一种基于候选标记估计的未标记数据利用方法与流程
本发明涉及未标记数据利用方法,属于弱监督信息下多分类任务技术领域,具体涉及一种基于候选标记估计的未标记数据利用方法。
背景技术:
互联网技术的蓬勃发展引领世界走向一个数据爆炸的时代,若能获取足量已标记数据,基于传统监督学习方法即可使学习系统获得极优的泛化性能。然而由于现实世界中待标注数据的规模与标注工作所涉及的领域知识难度大,例如,人脸识别需要百万级数据以提升系统性能,医学图像标注工作需要医者丰富的领域知识,现实任务中获取大量已标记样本往往十分困难,而未标记数据相对容易获取。因此如何有效利用未标记数据提升学习系统的泛化性能具有重要研究意义。
现实世界中,未标记数据由于没有显示的标注信息而难以有效利用,实际上,未标记数据是已标记数据的同源数据集,它与已标记数据联系密切且同样包含表示数据分布的重要信息。目前已有的未标记数据利用方法多借助于半监督学习技术,比如半监督支持向量机,其基本思想是找到能使两类样本分开并且穿过数据低密度区域的划分超平面;或者基于图的半监督学习方法与协同训练方法等等,这些方法中对未标记数据没有进行有效利用。
技术实现要素:
发明目的:针对现有技术的不足,本发明提出一种基于候选标记估计的未标记数据利用方法,从构造未标记样本的候选标记集合出发,提出一种求解半监督学习问题的新思路,能够实现对未标记数据的有效利用。
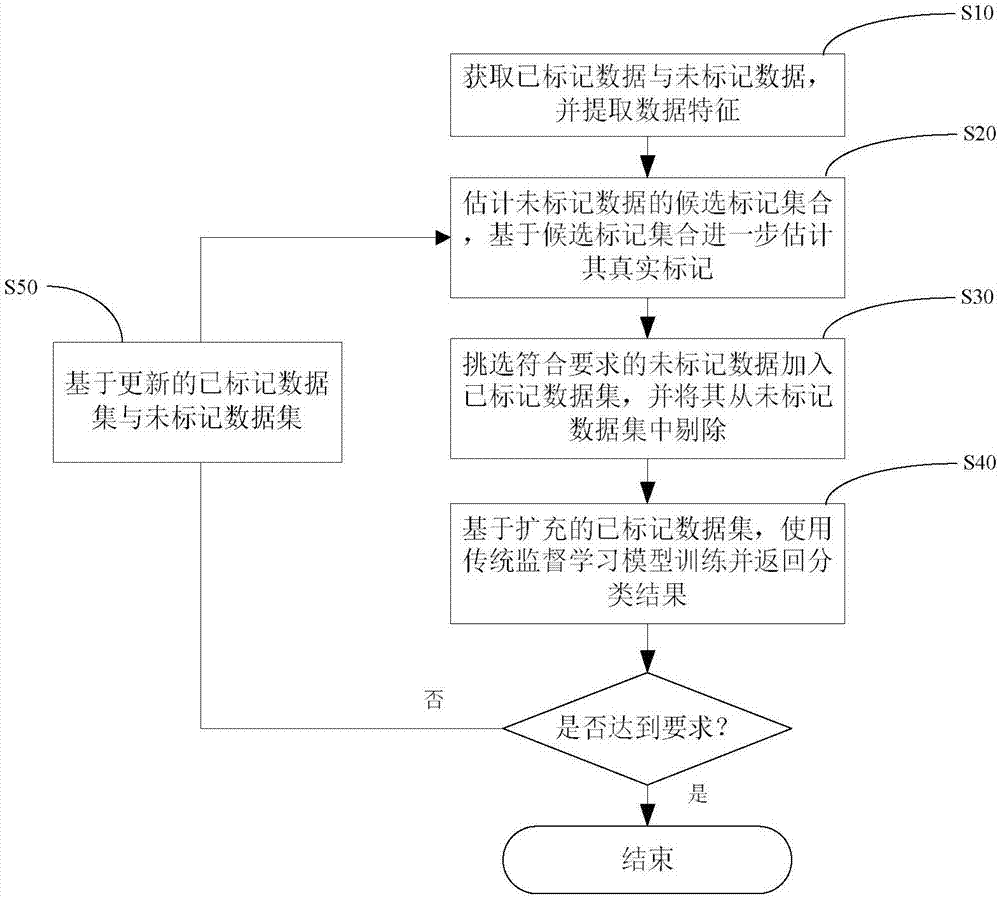
技术方案:本发明所述的一种基于候选标记估计的未标记数据利用方法,该方法包括以下步骤:s10、就特定分类任务从现实世界分类任务中获取已标记数据与未标记数据,并提取数据特征;s20、根据数据特征估计未标记数据的候选标记集合,基于候选标记集合进一步估计其真实标记;s30、从估计的真实标记中挑选符合要求的相应未标记数据加入已标记数据集,并将其从未标记数据集中剔除;s40、基于扩充的已标记数据集,使用传统监督学习模型训练并返回分类结果;s50、如果分类结果不满足要求,则基于步骤s30中更新的已标记数据集与未标记数据集,重新执行步骤s20-s40。
其中,所述步骤s10中,用户选取的分类数据集为d=dl∪du,其中dl={(xi,yi)|1≤i≤l}表示已标记数据集,l为已标记的样本个数,yi∈{y1,y2,…,yq}为样本xi所对应的类别标记,q为标记类别数;du={(xj|l+1≤j≤l+u}表示未标记样本集,其中u为未标记的样本个数,记l+u=m且l<<u。
所述步骤s20包括以下步骤:
s21、构建(l+u)×q维的二值非负标记矩阵,表示数据集对应的候选标记集合,其中第j行表示xj对应的候选标记集合;
s22、使用基于实例的方法并进行迭代的标记传播,基于候选标记集合进一步估计未标记数据的真实标记。
优选地,所述步骤s21包括以下步骤:
s2101、执行候选标记集合初始化操作,对于已标记样本xi∈dl,其候选标记集合即为其真实标记,而对于未标记样本xj∈du,其候选标记集合先初始化为0,对于候选标记集合s的第i行、第k列元素sik,其具体初始化过程如公式(1):
其中yi表示xi的真实标记,k表示标记空间的第k个类别,yi=k表示yi对应于标记空间的第k个类别;
s2102、将未标记样本编号j作为变量设为1;
s2103、判断j的值是否小于等于u,若是,则进入步骤s2104,否则该候选标记估计过程结束;
s2104、在已标记数据集中查找未标记样本xj的k近邻样本,并将其在数据集中索引表示为集合
其中,σ>0是用户设定的带宽参数,exp表示以e为底的对数,
s2105、基于相似的样例具有相似的标记这一假设,根据上步得到的特征空间的关系向量wj,将特征空间的关系扩展到标记空间,以此构造xj的候选标记集合,具体如公式(3):
其中
s2106、将未标记样本xj对应的候选标记集合规范化为二值向量,具体如公式(4):
sj+l,n表示未标记样本xj的候选标记集合sj+l的第n个维度的值;
s2107、变量j自增1,并返回步骤s2103处继续向下执行,直到遍历完整个未标记数据集。
所述步骤s22包括以下步骤:
s2201、将整个数据集中样本编号f作为变量设为1;
s2202、判断f的值是否小于等于m,若是,则进入步骤s2203,否则进入步骤s2205;
s2203、在整个数据集中查找xf的k近邻样本,并将其数据集中的索引表示为
wr,f表示xf与其第r个近邻xr之间的权重,通过优化公式(5)得到;
s2204、变量f自增1,并返回步骤s2202处继续进行判断;
s2205、得到整个数据集的权重矩阵w={w1;w2;…;wm},其中每一行是一个k维向量;
s2206、基于权重矩阵w,在整个数据集上执行标记传播过程直至收敛;
s2207、估计每个样本的真实标记及其对应的置信度。
优选地,步骤s2206中执行标记传播的具体过程如下:
首先按照初始化一个m×q维的置信度矩阵p(0)=[plc]m×q,其中每一行表示一个q维向量pl=[pl1,pl2,…,plq],plc对应于p的第l行第c列,表示数据集中第l个样本被预测为第c类的置信度,其计算公式如下:
接着按照如下公式迭代更新矩阵p直至p不再改变:
其中t表示更新的轮次,
有益效果:
1、本发明首次提出候选标记集合的概念,通过利用未标记数据与已标记数据之间的相似性,借助少量已标记样本估计未标记样本的候选标记集合,然后基于候选标记集合挖掘出未标记数据中的潜在信息,进一步估计得到其真实标记,增强已标记数据集,从而实现对未标记数据的有效利用。
2、本发明扩充了已标记数据集合,使用传统监督学习模型进行训练和分类,传统监督学习是目前研究最成熟的一种机器学习方法,相比于半监督学习的有限监督信息,由于其监督信息具有单一、明确的特点,在处理精度以及处理效率上均有显著优势。
附图说明
图1是未标记数据利用方法的流程图;
图2是未标记数据的估计方法流程图;
图3是候选标记估计的流程图;
图4是二次真实标记估计的流程图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明。
如图1所示,一种基于候选标记估计的未标记数据利用方法,包括以下步骤:s10、就特定分类任务从现实世界分类任务中获取已标记数据与未标记数据,并提取数据特征;s20、根据数据特征估计未标记数据的候选标记集合,基于候选标记集合进一步估计其真实标记;s30、从估计的真实标记中挑选符合要求的未标记数据加入已标记数据集,并将其从未标记数据集中剔除;s40、基于扩充的已标记数据集,使用传统监督学习模型训练并返回分类结果;s50、如果分类结果未到达要求,则基于步骤s30更新的已标记数据集与未标记数据集,重新执行步骤s20-s40。
在一个实施例中,步骤s10中,获取已标记数据与未标记数据可从特定分类任务领域数据库中获取。特定分类任务领域数据库的硬件载体可以是任意类型的存储设备,其中存放的是待分类的数据,且已使用特征提取方法提取出相应特征表示,这里的特定分类任务可以是字符识别、物体定位、图像识别等任务。实施例中的数据来源是uci机器学习数据库与手写字符识别mnist数据集,都是现成数据集的原始特征,如字符识别数据集mnist中,它包含70000张手写数字的灰度图片,其中每一张图片包含28x28个像素点。每一个实例可以用一个784维的向量来表示。uci数据库是加州大学欧文分校(universityofcaliforniairvine)提出的用于机器学习的数据库,uci数据集是一个常用的标准测试数据集,其数据特征多是具有具体物理含义的。在其他实施例中,用户可以根据数据来源使用相应的特征提取方法处理特征。用户从该数据库中获取少量已标记数据和大量未标记数据。假设用户选取的分类数据集为d=dl∪du,其中dl={(xi,yi)|1≤i≤l}表示已标记数据集,l为已标记的样本个数,yi∈{y1,y2,…,yq}为样本xi所对应的类别标记,q为标记类别数;du={(xj|l+1≤j≤l+u}表示未标记样本集,其中u为未标记的样本个数,记l+u=m且l<<u。
为了能够更准确地挖掘未标记数据中有效信息,本发明的方法先估计未标记样本的候选标记集合,此时假设其真实标记隐藏在候选标记集合中,再进一步由其候选标记集合估计其真实标记,以实现对未标记数据的有效利用。图2示出了步骤s20所述的估计方法,在步骤s21中,基于步骤s10得到的数据集,构建(l+u)×q维的二值非负标记矩阵,表示数据集对应的候选标记集合,其中第j行表示xj对应的候选标记集合。然后在步骤s22中,基于s21得到的候选标记集合,使用基于实例的方法并进行迭代的标记传播,进一步估计未标记数据的真实标记。这里的实例表示instance,具体来说,基于实例的方法是对于每个未见样本xf,在数据集中寻找与该样本距离最近的k个样本,此处的距离度量函数采用欧氏距离,然后利用近邻与xf之间的关系推导得到其语义表示。
参照图3,示出了步骤s21所述的候选标记集合的估计过程。在步骤s2101处,执行候选标记集合初始化操作,对于已标记样本xi∈dl,其候选标记集合即为其真实标记,而对于未标记样本xj∈du,其候选标记集合先初始化为0,对于候选标记集合s的第i行、第k列元素sik,其具体初始化过程如公式(1):
其中yi表示xi的真实标记,k表示标记空间的第k个类别,yi=k表示yi对应于标记空间的第k个类别。
接着步骤s2102至s2107构成了一个循环体,循环的每一轮中估计第j个未标记样本xj的候选标记集合。
在步骤s2102处,将未标记样本编号j作为变量设为1,并在步骤s2103处判断j的值是否小于等于u,若是,表明未标记样本还没有估计完,则进入步骤s2104,否则该候选标记估计过程结束。
在步骤s2104处,在已标记数据集中查找未标记样本xj的k近邻样本,并将其在数据集中索引表示为集合
其中,σ>0是用户设定的带宽参数,exp表示以e为底的对数,
在步骤s2105处,基于相似的样例具有相似的标记这一假设,根据上步得到的特征空间的关系向量wj,将特征空间的关系扩展到标记空间,以此构造xj的候选标记集合,具体如公式(3):
其中
在步骤s2106处,将未标记样本xj对应的候选标记集合规范化为二值向量,具体如公式(4):
sj+l,n表示未标记样本xj的候选标记集合sj+l的第n个维度的值,对sj+l的每一维度的值,首先将其取值除以sj+l各个维度的值之和,若规范化后的比重大于等于
在步骤s2107处,进行下一个未标记样本的处理,即变量j自增1,并返回步骤s2103处继续向下执行,直到遍历完整个未标记数据集。
图4给出了图2中步骤s220的详细描述,使用基于实例的方法并进行迭代的标记传播,基于候选标记集合进一步估计未标记数据的真实标记,展示了二次估计真实标记的过程。其中步骤s2201至s2204构成了一个循环体,循环的每一轮中构造第f个样本xf与其k近邻样本的权重向量wf。注意这里f遍历的范围是整个数据集,包括已标记数据和未标记数据。具体来说,在步骤s2201处,将整个数据集中样本编号f作为变量设为1,并在步骤s2202处判断f的值是否小于等于m,若是,表明尚未估计完整个数据集,则进入步骤s2203,否则进入步骤s2205。在步骤s2203处,在整个数据集中查找xf的k近邻样本,并将其数据集中的索引表示为
wr,f表示xf与其第r个近邻xr之间的权重,通过优化公式(5)得到。
在步骤s2204处,变量f自增1,并返回步骤s2202处继续进行判断;
遍历整个数据集,在步骤s2205处,得到整个数据集的权重矩阵w={w1;w2;…;wm},其中每一行是一个k维向量,用于刻画该样本与其在整个数据集中的k个近邻之间的特征相似性。
在步骤s2206处,基于上步构造的权重矩阵w,在整个数据集上执行标记传播过程直至收敛。具体执行标记传播的过程如下:
首先按照初始化一个m×q维的置信度矩阵p(0)=[pfc]m×q,其中每一行表示一个q维向量pf=[pf1,pf2,…,pfq],pfc对应于p的第f行第c列,表示数据集中第f个样本被预测为第c类的置信度,其计算公式如下:
|sl|表示整个数据集中元素的个数。
接着按照如下公式迭代更新矩阵p直至p不再改变。
其中t表示更新的轮次,第t轮p(t)是由前一轮次p(t-1)和首轮p(0)继承而来。
在这个过程中,标记传播体现在,经过t轮迭代,未标记样本的标记可由已标记样本得到,形象化来讲就是标记从已标记样本到未标记样本的传播扩散过程。
在步骤s2207处,估计每个样本的真实标记及其对应的置信度。每个样本的真实标记估计为置信度矩阵p中最大置信度所对应的类别,置信度p由步骤s2206的标记传播过程得到。
步骤s30中,挑选符合要求的未标记数据加入已标记数据集,并将其从未标记数据集中剔除,实施例中挑选高质量未标记数据,其中高质量指的是置信度大于90%。
步骤s40中,使用传统监督学习模型训练并返回分类结果,实施例中使用的是支持向量机模型进行模型训练,在其他实施例中支持向量机模型可以替换为神经网络模型、贝叶斯模型等多分类模型。这些方法已比较成熟,此处不再赘述。
步骤s50中,如果分类结果未到达要求,具体体现在其误差率大于基于已标记样本的误差率或者小于预设的轮次t,则基于步骤s30更新的已标记数据集与未标记数据集,重新执行步骤s20-s40。
- 还没有人留言评论。精彩留言会获得点赞!