2个单位大小,改进的激活函数记为relu-softplus,如式(4):
式中,x为用于表示视频游戏图像的矩阵,激活函数f(x)表示对视频游戏图像进行非线性映射。
在步二骤中,曲度系数c的取值为0至1之间。
在步骤三中,选择四个方向梯度,分别为0°、45°、90°和135°。
特征融合是对m个特征图x1,x2,x3,……,xm取均值。
本发明的有益效果是:
本发明对dqn算法进行改进,设计一个新的激活函数,并用一个改进的gabor滤波器代替dqn网络中初始的可学习的滤波器,利用强化学习的q-learning算法来训练更新网络权重,得到训练模型,实现视频游戏模拟。
本发明首先对激活函数进行了改进,结合relu和softplus两种激活函数的优点,设计并构造一种分段激活函数。其次设计改进的gabor滤波器,用其代替卷积神经网络中原有的可训练的滤波器。算法中将视频游戏的一帧帧图像和改进后的gabor滤波器卷积得到多个不同方向的特征,然后将这些特征进行特征融合,用融合后的特征取代原始视频游戏图像作为卷积神经网络的输入,利用强化学习的q-learning算法训练更新网络权重,得到训练模型,实现视频游戏的模拟。实验研究表明,改进的dqn算法在视频游戏模拟中游戏得分更高,且能更快地学习到策略。
附图说明
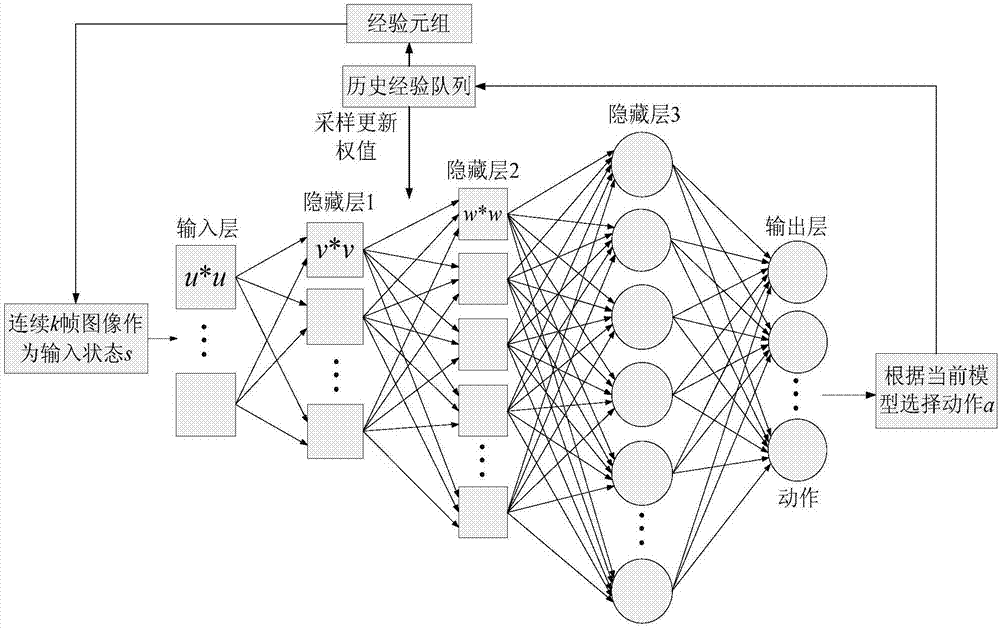
图1是深度q网络(dqn)的结构图;图2是改进的激活函数;图3为基于改进dqn的视频游戏模拟方法的流程框图;图4是为了比较改进前后gabor滤波器特征提取能力选择的圆形和椭圆(圆形和椭圆作为gabor滤波器的输入,左边为圆形,右边为椭圆);图5为未改进的gabor滤波器提取圆形和椭圆的特征效果图(左边为圆形,右边为椭圆);图6改进后的gabor滤波器提取圆形和椭圆的特征效果图(左边为圆形,右边为椭圆);
图7为视频游戏截图,其中,a表示flappybird游戏截图,b表示breakout游戏截图;
图8为breakout在不同激活函数下的得分图;
图9为breakout在改进gabor滤波器下的得分图;
图10为breakout在改进激活函数和改进gabor滤波器(c=0.1)下的得分图;
图11为flappybird在不同激活函数下的得分图;
图12为flappybird在改进gabor滤波器下的得分图;
图13为flappybird在改进激活函数和改进gabor滤波器(c=0.05)下的得分图。
具体实施方式
结合图1至图3说明书本实施方式,本实施方式所述的一种基于改进dqn的视频游戏模拟方法的实现过程为:
1、dqn算法
由于卷积神经网络对图像处理拥有天然的优势,将卷积神经网络与强化学习结合处理图像数据的感知决策任务成了很多学者的研究方向。dqn算法是深度强化学习领域的开创性工作,它采用时间上相邻的k帧游戏画面作为原始图像输入,经过深度卷积神经网络和全连接神经网络,输出状态动作q函数,实现了端到端的学习控制。
dqn使用带有参数θ的q函数q(s,a;θ)去逼近值函数。迭代次数为i时,损失函数为
li(θi)=e(s,a,r,s')[(yidqn-q(s,a;θi))2](1)
其中
式中,e表示求参数的数学期望,s表示状态state,a表示动作action,r表示在状态s选择动作a获得的立即奖励reward,s’表示在状态s选择动作a后进入到的下一个状态,γ表示折扣因子,θi表示学习过程中的网络参数。经过一段时间的学习后,更新新的θ-。具体的学习过程根据:
式中,
本发明使用的dqn的网络结构如图1所示:
2、dqn算法中激活函数的改进
2.1激活函数的作用
激活函数是指如何把“激活的神经元特征”通过非线性函数保留并映射出来,这就是神经网络能解决非线性问题的关键所在。使用激活函数增加了神经网络模型的非线性,使得深度神经网络真正具有了意义。同时传统的激活函数会把输入值归约到一个区间内,因为当激活函数的输出值有限时,基于梯度的优化方法会更加稳定。
2.2改进的激活函数
relu相比传统的s型激活,具有更快的随机梯度下降收敛速度和稀疏性。虽然softplus相比sigmoid和tanh收敛更快,效果更好,但是它不具备很好的稀疏性,同时比relu收敛要慢。所以结合relu和softplus的优点,构造一个新的非饱和修正线性激活函数用于深度神经网络。在数据小于0时使用softplus函数,在数据大于0时使用relu函数,并将其函数图像向上平移ln2个单位大小。改进的激活函数记为relu-softplus,如式(4):
改进的激活函数图像如图2所示。改进的激活函数不仅保留了relu激活函数快速收敛的好处,还修正了数据的分布,使得一些负轴的值得以保存不至于全部丢掉,relu容易“死掉”的问题也可得到较好的解决。
3gabor滤波器的改进
3.1传统的gabor滤波器
gabor小波和人体大脑皮层的神经元响应是一样的,gabor小波对图像的局部区域尤其是图像边缘十分敏感,因此它能够很好地对图像的局部特征进行提取。gabor滤波器在具有良好的方向特性的同时还具有良好的尺度特性。
常用二维gabor滤波器的复数表达形式如式(5)所示:
其中x’和y’定义为:
式中,σ为gabor函数的尺度参数,表示gabor函数在x轴和y轴上的标准差;u=1/σ;θ为滤波器提取特征的方向,不一样的θ取值表示提取的是数据不同方向上的特征。
用gabor滤波器的实部进行滤波会使图像变得更加平滑,而用gabor滤波器的虚部进行滤波可以检测到图像的边缘特征。
3.2改进的gabor滤波器
通常情况下,传统卷积神经网络不对输入图像做处理直接将其传入到网络中训练,符合“像素本身是图像语音最冗余的表示”观点,然而通过不断的研究发现对输入数据进行适当的预处理可以针对性的获取原始图像有用的信息,去除冗余的数据。由于传统的gabor滤波器对曲线不具有很好的特征提取能力,因此对传统的gabor滤波器加以改进,引入曲度系数的概念,使滤波器在具有基本的方向和尺度特性的同时兼具好的局部曲率响应特性,可以针对性地提取原始图像更加准确地特征,然后将输入图像和改进后的gabor滤波器卷积得到的多个不同方向特征取代原始图像作为卷积神经网络的输入。新的gabor滤波器改进后的x’和y’坐标为:
式中,c为表征图像弯曲程度的参数。
4视频游戏模拟算法及流程
基于改进dqn的视频游戏模拟算法流程框图如图3所示,具体步骤为:
1)将最近连续k帧游戏图像和改进后的gabor滤波器做卷积,求得0°、45°、90°和135°方向梯度的四组特征x1,x2,x3和x4;
2)将得到的四个方向特征图x1,x2,x3和x4进行特征融合,得到特征图x5;
3)将特征图x5和若干个可训练学习的滤波器进行卷积,通过relu激活函数映射得到卷积层c1的特征集x6;
4)将卷积得到的特征集x6采用均值采样的方式进行抽样,通过relu激活函数映射得到卷积层c2的特征集x7;
5)将特征集x7以全连接的方式输出,通过改进的relu-softplus激活函数映射得到样本的实际输出q值,然后根据当前模型的最优方案选择一个动作a;
6)将经验数据(s,a,r,s’)放入历史经验队列并随后从历史经验队列中采样出mini-batch大小的经验样本。
7)将采样出的样本转化为网络训练的元组,利用最小平方误差代价函数计算实际q值和目标q值之间的差异,通过反向传播算法自顶向下传递残差,从而利用权值更新公式更新权值得到训练模型,实现视频游戏模拟。
针对本发明方法进行如下实验仿真:
实验一:gabor滤波器特征提取能力实验
为了比较改进前后gabor滤波器特征提取能力,本发明选择了圆形和椭圆进行实验,如图4所示。图5和图6分别给出了未改进的和改进后的gabor滤波器提取圆形和椭圆的特征效果图,可以明显看出改进后的gabor滤波器对圆形和椭圆弯曲部分的特征提取能力更强。
实验二:视频游戏模拟实验
利用改进的dqn算法对两个游戏进行实验,分别是飞扬的小鸟(flappybird)和打砖块(breakout),如图7所示。实验使用最近连续4帧游戏图像作为输入,第一个隐藏层由32个8*8的卷积核组成,步长为4,使用relu激活函数做非线性变换,经过卷积核的变换后该层有20*20*32个节点;第二个隐藏层包含48个4*4的卷积核,步长为2,使用relu激活函数做非线性变换,经过卷积核的变换后该层有9*9*48个节点;最后一个隐藏层包含512个与上一层进行全连接的节点,全连接层使用relu-softplus激活函数做非线性变换。
1)breakout
用改进的dqn算法训练迭代了游戏180次,观察整个训练过程的游戏得分,breakout在改进的dqn算法下的得分如图8、图9、图10所示。
从图8可以看出,在训练过程中,breakout在改进的激活函数(relu-softplus)的dqn算法下的平均得分是3.16,高于目前常用的其他激活函数;对于改进gabor滤波器的dqn算法,不同的曲度系数取值模型效果不一样,本发明随机选择了4个曲度系数值0、0.05、0.1、0.2,从图9可以看出,当曲度系数c=0.1时模型平均得分是5.71,高于其他的c取值。从图10可以看出,breakout在改进激活函数和改进gabor滤波器的dqn算法下的下的平均得分是7.1,高于未改进的dqn算法。
2)flappybird
用改进的dqn算法训练迭代650000次,得到训练模型,然后在该模型下进行测试50次,得到该游戏的50个得分,将这些得分5个一组求其平均值得到游戏的10组得分,最后将这10组得分按升序排列。flappybird在改进的dqn算法下的得分如图11、图12、图13所示。
从图11可以看出,flappybird在改进的激活函数(relu-softplus)的dqn算法下的平均得分是63.64,高于目前常用的其他激活函数;对于改进gabor滤波器的dqn算法,不同的曲度系数取值模型效果不一样,本发明随机选择了4个曲度系数值0、0.05、0.1、0.2,从图12可以看出,当曲度系数c=0.05时模型平均得分是87.72,高于其他的c取值;从图13可以看出,flappybird在改进激活函数和改进gabor滤波器的dqn算法下的下的平均得分是100.4,高于未改进的dqn算法。
实验结果表明,改进的dqn算法在视频游戏上的平均得分要高于未改进的dqn算法,游戏agent能更快学习到最优策略,这样使得游戏agent更加智能化,既增加了游戏的可玩性,也增加了游戏的挑战性。
5总结
1)提出了dqn算法中激活函数和gabor滤波器的改进方案,以及一种基于改进dqn的视频游戏模拟算法。算法结合relu和softplus的优点,构造一个新的非饱和修正线性激活函数;对传统的gabor滤波器加以改进,引入曲度系数的概念,使滤波器在具有基本的方向和尺度特性的同时兼具好的局部曲率响应特性。
2)经breakout和flappybird游戏实验验证,breakout在改进的dqn算法中的平均得分是7.1,在未改进的dqn算法中的平均得分是2.96;flappybird在改进的dqn算法中的平均得分是100.4,在未改进的dqn算法中的平均得分是38.8,可见改进的dqn算法相比未改进的游戏得分有较大提高,游戏agent能更快学习到最优策略,验证了所提方法的有效性。
3)将改进的dqn算法应用到视频游戏,游戏得分高可提高视频游戏agent的游戏水平,实现人与游戏agent之间更加真实的交互,极大地增强了游戏的操控性。
本发明中引用的参考文献如下:
[1]mnihv,kavukcuogluk,silverd,etal.human-levelcontrolthroughdeepreinforcementlearning[j].nature,2015,518(7540):529–533.
[2]silverd,huanga,maddisonc,etal.masteringthegameofgowithdeepneuralnetworksandtreesearch[j].nature,2016,529(7587):484–489.
[3]赵星宇,丁世飞.深度强化学习研究综述[j].计算机科学,2018,45(07):1-6.
[4]linlj.reinforcementlearningforrobotsusingneuralnetworks[d].pittsburgh:carnegiemellonuniversity,1993.
[5]赵冬斌,邵坤,朱圆恒,等.深度强化学习综述:兼论计算机围棋的发展[j].控制理论与应用,2016,33(6):701-717.
[6]唐振韬,邵坤,赵冬斌,等.深度强化学习进展:从alphago到alphagozero[j].控制理论与应用,2017,34(12).
[7]schault,quanj,antonogloui,etal.prioritizedexperiencereplay[j].computerscience,2015.
[8]刘全,翟建伟,钟珊,等.一种基于视觉注意力机制的深度循环q网络模型[j].计算机学报,2017,40(6):1353-1366.
[9]naira,srinivasanp,blackwells,etal.massivelyparallelmethodsfordeepreinforcementlearning[c]//proceedingsoftheicmlworkshopondeeplearning.lille:acm,2015.
[10]hefs,liuy,schwingag,etal.learningtoplayinaday:fasterdeepreinforcementlearningbyoptimalitytightening[c]//proceedingsoftheinternationalconferenceonlearningrepresentations(iclr).toulon:acm,ieee,2017.
[11]guox,singhs,leeh,etal.deeplearningforreal-timeatarigameplayusingofflinemonte-carlotreesearchplanning[c]//advancesinneuralinformationprocessingsystems.montreal:mitpress,2014:3338–3346.
[12]bellemaremg,dabneyw,munosr.adistributionalperspectiveonreinforcementlearning[c]//proceedingsofthe34thinternationalconferenceonmachinelearning(icml).sydney:[s.n.],2017:449–458.
- 还没有人留言评论。精彩留言会获得点赞!