基于自编码对抗生成网络的零样本学习方法与流程
本发明涉及一种零样本学习方法。特别是涉及一种基于自编码对抗生成网络的零样本学习方法。
背景技术:
深度学习技术的进步极大地促进了机器学习和计算机视觉领域的发展。然而这些技术大都局限于监督学习,即需要大量的标注样本训练模型。在现实中,样本标注是一件极其费力的工作。因此标注样本的缺失问题是影响当前机器学习发展的瓶颈之一,需要一种在完全缺失目标类别的视觉标注数据情况下仍然能够识别这些类别的技术,零样本学习正是这样的一类技术。
零样本学习是利用可见类别的数据,辅以一定的先验知识,对未见类别(无训练数据的类别)进行识别的技术。因此,零样本学习是解决样本缺失的一种有效手段。
当前实现零样本学习的基本思路是利用可见类别(有标注数据的训练类别)的样本数据以及样本对应的类别语义特征训练模型,并利用训练模型实现未见类别(没有标注数据的测试类别)样本的分类。当前针对如何训练样本数据和类别语义之间语义关系的模型主要分为两类:一类是基于判别的模型,另一类是基于生成的模型。基于判别的模型将零样本学习看作是一种特殊的多模态学习任务。具体为,样本数据的特征和类别语义特征是分布在不同模态空间中,判别模型的任务是学习一种模型将不同模态的特征映射到同一空间,以实现不同模态之间语义相似度的度量。尽管基于判别模型的方法在零样本学习中取得了较好的效果,但这类方法容易产生域偏移问题,即利用可见类别训练的模型容易在测试类别上发生偏移。近年来,为了解决零样本学习中未见类别样本缺失的问题,研究者们提出利用生成模型合成未见类别数据特征的方法。这类方法的基本思路是利用类别的语义特征或者利用由类别的语义特征及噪声组成的联合特征作为输入学习一个能够减小生成数据和真实数据分布之间差异的模型。然而这类模型大部分只关注类别语义到视觉特征之间的语义对齐关系而忽视了视觉特征到类别语义之间的关系,这弱化了不同模态之间的对齐关系。
技术实现要素:
本发明所要解决的技术问题是,提供一种有效地合成未见类别的样本特征,同时有效地建立不同模态之间的语义交互关系的基于自编码对抗生成网络的零样本学习方法。
本发明所采用的技术方案是:一种基于自编码对抗生成网络的零样本学习方法,包括如下步骤:
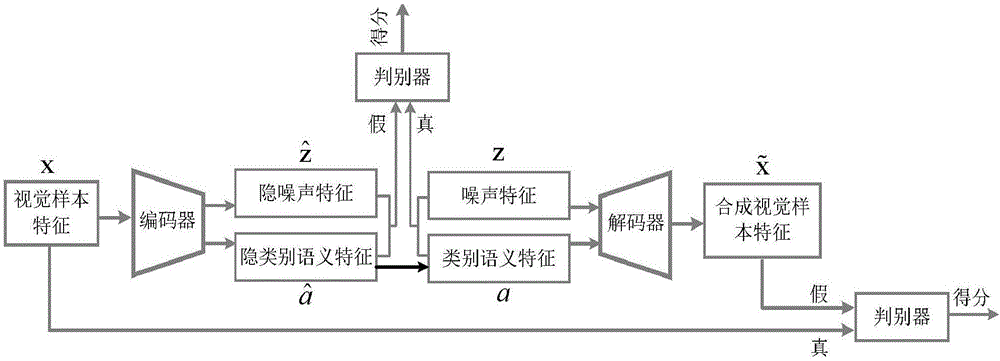
1)将可见类别样本的视觉特征x输入到编码器中,在样本对应的类别语义特征a的监督下得到隐类别语义特征
2)将样本对应的类别语义特征a和真实的噪声特征z输入到解码器中,在样本的真实视觉特征的监督下得到合成的样本视觉特征
3)将由隐类别语义特征
4)将样本的视觉特征x作为真数据,合成的视觉特征
5)根据步骤1)和步骤2)建立自编码器的目标函数:
其中e,g分别是编码器,解码器;w,v分别是编码器和解码器对应的参数,
6)根据步骤3)建立类别语义判别器的目标函数:
其中d为语义判别器模型,
7)根据步骤4)建立视觉判别器的目标函数:
其中d′表示视觉判别器模型,u表示视觉判别器的参数,所述目标函数的最后一项是lipschitz约束,α是lipschitz约束的平衡参数;
8)给定正则项的平衡参数λ和lipschitz约束的平衡参数α的具体值,利用adam优化器对模型参数进行优化,得到模型参数的最优值;
9)输入未见类别的语义特征at,利用已训练好的模型参数合成对应类别的视觉特征;
10)对未见类别的测试样本进行分类。
步骤1)中所述的编码器结构为:全连接层—隐藏层—全连接层。
步骤2)中所述的解码器结构为:全连接层—隐藏层—全连接层。
步骤8)中所述的正则项的平衡参数λ和lipschitz约束的平衡参数α的选择范围为:[0.01,0.001,0.0001]。
步骤10)是根据分类器的不同,有不同的分类方案,若利用无参数的最近邻分类器,那么测试样本的分类是利用测试样本的视觉特征和未见类别的合成视觉特征之间的相似度实现;若利用有参数的分类器,那么测试样本的分类是利用训练合成的未见类别的视觉特征实现。
本发明的基于自编码对抗生成网络的零样本学习方法,具有以下优点:
1)能够有效地对齐视觉模态和类别语义模态之间的语义关系。本发明不仅考虑了类别语义特征到样本视觉特征的语义对齐,并且考虑了样本视觉特征到类别语义特征的对齐关系,这种双向的语义对齐能够约束合成的视觉特征能够有效地重构语义特征,包含更多的语义信息。
2)能够合成更符合真实数据分布的视觉特征。本发明包含两个对抗网络,一个类别语义对抗网络,另一个是视觉对抗网络。对于编码器:其输入是真实的视觉特征,是输入视觉对抗网络的真数据,而其输出是类别语义对抗网络的假数据;对于解码器,其输入是类别语义对抗网络的真数据,而其输出是视觉对抗网络的假数据。这两个对抗网络将视觉信息和类别语义信息充分的交融在一起,能够更有效地挖掘两种模态之间的语义关联,合成更有效地视觉特征。
附图说明
图1是本发明自编码对抗生成网络的整体流程示意图;
图2是本发明自编码对抗生成方法用于零样本学习的流程图。
具体实施方式
下面结合实施例和附图对本发明的基于自编码对抗生成网络的零样本学习方法做出详细说明。
本发明的基于自编码对抗生成网络的零样本学习方法,利用可见类别的视觉样本数据以及对应的类别语义特征训练一种基于自编码器框架下的对抗生成网络,其结构图如图1所示。方法包括如下步骤:
1)将可见类别样本的视觉特征x输入到编码器中,在样本对应的类别语义特征a的监督下得到隐类别语义特征
2)将样本对应的类别语义特征a和真实的噪声特征z输入到解码器中,在样本的真实视觉特征的监督下得到合成的样本视觉特征
3)将由隐类别语义特征
4)将样本的视觉特征x作为真数据,合成的视觉特征
5)根据步骤1)和步骤2)建立自编码器的目标函数:
其中e,g分别是编码器,解码器;w,v分别是编码器和解码器对应的参数,
6)根据步骤3)建立类别语义判别器的目标函数:
其中d为语义判别器模型,
7)根据步骤4)建立视觉判别器的目标函数:
其中d′表示视觉判别器模型,u表示视觉判别器的参数,所述目标函数的最后一项是lipschitz约束,α是lipschitz约束的平衡参数;
8)给定正则项的平衡参数λ和lipschitz约束的平衡参数α的具体值,所述的正则项的平衡参数λ和lipschitz约束的平衡参数α的选择范围为:[0.01,0.001,0.0001]。利用adam优化器对模型参数进行优化,得到模型参数的最优值。
9)输入未见类别的语义特征at,利用已训练好的模型参数合成对应类别的视觉特征;
10)对未见类别的测试样本进行分类。本发明根据分类器的不同,有不同的分类方案,若利用无参数的最近邻分类器,那么测试样本的分类是利用测试样本的视觉特征和未见类别的合成视觉特征之间的相似度实现;若利用有参数的分类器,如支持向量机,softmax等,那么测试样本的分类是利用训练合成的未见类别的视觉特征实现。
将本发明的基于自编码对抗生成网络的零样本学习方法应用到零样本具体任务中的流程如图2所示,包括如下步骤:
1)输入可见类别样本的视觉特征,以及对应的类别语义特征;
2)输入具体的平衡参数λ及α的数值;
3)设定参数的初始值,学习率,利用adam优化器训练本发明所提出的自编码对抗生成网络,得到编码器和解码器的模型参数;
4)输入未见类别的语义特征,利用已训练好的模型参数合成对应类别的视觉特征;
5)对未见类别的测试样本进行分类。
- 还没有人留言评论。精彩留言会获得点赞!