一种服务器集群资源调度方法与流程
本发明涉及基于群进化算法,对服务器集群进行资源调度的方法。
背景技术:
近年来,一些大型互联网公司的服务器数据响应量,存储量呈几何级数增长,传统的单个或多个服务器响应方式已无法满足业务需求,主要表现在以下几个方面:
(1)访问量大:以web服务器为例,大型网站的日访问量可达千万级,并发量可达到十万级,需求响应交互方式和长线程持有服务器资源,在这种应用场景下分别在响应速度和存储容量对服务器系统产生很大的冲击,单个服务器很难满足业务需求。
(2)数据量大:以游戏服务器为例,大型网络游戏为防止客户端数据修改,一般采用服务器端数据验证,在多名玩家同时协作游戏时(如晚上下班后的8:00-10:00pm集中刷副本),多名玩家客户端上传的数据量短时间内达到峰值,整个游戏系统效率变低,游戏体验下降,表现为服务器响应速度变慢,客户端卡顿掉帧,网络交互丢包。
(3)服务器的负载能力差异较大:大型互联网公司的服务器往往不是一批采购的,新旧、性能高低差异较大的服务器共同提供服务的现象较为普遍,由单个服务器分别提供服务会导致系统的响应速度不一致。
服务器集群为解决以上的几个问题提供了方案,即将多个服务器集中起来提供同一类服务。从客户端看,集群就像单个服务器。集群利用多个计算机进行并行计算,从而获得很快的计算速度,也可以用于多个计算机做备份,使得任何一个机器坏了的情况下,整个系统还可以正常运行。
在此基础上,如何调度集群资源使得服务器性能最优,已成为困扰集群使用者的新问题。其中,进程是操作系统分配资源的最小单元,因此,服务器集群的资源调度问题,本质上在于如何分配多个服务器上的cpu、存储空间和网络流量,使得多个进程的响应速度、效率、存储空间在一定的规划时间内取得最大值。
目前,常用的提供服务器集群资源调度服务的操作系统包括windowsserver,linux,unix等,服务器容器有tomcat,weblogic,jboss等,开源软件有lvs、nginx、haproxy等,该几种产品能够提供多种服务器资源的调度服务。
服务器集群资源的调度方法从原理上可以分为以下几种:
(1)静态资源调度:包括轮询(roundpick)和随机(random)的方法。其中,轮询包括传统轮询、加权轮询、动态轮询。传统轮询是把来自用户的请求轮流分配给内部的服务器,从第一个服务器一直轮询到第n个服务器,然后重新循环;加权轮询是根据服务器的不同处理能力,给每个服务器分配不同的权值;动态轮询是根据当前服务器的运行状态,动态分配每个服务器的权值。随机是指通过随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问,由概率统计理论可以得知,随着客户端调用服务端的次数增多,实际的效果就越来越接近于平均分配调用量到后端的每一台服务器。
(2)动态资源调度:包括最快算法和最少连接法。其中,最快算法是基于所有服务器中的最快响应时间分配连接;最少连接是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器,来处理当前的请求,尽可能的提高后端服务的利用效率,合理的分流到每一台服务器上。
现有的调度方法在处理数量较小的时候效果比较明显,在处理大数据量的时候效果显著下降。
技术实现要素:
鉴于现有技术中存在的问题,本发明旨在提供一种针对大数据量的服务器集群资源的调度方法,其应用场景和静态、动态资源调度的实现方法完全不同,本发明的调度方法是基于粒子群算法(pso)提出的,能够很好的解决大数据量资源的调度问题。
1、一种服务器集群资源调度方法,所述服务器集群包括n台服务器,每台所述服务器均包括:cpu(ca)、内存(mb)、硬盘(hc)、网络流量(id),m个进程需要分配资源,每个进程为pi(0<i<m),其特征在于,所述调度方法为:
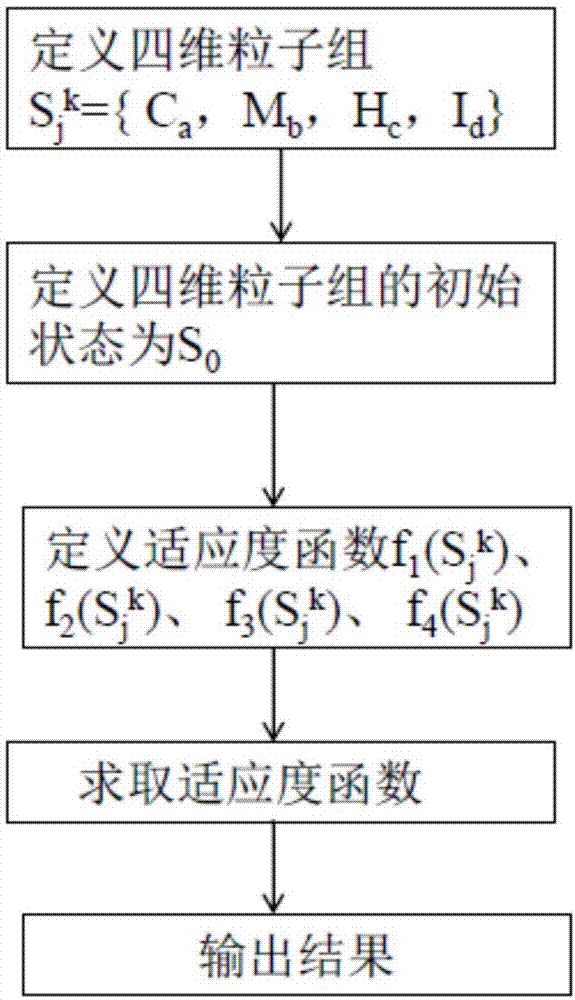
a、定义四维粒子组sjk={ca,mb,hc,id}(0<j<e),其中,
j为循环次数,e为循环总次数,k为粒子在所述四维粒子组内的id,每个所述四维粒子组包含g个粒子(0<k<g),并且,每个所述四维粒子组表示一次循环j的输入数据;
b、定义所述四维粒子组的初始状态为s0,初始化粒子群算法的参数为:惯性权重w,局部搜索随机系数c1,全局搜索随机系数c2;所述一次循环j的最优解为局部最优解pjlocal,全局最优解为pjglobal,所述局部最优解和所述全局最优解的初始值均为+∞;
c、定义适应度函数,其中,
在第j次循环sjk中,第k个服务器的响应时间为tjk,负载率为ljk;
适应度函数f1(sjk)为:系统平均响应时间
适应度函数f2(sjk)为:系统最大响应时间
适应度函数f3(sjk)为:系统平均负载率
适应度函数f4(sjk)为:系统最大负载率
d、求取所述适应度函数f1(sjk)、f2(sjk)、f3(sjk)、f4(sjk),每次所述循环之后更新所述四维粒子组sjk的位置和速度;其中,0<j<e-1,0<k<g-1;
f、输出结果。
作为本发明优选的实施方式,利用随机算法定义所述四维粒子组的初始状态。
进一步地,pjlocal>f1(sjk)时,pjlocal=f1(sjk);pjglobal>f1(sjk)时,pjglobal=f1(sjk)。
进一步地,pjlocal>f2(sjk)时,pjlocal=f2(sjk);pjglobal>f2(sjk)时,pjglobal=f2(sjk)。
进一步地,pjlocal>f3(sjk)时,pjlocal=f3(sjk);pjglobal>f3(sjk)时,pjglobal=f3(sjk)。
进一步地,pjlocal>f4(sjk)时,pjlocal=f4(sjk);pjglobal>f4(sjk)时,pjglobal=f4(sjk)。
进一步地,从所述服务器集群中获取数据计算得到所述适应度函数f1(sjk)、f2(sjk)、f3(sjk)、f4(sjk)。
作为本发明优选的实施方式,所述四维粒子组sjk的位置更新方程为:
当计算不同的所述适应度函数时,所述位置更新方程中的f1(sjk)对应替换为f2(sjk)或f3(sjk)或f4(sjk)。
作为本发明优选的实施方式,所述四维粒子组sjk的速度更新方程为:
作为本发明优选的实施方式,在步骤d中,所述速度越界时,随机产生一个速度。
现有技术中,针对服务器集群资源调度的方法主要为静态资源调度方法和动态资源调度方法,但是都不适用于大数据量的资源调度场景,而本发明基于粒子群算法提出的服务器集群资源的调度方法,能够很好的解决大数据量资源的调度问题,响应速度快,服务器集群内负载较为均衡。
附图说明
图1为本发明提供的一种服务器集群资源调度方法的流程示意图。
图2为本发明实施例提供的方法与其他方法相比的cpu占有率的变化趋势。
具体实施方式
以下结合附图和实施例,对本发明的具体实施方式进行更加详细的说明,以便能够更好地理解本发明的方案以及其各个方面的优点。然而,以下描述的具体实施方式和实施例仅是说明的目的,而不是对本发明的限制。
本发明提出的服务器集群资源调度方法,是基于粒子群算法(pso)进行的。具体的:
本发明的服务器集群中包括n台服务器,每台服务器均包括如下资源:cpu(ca)、内存(mb)、硬盘(hc)、网络流量(id)。在调度过程中,有m个进行需要分配资源,每个进程表示为pi(0<i<m)。
本发明中,服务器集群中,服务器的性能以系统平均响应时间tavg、最大响应时间tmax、平均负载率lavg、最大负载率lmax表示。
如图1所示,本发明的方法通过以下步骤实现:
a、定义四维粒子组sjk={ca,mb,hc,id}(0<j<e),其中,j为循环次数,e为循环总次数,k为粒子在所述四维粒子组内的id。每个四维粒子组sjk包含g个粒子(0<k<g),并且,每个四维粒子组sjk代表一次循环j的输入数据,即代表g个粒子的状态。每次循环的过程中计算g个粒子的适应度。
例如,一个粒子s03代表id为3的服务器的第0轮循环(即循环开始时)的资源状态。本发明的四维粒子组的每一维代表一种资源,例如维度ca代表cpu。为了能够清楚简要的描述本发明的技术方案,以下仅以计算cpu资源作为示例,其它资源:内存(mb)、硬盘(hc)、网络流量(id)的计算方法与cpu资源的计算方法类似。
b、通过随机算法或者系统资源状态定义四维粒子组的初始状态为s0。初始化粒子群算法的参数为:惯性权重w,局部搜索随机系数c1,全局搜索随机系数c2。其中,随机系数由随机算法产生。
本发明中,定义一次循环j的最优解为局部最优解pjlocal,全局最优解为pjglobal。并且,局部最优解和全局最优解的初始值均为+∞;
c、在第j次循环sjk中,第k个服务器的响应时间为tjk,负载率为ljk。四维粒子组的适应度计算公式如下:
1、适应度函数f1(sjk)为:系统平均响应时间
2、适应度函数f2(sjk)为:系统最大响应时间
3、适应度函数f3(sjk)为:系统平均负载率
4、适应度函数f4(sjk)为:系统最大负载率
进一步地,上述各适应度函数也可以从服务器集群的多个服务器中获取数据进行直接计算,而不使用本发明的方法进行计算。
d、j的循环为:0至(e-1),k的循环为:0至(g-1)。
求取适应度函数f1(sjk)、f2(sjk)、f3(sjk)、f4(sjk)。
以下以f1(sjk)作为示例:
如果pjlocal>f1(sjk),pjlocal=f1(sjk);
如果pjglobal>f1(sjk),pjglobal=f1(sjk)。
进一步地,如果pjlocal>f2(sjk),pjlocal=f2(sjk);
如果pjglobal>f2(sjk),pjglobal=f2(sjk)。
进一步地,如果pjlocal>f3(sjk),pjlocal=f3(sjk);
如果pjglobal>f3(sjk),pjglobal=f3(sjk)。
进一步地,如果pjlocal>f4(sjk),pjlocal=f4(sjk);
如果pjglobal>f4(sjk),pjglobal=f4(sjk)。
每次循环之后更新四维粒子组sjk的位置和速度。
其中,四维粒子组sjk的位置更新方程为:
当计算不同的适应度函数时,位置更新方程中的f1(sjk)对应替换为f2(sjk)或f3(sjk)或f4(sjk)。
四维粒子组sjk的速度更新方程为:
f、如果速度越界,会随机产生一个速度。
g、输出结果。
实施例
本实施例中,假设服务器集群内的服务器性能一致,并严格控制单一变量。
本实施例的服务器集群共有64台服务器,每台服务器有2个cpu,每个cpu有16个核心,每个核心以顺序执行程序指令不可再划分。每台服务器内存为128gb,硬盘为4tb。集群以100mb/s的传输速度与网络交互,4台服务器通过一个交换机组网。初始状态所有服务器均有2个长进程,分别在有1个cpu的8个核心,负载率为50%。假设此情况下的系统响应速度为0.1s,每多占用1个核心系统响应速度变慢0.1s。
本实施例的系统中,需要处理2000个并发请求,每个请求生成一个进程。
图2中示出了分别采用本发明的方法、轮询方法、随机方法进行服务器集群资源调度时,cpu占有率的变化趋势。由图1可以看出,本发明的方法(pso)和传统方法相比,本发明方法的cpu占有率与传统算法的cpu占有率相比,本发明的方法中,cpu占有率上升相对较快,并且收敛较早,说明服务器集群对请求的响应快,且服务器集群内的负载较为均衡。
最后应说明的是:显然,上述实施例仅仅是为清楚地说明本发明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!