一种基于改进朴素贝叶斯的涉密文本识别方法与流程
本发明涉及涉密文本识别,特别是涉及一种基于改进朴素贝叶斯的涉密文本识别方法。
背景技术:
随着信息技术的发展,能够实现大量的综合办公、科研生产业务的信息系统逐渐出现在社会生活和工作中,信息系统中存储着大量的敏感数据和信息。如何防止涉密信息通过互联网泄露到外界,是当前迫切希望解决的问题。
涉密文本的自动检测是解决上述问题的有效技术手段。根据bell_lapadula模型,当前的涉密信息一般分为公开、秘密、机密和绝密四个等级。当涉密文本在网络上的进行交换流转时(例如公文、电子邮件等),该技术能够有效检测出该文本所属的密级。当检测出该文本的密级后,再与用户自己标定的密级标签进行对比,就能发现该涉密文本的信息流转是否合法。举例来说,如果用户将该文本信息标注为“公开”,而自动检测算法检测出的密级是“机密”,那么即可判定该行为属于不合法。
朴素贝叶斯(
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于改进朴素贝叶斯的涉密文本识别方法。
本发明的目的是通过以下技术方案来实现的:一种基于改进朴素贝叶斯的涉密文本识别方法,其特征在于:包括以下步骤:
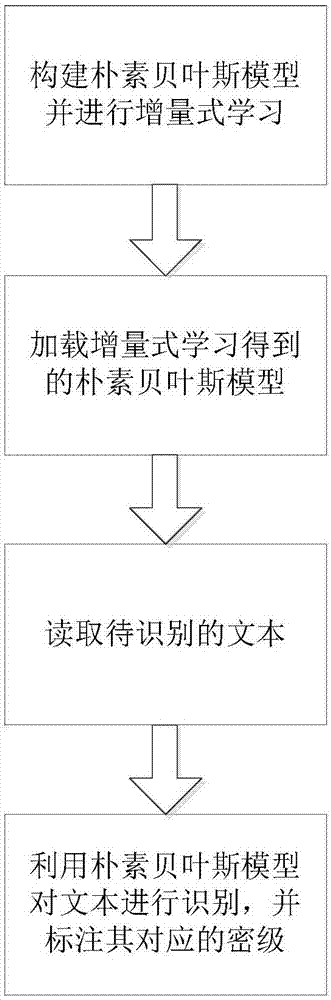
s1.构建朴素贝叶斯模型并进行增量式学习;
s2.加载增量式学习得到的朴素贝叶斯模型;
s3.读取待识别的文本;
s4.利用朴素贝叶斯模型对文本进行识别,并标注其对应的密级。
进一步地,所述涉密文本识别方法还包括识别结果上传步骤:将步骤s4的识别结果上传到统一的控制中心。
进一步地,所述步骤s1包括以下子步骤:
s101.构建朴素贝叶斯模型对带有用户标注标签的样本进行识别;
s102.统一控制中心管理员将识别出的标签与用户标注的标签进行对比,如果是识别错误的,就将该样本及其正确标签加入到样本库;
s103.构建朴素贝叶斯加权模型;
s104.涉密特征空间中有新的涉密特征加入或者有旧的涉密特征密级发生变化时,基于涉密特征空间改变的进行增量学习;
s105.根据样本库和涉密特征库的变化进行增量式学习;
s106.将学习后的模型写入到朴素贝叶斯模型中,并通知系统进行重新加载。
更近一步地,所述步骤s101包括:
第一、构建朴素贝叶斯模型:
设涉密文本的样本空间d由特征空间w={w1,w2,…,wn}和类别空间c={c1,c2,…,cm}组成;样本空间d即文本中包含的词,类别空间c即涉密文本的密级;对一个给定文本d={w1,w2,…,wl},朴素贝叶斯模型通过计算该文本属于各类别的后验概率,对其所属类别进行判别;哪个类别的后验概率大,该文本的检测结果就是对应的那个类别,判别式如下:
其中p(ci)表示类别的先验概率;p(wj|ci)表示在类别ci条件下,特征wj出现的概率:
其中|c|、|d|和|w|分别表示类别空间、样本空间和特征空间的大小;count(ci)表示属于类别ci的样本数,
第二、利用朴素贝叶斯模型对带有用户标注标签的样本进行识别,得到各个样本的识别结果。
所述步骤s103包括:
第一、构建朴素贝叶斯加权模型:
λj,i表示特征空间中第j个特征属于第i个类别的权重,按照bell_lapadula模型,每个特征都有4个权重,分别对应公开、秘密、机密和绝密:
其中tfi(wj)是文本特征wj在ci类别文本中出现的词频;idfi(wj)是改进的逆文档频率;文本特征在类内文档数越大,在其它类中出现的文档数越小,则其权重越大。
所述步骤s104包括:
涉密特征空间中有新的涉密特征加入或者有旧的涉密特征密级发生变化时,新特征加入的情况:首先从与新特征同类别的其它特征中选择p(tj|ci)值最大的特征,将其所有信息均拷贝给新特征,按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计;然后从与新特征不同类别的其它特征中选择p(tj|ci)值最小的特征,将其所有信息均拷贝给新特征,然后按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计;
对于旧特征涉密特征密级发生变化的情况同理,首先从与变化特征同类别的其它特征中选择p(tj|ci)值最大的特征,将其所有信息均拷贝给变换特征,按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计;然后从与变换特征不同类别的其它特征中选择p(tj|ci)值最小的特征,将其所有信息均拷贝给变换特征,然后按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计。
所述步骤s105包括:
特征权重在样本空间和特征空间两个维度实现增量学习:
其中tf′i(·)和count'(·)均表示在样本增量集上的统计结果;
基于特征权重的增量学习,得到p(ci)和p(wj|ci)的增量学习结果:
本发明的有益效果是:基于朴素贝叶斯加权模型使得学习更加合理,并提出了特征权重的增量学习方案,能够大幅提升涉密文本检测的准确率;基于涉密特征空间改变的进行增量学习,简单有效地解决了有新的涉密特征加入或者有旧的涉密特征的密级下降的问题。
附图说明
图1为本发明的方法流程图;
图2为朴素贝叶斯模型进行增量式学习的流程图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
如图1所示,一种基于改进朴素贝叶斯的涉密文本识别方法,包括以下步骤:
s1.构建朴素贝叶斯模型并进行增量式学习;
s2.加载增量式学习得到的朴素贝叶斯模型;
s3.读取待识别的文本;
s4.利用朴素贝叶斯模型对文本进行识别,并标注其对应的密级。
在本申请的实施例中,所述涉密文本识别方法还包括识别结果上传步骤:将步骤s4的识别结果上传到统一的控制中心。
如图2所述,所述步骤s1包括以下子步骤:
s101.构建朴素贝叶斯模型对带有用户标注标签的样本进行识别;
s102.统一控制中心管理员将识别出的标签与用户标注的标签进行对比,如果是识别错误的,就将该样本及其正确标签加入到样本库;
s103.构建朴素贝叶斯加权模型;
s104.涉密特征空间中有新的涉密特征加入或者有旧的涉密特征密级发生变化时,基于涉密特征空间改变的进行增量学习;
s105.根据样本库和涉密特征库的变化进行增量式学习;
s106.将学习后的模型写入到朴素贝叶斯模型中,并通知系统进行重新加载。
其中,所述步骤s101包括:
第一、构建朴素贝叶斯模型:
设涉密文本的样本空间d由特征空间w={w1,w2,…,wn}和类别空间c={c1,c2,…,cm}组成;样本空间d即文本中包含的词,类别空间c即涉密文本的密级;对一个给定文本d={w1,w2,…,wl},朴素贝叶斯模型通过计算该文本属于各类别的后验概率,对其所属类别进行判别;哪个类别的后验概率大,该文本的检测结果就是对应的那个类别,判别式如下:
其中p(ci)表示类别的先验概率;p(wj|ci)表示在类别ci条件下,特征wj出现的概率:
其中|c|、|d|和|w|分别表示类别空间、样本空间和特征空间的大小;count(ci)表示属于类别ci的样本数,
第二、利用朴素贝叶斯模型对带有用户标注标签的样本进行识别,得到各个样本的识别结果。
所述步骤s103包括:
第一、构建朴素贝叶斯加权模型:
λj,i表示特征空间中第j个特征属于第i个类别的权重,按照bell_lapadula模型,每个特征都有4个权重,分别对应公开、秘密、机密和绝密:
其中tfi(wj)是文本特征wj在ci类别文本中出现的词频;idfi(wj)是改进的逆文档频率;文本特征在类内文档数越大,在其它类中出现的文档数越小,则其权重越大。
涉密文本检测是一种非常特殊的应用场景,随时时间的迁移,某些此前没有的关键词可能会成为涉密特征;而有些此前涉密的特征,密级则会逐渐降低。因此,需要一种能够适应这种变化的学习算法。容易知道,一个新的涉密特征加入,一定是有指定的密级的(例如某次行动的代号)。换句话说,该文本特征属于该类别的置信度是很高的。一个旧的涉密特征的密级降低(例如从机密级降为秘密级)也是类似的。因此,本发明中提出一种非常简单的策略进行解决,具体地,所述步骤s104包括:
涉密特征空间中有新的涉密特征加入或者有旧的涉密特征密级发生变化时,新特征加入的情况:首先从与新特征同类别的其它特征中选择p(tj|ci)值最大的特征,将其所有信息均拷贝给新特征,按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计;然后从与新特征不同类别的其它特征中选择p(tj|ci)值最小的特征,将其所有信息均拷贝给新特征,然后按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计;
对于旧特征涉密特征密级发生变化的情况同理,首先从与变化特征同类别的其它特征中选择p(tj|ci)值最大的特征,将其所有信息均拷贝给变换特征,按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计;然后从与变换特征不同类别的其它特征中选择p(tj|ci)值最小的特征,将其所有信息均拷贝给变换特征,然后按照步骤s103对所有特征在该类别下的权重λj,i和条件概率p(wj|ci)进行重新估计。
所述步骤s105包括:
特征权重在样本空间和特征空间两个维度实现增量学习:
其中tf′i'(·)和count'(·)均表示在样本增量集上的统计结果;
基于特征权重的增量学习,得到p(ci)和p(wj|ci)的增量学习结果:
目前最常用的特征权重学习方法是tf-idf,但是,传统的tf-idf权重并没有考虑文本特征在不同类别间和同一类别内的分布情况。比如,某个涉密文本特征会在某个类别大量出现,而在其它类别很少出现,甚至不出现;或者该特征会在某个类别(如机密类)的少量文件中大量出现,而在同一类别的其它文本中不出现。而本发明中基于朴素贝叶斯加权模型,能够比较好地解决这一问题,使得朴素贝叶斯模型的学习更加合理,能够大幅提升涉密文本检测的准确率;同时本发明能够根据样本库和涉密特征库的变化,使特征权重在样本空间和特征空间两个维度实现增量学习;此外,本发明中基于涉密特征空间改变的进行增量学习,简单有效地解决了有新的涉密特征加入或者有旧的涉密特征的密级下降的问题。
以上所述是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应该看作是对其他实施例的排除,而可用于其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!