一种基于双语义空间的对抗性跨媒体检索方法与流程
本发明涉及模式识别、自然语言处理、多媒体检索等技术领域,尤其涉及一种基于双语义空间的对抗性跨媒体检索方法,主要应用公共空间的特征映射来消除语义鸿沟,将不同模态的数据进行匹配达到检索的目的,并在跨媒体检索经典数据库中验证本方法的有效性。
背景技术:
近年来,互联网技术飞速发展,随之而来的是多媒体信息的爆炸式增长,用户更倾向于通过检索获得多媒体信息结果,比如,用户输入关键字“狮子”,期望得到相关文字介绍以及其他模态的相关信息,比如狮子的图像,狮子的吼声以及狮子相关的视频等等。如此看来,传统的检索技术以经不能满足用户对于检索结果多样性、全面性的要求。跨媒体检索由于可以实现不同媒体间的灵活检索得到了广泛关注。其面临的挑战主要是不同模态的异构性和不可比性,以及不同模态所携带信息类型的不平衡性。比如,图片中包含更多的空间位置以及层次信息而文本中则包含着更多的上下文和背景信息。
现有方法大多将异构的特征映射到一个单一的同构空间,以消除“语义鸿沟”,但是,这样的处理同时伴随着大量的信息丢失,不同模态的特有信息不能得以保留,难以有效实现跨媒体检索。
技术实现要素:
本发明提供了一种基于双语义空间的对抗性跨媒体检索方法,通过建立文本子空间和图像子空间,分别保留不同模态内部特征,并通过对抗训练来挖掘多媒体数据中丰富的语义信息,从而实现有效的跨媒体检索。
本发明的技术方案是:
一种基于双语义空间的对抗性跨媒体检索方法,通过建立文本子空间和图像子空间,分别保留不同模态内部特征,并通过对抗训练来挖掘多媒体数据中丰富的语义信息,从而实现有效的跨媒体检索;包括:特征生成过程、双语义空间的构建过程和对抗性语义空间优化过程。
1)特征生成过程;
具体实施时,分别获取nus-wide-10k和wikipedia两个数据集的训练数据,验证数据及测试数据。并利用深度卷积神经网络cnn(convolutionalneuralnetwork)对训练及测试图像提取视觉特征向量,利用bow(bagofwords)模型对训练和测试文本提取“bow文本特征向量”;设有n组训练数据,将图像和文本数据分别送入cnn网络和bow模型,提取到的特征分别表示为图像特征i={i1,i2,…,in}和文本特征t={t1,t2,…,tn};
2)双语义空间的构建过程,包括图像子空间和文本子空间;
本发明构建了双语义空间,即图像子空间和文本子空间。
21)在图像子空间中,分别用三层的全连接网络实现对文本特征的映射以及图像特征在原有维度上的调整,同时引入三元组损失(tripletloss)进行同构空间特征优化,实现在最大限度保留图像信息的同时消除“语义鸿沟”。
具体执行如下操作:
211)在图像子空间中,图像特征i经过三层全连接网络在原有维度(4096维)上调整特征分布,为之后的图文匹配做准备,网络最后一层使用relu激活函数。同时引入一个相似的三层全连接网络将文本特征t映射到图像空间当中,尽量多的保留原有图像特征。
212)在同构图像子空间中定义三元组
其中,fv(i)与ft(t)分别为图像与文本的映射函数,
以空间中的图像为参照,引入三元组约束(tripletconstraint)调整文本分布,即拉近相同语义的文本图像对
其中,α为表示安全系数的超参数;
22)相似的,在文本子空间中实现图像特征映射以及文本特征调整。
具体执行如下操作:
221)在文本子空间中,文本特征t利用文本映射函数ψt(t)在原文本特征空间进行分布调整,图像映射函数ψv(i)将图像特征i映射到文本空间当中,实现文本子空间内不同模态特征同构,同时避免大量损失原有文本信息。两个映射函数均为使用relu激活函数的3层全连接网络。
222)文本子空间的三元组损失
其中,α为表示安全系数的超参数,与式2中相同。φt表示文本子空间内的三元组
223)两个语义子空间平行工作,实现特征提取的互补与平衡。
将双子空间的三元组损失适应性融合,得到最终不同模态在同构空间新的特征分布,表达式如式4,其中ηv、ηt为超参数:
3)对抗性语义空间优化过程
本发明引入对抗性学习优化双语义空间,在保证类别不变的前提下拟合不同模态的空间分布,同时保证模态可判别,上述结果反向传输更新双语义空间,通过衡量空间距离完成“图像检索文本(img2text)”和“文本检索图像(text2img)”的跨媒体检索任务。
执行如下操作:
31)采用类别预测(conceptprediction)方法,设定包含图像子空间和文本子空间的类别恒定目标函数,分别对图像子空间和文本子空间进行优化,使得子空间内不同模态特征映射或调整前后类别不变;
以图像子空间为例,优化目标是最小化数据类别真实分布与同构空间内向量的类别预测分布间的误差,其表达式如下:
式中,n是一次迭代中数据的数目,ci为数据类别真实分布,pc(fv(i))、pc(ft(t))分别为同构图像子空间内图像向量与文本向量的类别预测概率;
文本子空间内目标函数
pc(ψv(i))与pc(ψt(t))分别为同构文本子空间内图像向量与文本向量的类别预测概率;
类别恒定目标函数整体可表示为式7:
32)利用对抗性学习模型更新优化双空间网络参数,其中将步骤212)、221)中的同构空间特征表示fv(v)、ft(t)、ψv(i)与ψt(t)作为对抗性学习模型的生成器生成向量,生成器的优化目标为在保证类别恒定的前提下使得图像和文本在双子空间内的分布尽量相似,优化函数表达式为式8:
lg=μc·lc+μtri·ltri(式8)
其中,μc、μtri为超参数。
对抗性学习模型的判别器的目标是尽量准确地判断出不同模态数据在双子空间内的向量是来自图像还是文本。具体实施时,本发明使用3层前向传播全连接网络进行模态判别。
以图像子空间为例,其优化目标是使得数据模态真实分布mi与模态预测概率分布误差最小化,其表达式为式9:
其中,n是一次迭代中数据的数目,mi为数据真实模态,d(fv(i))与d(ft(t))为同构图像子空间内图像与文本向量的模态预测。
文本子空间内目标函数
d(ψv(i))与d(ψt(t))分别为同构文本子空间内图像与文本向量的模态预测。
判别器在双子空间内的目标函数整体可以表示为式11:
生成器与判别器的目标函数交替训练,得到最优化的两个同构语义空间。
利用优化的同构双语义空间,通过衡量空间距离完成“图像检索文本(img2text)”和“文本检索图像(text2img)”,即可实现基于双语义空间的对抗性跨媒体的检索。
与现有技术相比,本发明的有益效果是:
本发明提供了一种基于双语义空间的对抗性跨媒体检索方法,其技术优势体现在:
(一)通过建立文本子空间和图像子空间,分别保留不同模态内部特征。在图像子空间中,分别用三层的全连接网络实现对文本特征的映射以及图像特征在原有维度上的调整,同时引入三元组损失进行同构空间特征优化,实现在最大限度保留图像信息的同时消除“语义鸿沟”。相似的,在文本子空间中实现图像特征映射以及文本特征调整。两个语义子空间平行工作,实现特征提取的互补与平衡。
(二)通过对抗训练来挖掘多媒体数据中丰富的语义信息,通过衡量空间距离完成“图像检索文本(img2text)”和“文本检索图像(text2img)”的跨媒体检索任务实现有效的跨媒体检索。
附图说明
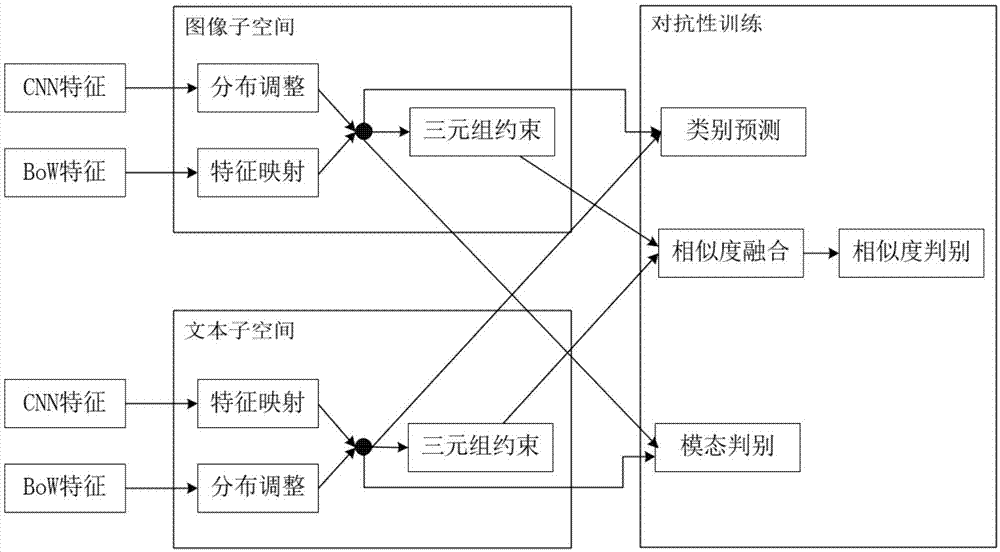
图1是本发明提供方法的整体流程框图。
图2是本发明实施例中进行同构空间特征优化的示意图;
其中,(a)是图像子空间内三元组分布优化;(b)是文本子空间内三元组分布优化。
图3是本发明实施例进行文本检索图像的结果示例图,
其中,第一列为检索用文本,第二列为数据集给定的匹配图像,列3至列7为map值前五的对应检索结果。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供了一种基于双语义空间的对抗性跨媒体检索方法,通过建立文本子空间和图像子空间,分别保留不同模态内部特征,并通过对抗训练来挖掘多媒体数据中丰富的语义信息,从而实现有效的跨媒体检索。
本发明提供的方法包括:特征生成过程、双语义空间的构建过程和对抗性语义空间优化过程;图1所示是本发明提供方法的流程,具体步骤如下:
1)假设有n组训练数据,将图像和文本数据分别送入cnn网络和bow模型,提取到的特征分别表示为图像特征i={i1,i2,…,in}和文本特征t={t1,t2,…,tn},
2)在图像子空间中,图像特征i经过三层全连接网络在原有维度(4096维)上调整特征分布,为之后的图文匹配做准备,网络最后一层使用relu激活函数。同时引入一个相似的三层全连接网络将文本特征t映射到图像空间当中,尽量多的保留原有图像特征。
3)在同构图像子空间中定义三元组
其中fv(i)与ft(t)分别为图像与文本的映射函数,
以空间中的图像为参照,引入三元组约束(tripletconstraint)调整文本分布,即拉近相同语义的文本图像对
其中α为表示安全系数的超参数。
4)在文本子空间中,文本特征t经过文本映射函数ψt(t)在同原本文本维度空间特征分布调整,图像映射函数ψv(i)将图像特征i映射到文本空间当中,实现文本子空间内不同模态特征同构,同时避免大量损失原有文本信息。二者均为使用relu激活函数的3层全连接网络。与图像子空间类似,文本子空间的三元组损失可以表示为:
其中α为表示安全系数的超参数。φ表示文本子空间内的三元组
5)将双子空间的三元组损失适应性融合,得到最终不同模态在同构空间新的特征分布,表达式如下,其中η为超参数:
6)引入类别预测(conceptprediction),保证子空间内不同模态特征映射或调整前后类别不变,以图像空间为例,优化目标是最小化数据类别真实分布ci与同构空间内向量的类别预测概率分布pc(fv(t))、pc(ft(t))间的误差,其表达式如下:
n是一次迭代中数据的数目,ci为数据类别真实分布,pc(fv(i))、pc(ft(t))分别为同构图像子空间内图像向量与文本向量的类别预测概率。
文本子空间内目标函数
7)对抗性学习模型更新优化双空间网络参数,其中步骤3)、4)中的同构空间特征表示fv(v)、ft(t)、ψv(i)与ψt(t)为对抗性学习模型中生成器生成向量,生成器的优化目标为在保证类别恒定的前提下使得图像和文本在双子空间内的分布尽量相似,优化函数表达式为:
lg=μc·lc+μtri·ltri
其中μc、μtri为超参数。
判别器的目标是尽量准确地判断出不同模态数据在双子空间内的向量是来自图像还是文本。本发明使用3层前向传播全连接网络进行模态判别。以图像子空间为例,其优化目标是使得数据模态真实分布与模态预测概率分布误差最小化,其表达式为:
其中,n是一次迭代中数据的数目,mi为数据真实模态,d(fv(i))与d(ft(t))为同构图像子空间内图像与文本向量的模态预测。
文本子空间内目标函数
8)生成器与判别器的目标函数交替训练,得到最优化的两个同构语义空间。利用优化的同构双语义空间,即可实现基于双语义空间的对抗性跨媒体的检索。
图3是本发明实施例中进行同构空间特征优化的示意图;其中,(a)是图像子空间内三元组分布优化;(b)是文本子空间内三元组分布优化。
表1给出了采用本发明提供的跨媒体检索方法及现有方法[1]-[6]在nus-wide-10k和wikipedia两个数据集进行检索得到的检索结果以得到的检索结果的对比。
表1nus-wide-10k和wikipedia数据集在不同方法上的检索结果
其中,现有方法[1]-[6]分别为:
文献[1](rasiwasia,n.,pereira,j.c.,coviello,e.,doyle,g.,lanckriet,g.r.g.,levy,r.,vasconcelos,n.:anewapproachtocross-modalmultimediaretrieval.in:internationalconferenceonmultimedia.pp.251–260(2010))记载的cca方法;
文献[2](srivastava,n.,salakhutdinov,r.:learningrepresentationsformultimodaldatawithdeepbeliefnets.in:icmlworkshop)记载的multimodaldbn方法;
文献[3](feng,f.,wang,x.,li,r.:cross-modalretrievalwithcorrespondenceautoencoderpp.7–16(2014))记载的corr-ae方法;
文献([4]zhai,x.,peng,y.,xiao,j.:learningcross-mediajointrepresentationwithsparseandsemisupervisedregularization.ieeetransactionsoncircuitsandsystemsforvideotechnology24(6),965–978(2014))记载的jrl方法;
文献([5]wang,b.,yang,y.,xu,x.,hanjalic,a.,shen,h.t.:adversarialcross-modalretrieval.in:acmonmultimediaconference.pp.154–162(2017))记载的acmr方法;
文献([6]peng,y.,qi,j.,yuan,y.:modality-specificcross-modalsimilaritymeasurementwithrecurrentattentionnetwork(2017))记载的mcsm方法。
表2给出了本发明提供的跨媒体检索方法及本发明两个变体(仅有图像空间和仅有文本空间)对nus-wide-10k和wikipedia两个数据集进行检索,得到的检索结果的对比。
表2nus-wide-10k和wikipedia数据集在图像空间、文本空间和双语义空间的检索结果
表1和表2中,检索结果用map值衡量,map值越高,检索效果越优异。
从表1中可以看出,与现有方法比较,本发明在图像检索文本和文本检索图像两大任务上检索正确率均有明显提升,表2结果显示,虽然nus-wide-10k数据集上的检索结果显示,在图像检索文本任务上双语义空间的map值稍低于仅在文本空间的结果,但双空间的平均检索结果在两个数据集上均明显高于单空间,充分验证了本发明中所提出的的双语义空间检索结构的有效性。图3是本发明实施例进行文本检索图像的结果示例图。图中,第一列为检索用文本,第二列为数据集给定的匹配图像,列3至列7为map值前五的对应检索结果,显示了本发明用于检索的有效性。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!