一种仓库物品配置方法和装置与流程
本发明涉及仓储物流领域,特别是涉及一种仓库物品配置方法和装置。
背景技术:
目前大多数在线零售电商采用一品一仓的模式,即一种商品最小单元(stockkeepingunit,sku)只在一个仓库中储存,一种sku只有一种库存属性。近些年,随着电子商务行业的快速发展,顾客对在线零售电商的需求越来越大,并且sku品类也呈指数级增长。在这种情况下,一品一仓的传统模式会直接导致拆单率的快速增长,大大增加了电商的运营成本。从长期业务发展需求的角度出发,克隆仓的概念被提出,打破了同一sku只有一种库房属性的限制,实现多库房属性。在一品多仓情况下,sku对应的除了主体仓之外的,能够放置该sku的都叫做克隆仓。
目前,针对克隆仓的物品配置方案,通常是根据商品与克隆仓(待选品仓)中商品的同订单销量排序结果,来选择哪些商品放入克隆仓。这种方法比较直观和简单,主要思路就是,如果某些商品非常频繁地与克隆仓中的商品出现在同一个订单中,那么这些商品被放入克隆仓后,相应的订单被满足的概率会增大,由于这样的订单数量将多,所以拆单率会大幅度降低;相反,如果某些商品极少与克隆仓中的商品同单,那么这些商品放入克隆仓后,只能使得极小部分订单被满足的概率增大,因而对拆单率的降低不会有很大的贡献。因此,可以按照商品与克隆仓中商品的同单数量从大到小做个排名,排名越靠前的,越可以优先考虑放入克隆仓中。
在实现本发明过程中,发明人发现上述克隆仓物品配置方案存在配送成本较大的问题。
上述方案仅考虑了同订单销量这个特征,实际上,商品与商品之间还应该存在一些比较隐含的关联特征。例如,不同商品之间可能会具有一定程度被同时购买的关联性,该关联性无法通过订单销量体现出来。所以在实际应用中,上述现有的克隆仓物品配置方案并不能有效降低拆单率。而拆单后的子单通常需要进行单独包装配送,这样,就会导致物品配送成本的增加。因此,上述克隆仓物品配置方案会存在配送成本较大的问题。
技术实现要素:
有鉴于此,本发明的主要目的在于提供一种仓库物品配置方法和装置,可以有效节约物品的配送成本。
为了达到上述目的,本发明实施例提出的技术方案为:
一种仓库物品配置方法,包括:
根据订单数据和各仓库的物品分布数据,基于第一神经网络模型,生成拆单率函数;所述仓库包括主仓库和克隆仓库;
基于第二神经网络模型,以所述拆单率函数为目标函数,生成相应的所述克隆仓库的物品配置信息;
根据所述物品配置信息,为相应的克隆仓库配置物品。
较佳地,所述生成拆单率函数包括:
对于每个订单i,计算该订单对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j;
其中,li为m×1维向量,li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;
对于每个订单i,按照j的升序,将该订单对应的t个xi,j进行串行连接,得到一个(m×t)×1维度的向量xi;
对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi;
将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
较佳地,所述生成拆单率函数包括:
对于每个订单i,计算该订单i对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j;
其中,li为m×1维向量,li=[l1i,...,lki,...,lmi],li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;
对于每个订单i,将该订单i对应的t个xi,j,按照j的升序进行串行连接,得到该订单i对应的一个(m×t)×1维度的向量;
从所述仓库中选择一个克隆仓库,采用将所选择克隆仓库的物品分布数据向量中的0分量随机变为1的方式,生成该克隆仓库对应的r个不同的物品分布数据向量;对于每个订单i,计算该订单i对应的数据向量li与所述r个不同的物品分布数据向量中的每个向量的哈马达hadamard乘积,得到该订单i对应的r个m×1维向量,分别将每个所述r个m×1维向量与除所选择的克隆仓库之外的所有其他仓库对应的m×1维向量xi,j,按照j的升序进行串行连接,得到该订单i对应的r个(m×t)×1维度的向量;
对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi;
将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
较佳地,所述基于第二神经网络模型,以所述拆单率函数为目标函数,生成相应的所述克隆仓库的物品配置信息包括:
从所述仓库中选择一个克隆仓库s,将所选择的克隆仓库s的物品分布数据向量修改为一个非负实数连续向量θ,θ=[θ1,,...,θk,...,θm],1≤k≤m;
对于每个订单i,计算该订单i对应的数据向量li与所述克隆仓库s的物品分布数据向量hs的hadamard乘积,得到一个m×1维向量x′i,s,
对于每个订单i,按照所对应仓库编号的升序,将该订单i对应的x′i,s与除所述克隆仓库s之外的所有其他仓库对应的m×1维向量xi,j进行串行连接,得到该订单i对应的(m×t)×1维度的向量x′i;
以每个订单i对应的向量x′i作为输入样本,以
根据经过所述训练后得到的向量θ,按照向量θ的分量θk越大则对应的物品越适合放入克隆仓库s的原则,为所述克隆仓库s生成相应的物品配置信息。
较佳地,所述第一神经网络模型和所述第二神经网络模型为反向传播bp神经网络模型。
一种仓库物品配置装置,包括:
拆单率生成单元,用于根据订单数据和各仓库的物品分布数据,基于第一神经网络模型,生成拆单率函数;所述仓库包括主仓库和克隆仓库;
配置信息生成单元,用于基于第二神经网络模型,以所述拆单率函数为目标函数,生成相应的所述克隆仓库的物品配置信息;
配置单元,用于根据所述物品配置信息,为相应的克隆仓库配置物品。
较佳地,所述拆单率生成单元,用于对于每个订单i,计算该订单对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j;其中,li为m×1维向量,li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;对于每个订单i,按照j的升序,将该订单对应的t个xi,j进行串行连接,得到一个(m×t)×1维度的向量xi;对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi;将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
较佳地,所述拆单率生成单元,用于对于每个订单i,计算该订单i对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j;其中,li为m×1维向量,li=[l1i,...,lki,...,lmi],li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;对于每个订单i,将该订单i对应的t个xi,j,按照j的升序进行串行连接,得到该订单i对应的一个(m×t)×1维度的向量;从所述仓库中选择一个克隆仓库,采用将所选择克隆仓库的物品分布数据向量中的0分量随机变为1的方式,生成该克隆仓库对应的r个不同的物品分布数据向量;对于每个订单i,计算该订单i对应的数据向量li与所述r个不同的物品分布数据向量中的每个向量的哈马达hadamard乘积,得到该订单i对应的r个m×1维向量,分别将每个所述r个m×1维向量与除所选择的克隆仓库之外的所有其他仓库对应的m×1维向量xi,j,按照j的升序进行串行连接,得到该订单i对应的r个(m×t)×1维度的向量;对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi;将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
较佳地,所述配置信息生成单元,用于从所述仓库中选择一个克隆仓库s,将所选择的克隆仓库s的物品分布数据向量修改为一个非负实数连续向量θ,θ=[θ1,,...,θk,...,θm],1≤k≤m;对于每个订单i,计算该订单i对应的数据向量li与所述克隆仓库s的物品分布数据向量hs的hadamard乘积,得到一个m×1维向量x′i,s,
较佳地,所述第一神经网络模型和所述第二神经网络模型为反向传播bp神经网络模型。
一种仓库物品配置装置,包括:
存储器;以及耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令,执行上述仓库物品配置的方法。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的仓库物品配置方法。
综上所述,本发明实施例提出的仓库物品配置方案,利用神经网络,对订单数据和各仓库的物品分布数据进行分析,得到优化的拆单率函数,再利用神经网络,以该优化的拆单率函数为目标,生成相应的克隆仓库的物品配置信息。如此,可以使得克隆仓库的物品配置能够有效降低拆单率,进而可以节约物品的配送成本。
附图说明
图1为本发明实施例的方法流程示意图;
图2为本发明实施例的装置结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图及具体实施例对本发明作进一步地详细描述。
本发明实施例中将利用神经网络来挖掘物品之间的隐含特征,以通过降低拆单率,来降低物品的配送成本。
神经网络(neuralnetworks,nn)是一种运算模型,由大量的节点(或称“神经元”,或“单元”)和之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activationfunction)。每两个节点间的连接都代表一个对于通过该连接的信号的加权值,称之为权重(weight),这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。人工神经网络通常是通过一个基于数学统计学类型的学习方法(learningmethod)得以优化,所以人工神经网络也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间。
神经网络的基础在于神经元。神经元是以生物神经系统的神经细胞为基础的生物模型。在人们对生物神经系统进行研究,以探讨人工智能的机制时,把神经元数学化,从而产生了神经元数学模型。大量的形式相同的神经元连结在—起就组成了神经网络。神经网络是一个高度非线性动力学系统。虽然,每个神经元的结构和功能都不复杂,但是神经网络的动态行为则是十分复杂的;因此,用神经网络可以表达实际物理世界的各种现象。神经网络模型对人们的巨大吸引力主要在下列几点:
1)并行分布处理。
2)高度鲁棒性和容错能力。
3)分布存储及学习能力。
4)能充分逼近复杂的非线性关系。
反向传播(backpropagation,bp)网络是1986年由rumelhart和mccelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。bp网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。bp算法的基本原理是利用输出后的误差来估计输出层的直接前导层的误差,再用这个误差估计更前一层的误差,如此一层一层的反传下去,就获得了所有其他各层的误差估计。bp神经网络模型拓扑结构包括输入层(inputlayer)、隐层(hidelayer)和输出层(outputlayer)
其中,对于输入层(inputlayer),通过输入层各神经元负责接收来自外界的输入信息,并传递给中间层各神经元;
隐藏层(hiddenlayer):属于中间层,是内部信息处理层,负责信息变换,根据信息变化能力的需求,中间层可以设计为单隐层或者多隐层结构;最后一个隐层传递到输出层各神经元的信息,经进一步处理后,完成一次学习的正向传播处理过程;
输出层(outputlayer):用于向外界输出信息处理结果。
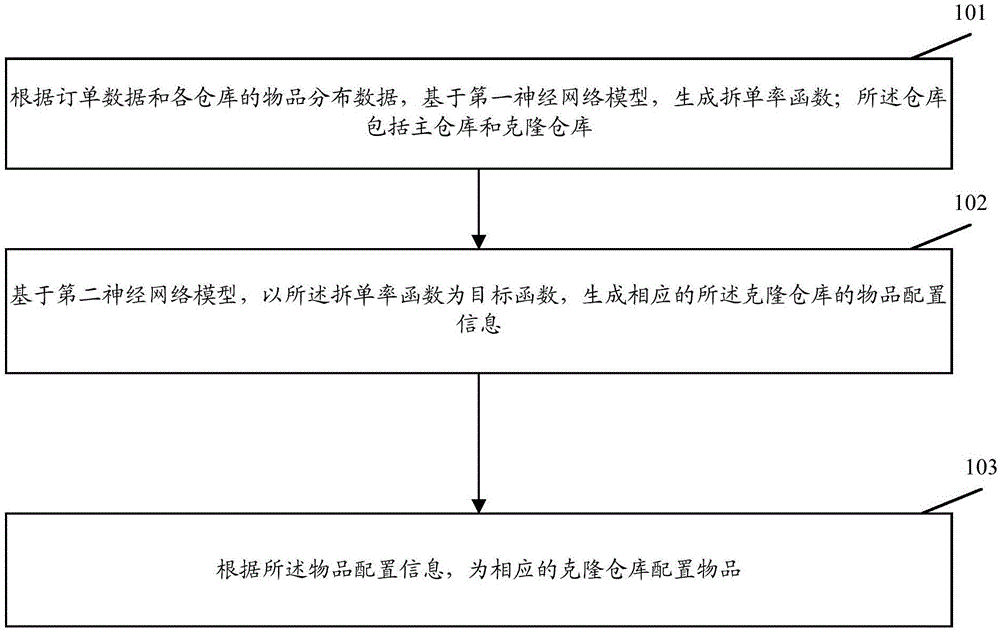
图1为本发明实施例实现的一种仓库物品配置方法方法流程示意图,如图1所示,该实施例主要包括:
步骤101、根据订单数据和各仓库的物品分布数据,基于第一神经网络模型,生成拆单率函数;所述仓库包括主仓库和克隆仓库。
本步骤,用于利用神经网络,生成最优的拆单率函数,以便在后续步骤中以该拆单率函数为目标,利用神经网络获得相应克隆仓库的物品配置信息,从而可以确保基于该物品配置信息进行仓库物品的配置时,能够获得最优的拆单率。
较佳地,所述第一神经网络模型可以为反向传播(bp)神经网络模型。
较佳地,步骤101具体可以采用下述两种方法生成拆单率函数:
方法一包括:
步骤101a1、对于每个订单i,计算该订单对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j。
其中,li为m×1维向量,li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0。
步骤101a2、对于每个订单i,按照j的升序,将该订单对应的t个xi,j进行串行连接,得到一个(m×t)×1维度的向量xi。
步骤101a3、对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi。
步骤101a4、将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
本步骤中,将以所得到的所有(xi,yi)作为训练样本,以
方法二包括:
步骤101b1、对于每个订单i,计算该订单i对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j。
其中,li为m×1维向量,li=[l1i,...,lki,...,lmi],li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;
步骤101b2、对于每个订单i,将该订单i对应的t个xi,j,按照j的升序进行串行连接,得到该订单i对应的一个(m×t)×1维度的向量。
步骤101b3、从所述仓库中选择一个克隆仓库,采用将所选择克隆仓库的物品分布数据向量中的0分量随机变为1的方式,生成该克隆仓库对应的r个不同的物品分布数据向量;对于每个订单i,计算该订单i对应的数据向量li与所述r个不同的物品分布数据向量中的每个向量的哈马达hadamard乘积,得到该订单i对应的r个m×1维向量,分别将每个所述r个m×1维向量与除所选择的克隆仓库之外的所有其他仓库对应的m×1维向量xi,j,按照j的升序进行串行连接,得到该订单i对应的r个(m×t)×1维度的向量。
这里,步骤101b3中与方法一所不同的是,需要选择出一个克隆仓库,对该克隆仓库的物品分布数据向量进行变形,得到r个不同的物品分布数据向量,利用该r个不同的物品分布数据向量生成增量数据,即对于每个订单i,生成该订单i对应的r个(m×t)×1维度的向量。如此,可以增加后续步骤中对神经网络模型进行训练的样本数量,从而可以提高训练结果的普适性。
具体地,本步骤中可以采用任意选择的方式选择所述克隆仓库。方便起见可以将第一个仓库设为克隆仓库,基于该仓库生成增量数据。
步骤101b4、对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi。
本步骤中基于向量xi计算对应拆单率yi的具体方法,为本领域技术人员所掌握,在此不再赘述。
步骤101b5、将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
本步骤中,将以所得到的所有(xi,yi)作为训练样本,以
上述两种方法中,相比于方法一,由于方法二中额外生成了增量数据,因此,可以使得第一神经网络模型更好地适应不同的克隆仓库的物品分布,有效降低过拟合。
步骤102、基于第二神经网络模型,以所述拆单率函数为目标函数,生成相应的所述克隆仓库的物品配置信息。
在步骤102中,由于是以步骤101中得到的最优的拆单率函数作为目标函数,利用第二神经网络模型,获得该拆单率函数对应的克隆仓库的物品配置信息,从而可以确保该物品配置信息对应的拆单率最优,进而可以达到有效降低配送成本的目的。
较佳地,所述第二神经网络模型可以为反向传播bp神经网络模型。
较佳地,步骤102中可以采用下述方法生成相应的所述克隆仓库的物品配置信息:
步骤1021、从所述仓库中选择一个克隆仓库s,将所选择的克隆仓库s的物品分布数据向量修改为一个非负实数连续向量θ,θ=[θ1,,...,θk,...,θm],1≤k≤m。
在实际应用中本步骤中可以采用任意选择地方式选择出克隆仓库s。较佳地,所述克隆仓库s可以与步骤101b3中用于产生增量数据时选择的克隆仓库相同。
步骤1022、对于每个订单i,计算该订单i对应的数据向量li与所述克隆仓库s的物品分布数据向量hs的hadamard乘积,得到一个m×1维向量x′i,s,
步骤1023、对于每个订单i,按照所对应仓库编号的升序,将该订单i对应的x′i,s与除所述克隆仓库s之外的所有其他仓库对应的m×1维向量xi,j进行串行连接,得到该订单i对应的(m×t)×1维度的向量x′i。
步骤1024、以每个订单i对应的向量x′i作为输入样本,以
其中,tanh()为双曲正切函数,所述第二神经网络模型的全连接层和输出层与所述第一神经网络模型的全连接层和输出层相同,向量θ的初始值为0或接近零的正实数,如果所述向量θ在训练过程中变为负数则将向量θ强制更新为零。
本步骤中,在保持拆单率参数(即
步骤1025、根据经过所述训练后得到的向量θ,按照向量θ的分量θk越大则对应的物品越适合放入克隆仓库s的原则,为所述克隆仓库s生成相应的物品配置信息。
步骤103、根据所述物品配置信息,为相应的克隆仓库配置物品。
图2为与上述方法实施例对应的一种仓库物品配置装置实施例的结构示意图,如图2所示,该仓库物品配置装置主要包括:
拆单率生成单元,用于根据订单数据和各仓库的物品分布数据,基于第一神经网络模型,生成拆单率函数;所述仓库包括主仓库和克隆仓库;
配置信息生成单元,用于基于第二神经网络模型,以所述拆单率函数为目标函数,生成相应的所述克隆仓库的物品配置信息;
配置单元,用于根据所述物品配置信息,为相应的克隆仓库配置物品。
较佳地,所述拆单率生成单元,用于对于每个订单i,计算该订单对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j;其中,li为m×1维向量,li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;对于每个订单i,按照j的升序,将该订单对应的t个xi,j进行串行连接,得到一个(m×t)×1维度的向量xi;对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi;将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
较佳地,所述拆单率生成单元,用于对于每个订单i,计算该订单i对应的数据向量li分别与每个所述仓库的物品分布数据向量hj的哈马达hadamard乘积,得到t个m×1维向量xi,j;其中,li为m×1维向量,li=[l1i,...,lki,...,lmi],li中的每个分量lki对应一种物品k,当物品k存在于订单i中时lki=1,当物品k不存在于订单i中时lki=0,1≤i≤n,i为订单编号,n为订单总数,1≤k≤m,k为物品编号,m为物品种类数;hj为m×1维向量,j为仓库编号,1≤j≤t,t为仓库总数,hj中的每个分量hkj对应一种物品k,当物品k存在于仓库j中时hkj=1,当物品k不存在于仓库j中时hkj=0;对于每个订单i,将该订单i对应的t个xi,j,按照j的升序进行串行连接,得到该订单i对应的一个(m×t)×1维度的向量;从所述仓库中选择一个克隆仓库,采用将所选择克隆仓库的物品分布数据向量中的0分量随机变为1的方式,生成该克隆仓库对应的r个不同的物品分布数据向量;对于每个订单i,计算该订单i对应的数据向量li与所述r个不同的物品分布数据向量中的每个向量的哈马达hadamard乘积,得到该订单i对应的r个m×1维向量,分别将每个所述r个m×1维向量与除所选择的克隆仓库之外的所有其他仓库对应的m×1维向量xi,j,按照j的升序进行串行连接,得到该订单i对应的r个(m×t)×1维度的向量;对于每个所述(m×t)×1维度的向量xi,计算该向量xi对应的拆单率yi;将(xi,yi)作为训练样本,以xi作为输入,以yi作为目标值,以
较佳地,所述配置信息生成单元,用于从所述仓库中选择一个克隆仓库s,将所选择的克隆仓库s的物品分布数据向量修改为一个非负实数连续向量θ,θ=[θ1,,...,θk,...,θm],1≤k≤m;对于每个订单i,计算该订单i对应的数据向量li与所述克隆仓库s的物品分布数据向量hs的hadamard乘积,得到一个m×1维向量x′i,s,
较佳地,所述第一神经网络模型和所述第二神经网络模型为反向传播bp神经网络模型。
本发明实施例还提供一种仓库物品配置装置,包括:
存储器;以及耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令,执行上述仓库物品配置方法实施例。
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现上述仓库物品配置方法实施例。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!