一种集成计算功能的存储管理系统控制方法与流程
本发明涉及分布式存储技术领域,尤其涉及一种集成计算功能的存储管理系统控制方法。
背景技术:
一直以来,传统存储盘单一作为数据存储介质,数据计算则通过系统处理器进行处理,两者分工协作看似协调,但随着人工智能等涉及大数据领域的兴起,单纯依靠系统处理器做计算已经不能满足日益增长的数据计算需求,在一套系统中同时挂载存储介质和计算介质不仅增加资金成本,也占用了过多的硬件结构空间,而且数据从flash传输到fpga外置ddr时需要从host端的ddr桥梁过度,即先把存储在flash上的数据取到hostddr,然后通过dma方式传输到fpga外置ddr,这中间的通信消耗也占据了带宽。
涉及的专业术语:
flash:flashmemory,一般简称为"flash",它属于内存器件的一种,是一种非易失性内存。
nandflash:flash存储器的一种,具有容量较大、改写速度快等优点,适用于大量数据的存储。
ddr:doubledatarat,双倍速率同步动态随机存储器。
dma:directmemoryaccess,直接内存存取。
pcie:peripheralcomponentinterconnectexpress,一种计算机内部设备之间互联的协议。
fpga:field-programmablegatearray,现场可编程门阵列。
技术实现要素:
本发明的目的在于提供一种集成计算功能的存储管理系统控制方法,以解决上述技术背景中提出的问题。
为实现上述目的,本发明采用以下技术方案:
本发明提供了一种集成计算功能的存储管理系统控制方法,包括一台服务器和至少一个集成了存储管理软件的加速存储单元,所述方法包括:
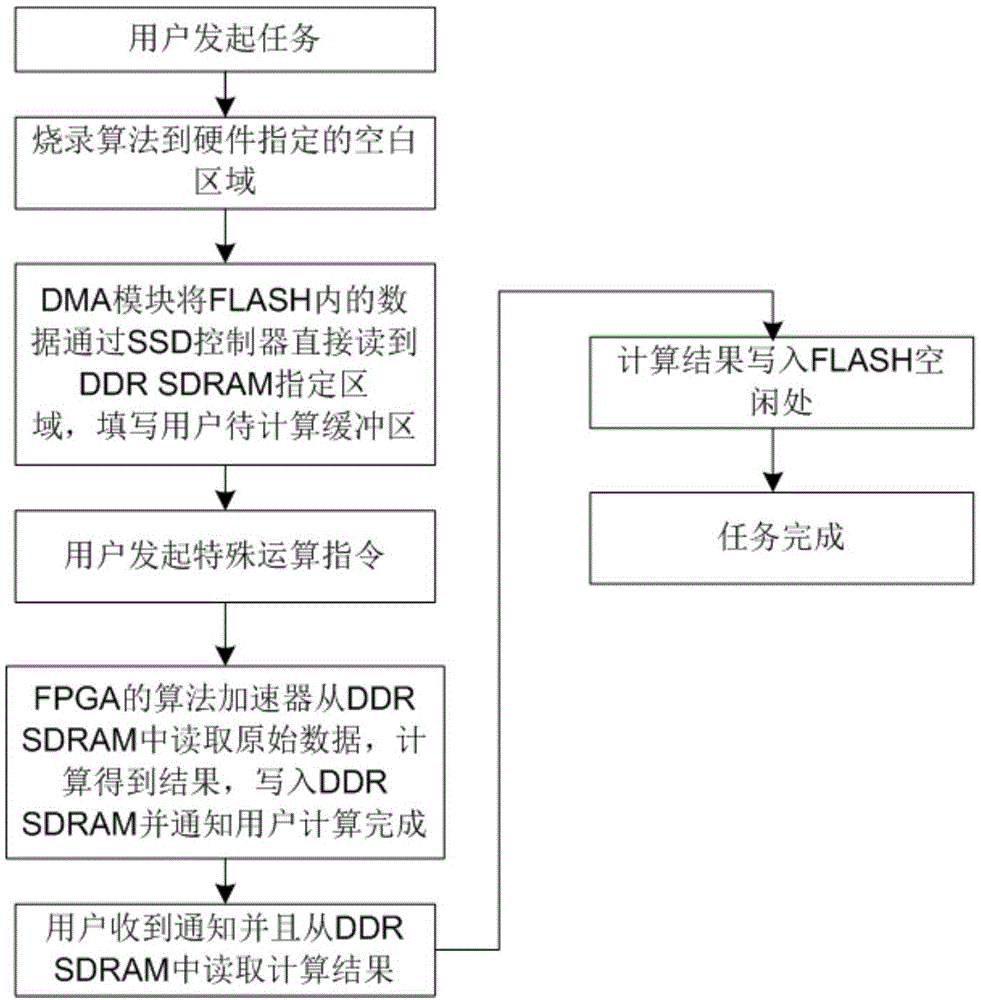
步骤s1:用户发起任务;
步骤s2:编译好的算法文件通过烧录在线更新算法接口烧录到fpga指定的空白区域;
步骤s3:dma模块访问flash的应用层接口和ddrsdram应用层接口,将flash内的数据通过ssd控制器直接读到ddrsdram指定区域,填写用户待计算缓冲区;
步骤s4:用户发起特殊运算指令;
步骤s5:fpga的算法加速器从ddrsdram中读取原始数据,计算得到结果,写入ddrsdram并通知用户计算完成;
步骤s6:用户收到通知并且从ddrsdram中读取计算结果;
步骤s7:计算结果写入flash空闲处;
步骤s8:任务完成。
作为优选,执行所述步骤s7过程中,还包括s71:计算结果写入服务器内存。
作为优选,所述存储管理软件从上而下分为用户层、中间接口层、底层管理层三个层次,其中,
用户层:具体任务及编译好的算法文件;
中间接口层:连接用户层和底层管理层的中间库;烧录在线更新算法的接口;访问ddrsdram应用层用接口;访问flash的应用层接口;提供用户态和内核态的通信机制;
底层管理层:提供服务器内存,flash和ddrsdram三者之间的互访接口;管理底层软件资源和硬件资源。
作为优选,所述加速存储单元使用了一片fpga,fpga内集成了pcie接口、ssd控制器、算法加速器和ddrsdram。
进一步地,所述ssd控制器负责管理和控制flash,通过pcie接口与服务器通信,根据服务器发送的命令对flash做读写操作。
进一步地,所述ssd控制器负责管理和控制多个flash,构成多路数据存储通道的flash阵列,通过pcie接口与服务器通信,根据服务器发送的命令对flash阵列做读写操作。
进一步地,所述fpga还集成了ddr控制器,负责管理所述ddrsdram。
更进一步地,所述dma模块分别连接ssd控制器、ddr控制器和算法加速器,用于转发所述服务器和所述ssd控制器、ddr控制器、算法加速器之间的交互信息和数据。
进一步地,所述pcie接口,用于所述fpga与所述服务器之间数据传输和结果返回。
作为优选,所述服务器可以同时负载n个所述加速存储单元,n≤6且n为整数,所述加速存储单元独立处理相同或不同的任务,相互之间互不干扰。
与现有技术相比,本发明的有益效果是:
1、在一个fpga上实现了计算功能和存储功能,节省了硬件结构空间,减少了布局难度,减少了服务器的整体功耗,降低了企业成本。
2、加速存储单元作为单一节点通过pcie接口连接到服务器主机的pcie插槽上,同时支持横向扩展,一台服务器主机可以横向扩展负载多个节点,各个节点可以利用fpga对不同的任务进行并行处理,相互之间互不干扰,大大提升服务器主机的吞吐量和性能,提高了任务运算速度,同时释放cpu资源去做更集中的逻辑控制,可应用于大数据分析、高性能计算和海量数据处理。
附图说明
图1是本发明实施例一中一种集成计算功能的存储管理系统控制方法流程图;
图2是本发明实施例二中单个加速存储单元的硬件设计拓扑图,其中,单向实线箭头表示控制流,双向空心箭头表示数据流;
图3是本发明实施例二中集成于单个加速存储单元的存储管理软件的层次架构示意图;
图4是本发明实施例二中传统数据计算存储方式示意图;
图5是本发明实施例二中本实施方案数据计算存储方式示意图;
图6是本发明实施例四中一台服务器主机的负载结构示意图;
图7是本发明实施例五中一种应用于spark平台的框架示意图。
具体实施方式
本发明提供一种集成计算功能的存储管理系统控制方法,为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
实施例一:
图1给出了一种集成计算功能的存储管理系统控制方法流程图。
一种集成计算功能的存储管理系统控制方法,包括一台服务器和至少一个集成了存储管理软件的加速存储单元,如图1所示,所述方法包括:
步骤s1:用户发起任务;
步骤s2:编译好的算法文件通过烧录在线更新算法接口烧录到fpga指定的空白区域;
步骤s3:dma模块访问flash的应用层接口和ddrsdram应用层接口,将flash内的数据通过ssd控制器直接读到ddrsdram指定区域,填写用户待计算缓冲区;
步骤s4:用户发起特殊运算指令;
步骤s5:fpga的算法加速器从ddrsdram中读取原始数据,计算得到结果,写入ddrsdram并通知用户计算完成;
步骤s6:用户收到通知并且从ddrsdram中读取计算结果;
步骤s7:计算结果写入flash空闲处;
步骤s8:任务完成。
在一种优选实施例中,执行所述步骤s7过程中,还包括s71:计算结果写入服务器内存。
实施例二:
nandflash存储器是flash存储器的一种,其内部采用非线性宏单元模式,为固态大容量内存的实现提供了廉价有效的解决方案。nandflash存储器具有容量较大、改写速度快等优点,适用于大量数据的存储,因而在业界得到了越来越广泛的应用,如嵌入式产品中包括数码相机、mp3随身听记忆卡、体积小巧的u盘等。
fpga(field-programmablegatearray),即现场可编程门阵列,它是在pal、gal、cpld等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(asic)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
鉴于此,本实施例提供了一种集成计算功能的存储管理系统,硬件上,包括一个服务器和至少一个加速存储单元,所述服务器上设有pcie插槽。软件上,采用自主开发的存储管理软件来管理实际业务逻辑,集加速功能和存储功能于一体。
图2给出了单个加速存储单元的硬件设计拓扑图。
如图2所示,加速存储单元使用了一片fpga,fpga内集成了pcie接口、ssd控制器、算法加速器和ddrsdram。
所述ssd控制器负责管理和控制nandflash,通过pcie接口与服务器通信,根据服务器发送的命令对nandflash做读写操作。
在一种优选实施例中,所述ssd控制器负责管理和控制多个nandflash,构成多路数据存储通道的nandflash阵列,通过pcie接口与服务器通信,根据服务器发送的命令对nandflash阵列做读写操作。
所述fpga还集成了ddr控制器,负责管理所述ddrsdram。
所述dma模块分别连接ssd控制器、ddr控制器和算法加速器,用于转发所述服务器和所述ssd控制器、ddr控制器、算法加速器之间的交互信息和数据。
所述pcie接口,用于所述fpga与所述服务器之间数据传输和结果返回。
图3给出了集成于单个加速存储单元的存储管理软件的层次架构示意图。
如图3所示,存储管理软件从上而下分为用户层、中间接口层、底层管理层三个层次:
用户层:具体任务及编译好的算法文件;
中间接口层:连接用户层和底层管理层的中间库;烧录在线更新算法的接口;访问ddrsdram应用层用接口;访问nandflash的应用层接口;提供用户态和内核态的通信机制;
底层管理层:提供服务器内存,nandflash和ddrsdram三者之间的互访接口;管理底层软件资源和硬件资源。
传统方式中,处理大数据时需要把存储在nandflash上的数据取到服务器内存,然后通过dma模块将数据传输到ddrsdram,最后进行计算,这其中通信占了很大比重。本实施例通过dma模块把数据从nandflash读到ddrsdram中,利用fpga的运算区域进行计算,计算完成之后把结果直接放到nandflash中和/或写入服务器内存,大大减少了数据的传输通信消耗。该设计可应用于诸如矩阵运算、图像处理、机器学习、压缩、非对称加密、bing搜索的排序等密集型计算。图4和图5是传统方式下和本实施例中数据存取方式的对比。
实施例三:
由于fpga可在不同的逻辑下执行多个线程,实现流水线的并行处理,故具有较强的并行处理能力。也就是说,对于在fpga上进行处理任务时,该任务应为适用于并行化处理的计算任务,所说的并行性是指在同一时刻或同一时间间隔内完成两种或两种以上性质相同或不相同的工作,只要在时间上互相重叠,都存在并行性。
本实施例中,一个加速存储单元可以包括一个或多个fpga。对于同样复杂程度和同等计算量的任务来说,fpga个数增多,可进一步地节省运算时间,提高运算速度。
实施例四:
如图6所示,所述加速存储单元作为单一的节点,支持横向扩展。一台服务器可以同时负载多个加速存储单元,例如,一台服务器同时横向扩展负载6个节点,封装成一台集成计算功能的存储管理系统。服务器主机将计算密集型任务分配到各节点的fpga上进行处理运算,完成一级计算;服务器主机cpu主要负责调度和数据规整,完成二级计算,避免了传统服务器主机cpu处理所有任务,一定程度上解决了内存开销过大的问题,另外,由于fpga对任务进行并行处理,大大提升了服务器处理任务的速度,提升了计算性能。
实施例五:
本实施例提供的一种集成计算功能的存储管理系统控制方法,可以应用于spark分布式计算系统。
spark是目前高效且在产业界被广泛使用的大数据计算框架,是通用、快速的大规模数据处理引擎。伯克利数据分析栈(bdas)是伯克利spark的整个生态系统的统称,其核心处理架构为spark。bdas上层应用包括:支持结构化数据sql查询与分析的查询引擎sparksql,提供机器学习功能的系统mlbase及底层的分布式机器学习库mllib,并行图计算框架graphx,流计算框架sparkstreaming,采样近似计算查询引擎blinkdb等。对于这一类密集型很强的大数据查询搜索,同时需要存储海量数据与高速计算。
本实施例提供的一种集成计算功能的存储管理系统控制方法,从硬件和软件的角度提供了一种全新的管理方式。通过将加速存储单元与spark平台结合,即将加速存储单元与spark平台的sparkmaster的计算节点sparkworker通过pcie接口相连接,通过将复杂耗时且适合并行化的计算任务在加速存储单元的fpga上进行运算,提高了计算速度,从而实现了sparkmllib更快的数据处理速度,提高了基于spark框架下mllib算法计算性能。
基于上述本发明实施例的技术方案,下面对本发明实施例的技术方案涉及的可能应用场景进行举例介绍。如图7所示,spark分布式计算系统部署多个服务器节点,每个服务器节点通过pcie接口与一个或多个加速存储单元相连。通过spark处理器对当前任务的训练分析将符合fpga运算的任务分配到加速存储单元的fpga上进行处理运算,一般的任务则利用mllib算法进行处理。通过添加加速存储单元进行并行处理计算任务,避免了传统sparkmllib算法处理所有任务,一定程度上解决了内存开销过大的问题,提升了整体sparkmllib处理任务的速度,提升了spark平台的计算性能。
某些情景下,需要将计算结果输出,例如在处理一些仿真的数据时,往往是需要将仿真的图形输出,如果某些相关计算任务是在所述加速存储单元上进行运算,这时就需要将计算结果返回到spark平台,由spark平台的显示装置将总的结果显示给用户。
以上对本发明的具体实施例进行了详细描述,但其只是作为范例,本发明并不限制于以上描述的具体实施例。对于本领域技术人员而言,任何对本发明进行的等同修改和替代也都在本发明的范畴之中。因此,在不脱离本发明的精神和范围下所作的均等变换和修改,都应涵盖在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!