一种基于深度卷积网络的光场显著目标检测方法与流程
本发明属于计算机视觉、图像处理和分析领域,具体的说是一种基于深度卷积网络的光场显著目标检测方法。
背景技术:
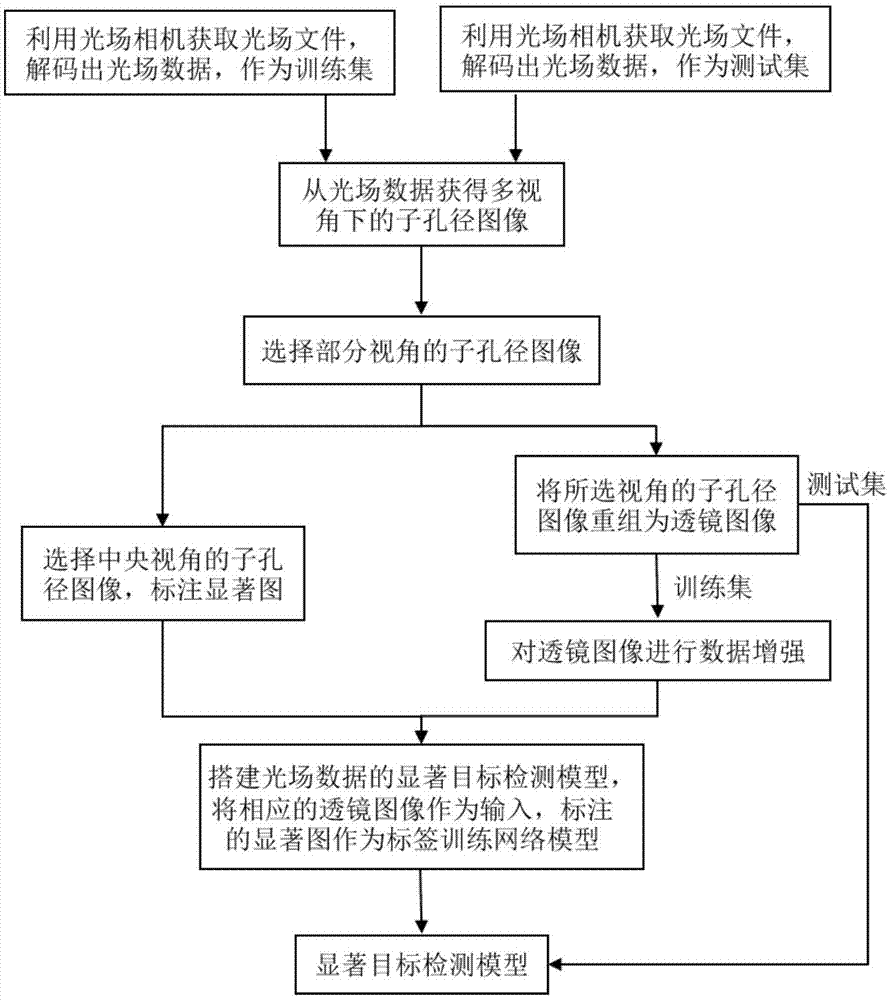
:显著性目标检测是人类视觉系统的感知能力。当观测一幅图像时,视觉系统能够快速的获取图像中感兴趣的区域和目标,获取感兴趣的区域和目标的过程即为显著目标检测。随着计算机技术与互联网的发展,以及移动智能设备的普及,人们获取外界图像呈现井喷式增长。显著目标检测从输入的大量视觉信息选择很小一部分进入后续的复杂处理,如目标检测与识别、图像检索、图像分割等,有效的降低了视觉系统的计算量。目前,显著目标检测已成为计算机视觉领域内研究的热点之一。根据可使用的图像数据,当前显著目标检测的方法可分为三类:二维显著目标检测、三维显著目标检测和光场显著目标检测。二维显著目标检测方法是利用传统相机获取二维图像,利用传统方法或者基于学习的方法,通过局部或者全局对比的框架,提取融合颜色、亮度、位置和纹理等特征,实现显著和非显著的区分。三维显著目标检测方法是利用二维图像和场景的深度信息,实现显著目标检测。场景的深度信息由三维传感器获取,该类信息在人类视觉系统中同样起着重要作用,它反应了物体和观察者之间的距离。深度信息被用于显著目标检测,弥补了传统二维图像的不足,利用颜色和深度的相互补充获取最终的显著图,在一定程度上提高了显著目标检测的精确度。光场显著目标检测方法是对光场相机获取的光场数据进行处理,实现显著目标检测。光场成像借助新的计算成像技术,能够经过一次曝光同时记录光辐射在空间中的位置和视角信息,获取的光场信息反映了自然场景的几何和反射特性。目前传统方法通过融合不同光场数据上的显著特性,提高了挑战性场景的显著目标检测的性能。虽然在计算机视觉领域中,已经出现了一些性能出色的显著目标检测方法,但这些方法依然存在着不足之处:1、在二维显著目标检测方法中,由于二维图像是光线在相机传感器上投影的积分,只包含了特定方向的光线强度,因此,二维显著目标检测对高频部分或噪声过于敏感,并易受前景和后景颜色纹理相似、后景杂乱等因素的影响。2、在三维显著目标检测方法中,场景深度信息的精度依赖于深度相机,目前的深度相机存在分辨率较低、测量范围窄、噪声大、无法测量透射材质、易受日光和光滑平面反光干扰等诸多问题。3、在三维显著目标检测方法中,颜色、深度、位置等特征信息都是相互独立的被处理再融合,没有综合地考虑其互补性。4、多数基于二维与三维图像的显著目标检测方法是以目标与背景之间存在明显差异、背景简单等假设为前提,随着图像数据的大规模增加,图像内容复杂度增加,这些方法存在一定的局限性。5、在光场显著目标检测中,光场数据在显著目标检测方面的研究刚刚起步,目前可用的数据集较少且图像质量较差。当前利用光场数据的显著目标检测都是基于传统的显著特征计算方法,且同时对色彩、深度、重聚焦等多线索分别建模,存在着特征表达力不足和鲁棒检测效果不好等问题。技术实现要素:本发明是为了解决上述现有技术存在的不足之处,提出一种基于深度卷积网络的光场显著目标检测方法,以期能充分利用光场数据的空间信息和视角信息,从而能有效提高复杂场景图像的显著目标检测的准确性。本发明为解决技术问题采用如下技术方案:本发明一种基于深度卷积网络的光场显著目标检测方法的特点是按如下步骤进行:步骤1、获得微透镜图像id;步骤1.1、利用光场设备获取光场文件,并进行解码得到光场数据集合记为l=(l1,l2,…,ld,…,ld),其中ld表示第d个光场数据,并将第d个光场数据记为ld(u,v,s,t),u和v表示空间信息中任一水平像素和竖直像素,s和t表示视角信息中任一水平视角和竖直视角;d∈[1,d],d表示光场数据的总数;步骤1.2、固定水平视角s和竖直视角t,并遍历所述第d个光场数据ld(u,v,s,t)中所有水平像素和竖直像素,得到所述第d个光场数据ld(u,v,s,t)中第t行第s列视角下的子孔径图像且的高度和宽度分别记为v和u,v∈[1,v],u∈[1,u];步骤1.3、遍历所述光场数据ld(u,v,s,t)中所有水平视角和竖直视角,获得第d个全部视角下的子孔径图像集合其中,s∈[1,s],t∈[1,t],s表示最大水平视角所在行,t表示最大竖直视角所在列;步骤1.4、定义选取的视角个数为m×m,利用式(1)从第d个全部视角下的子孔径图像集合nd中选择以中央视角为中心的第d个图像集合md:式(1)中,并对向下取整数;步骤1.5、根据x=(v-1)×m+t,y=(u-1)×m+s得到第d个微透镜图像id中第x行第y列的像素点id(x,y),从而得到高度和宽度分别为h和w的第d个微透镜图像id,其中,x∈[1,h],y∈[1,w],h=v×m,w=u×m;步骤2、从所述第d个图像集合md选取第d个中央视角的子孔径图像,记为对所述第d个中央视角的子孔径图像标注显著性区域,并令所述显著性区域的像素为1,令非显著性区域的像素为0,从而得到所述第d个微透镜图像id的第d个真实显著图gd,所述第d个真实显著图gd的高度和宽度分别为v和u;步骤3、对所述第d个微透镜图像id进行数据增强处理,得到第d个增强后的微透镜图像集合id′;对所述第d个真实显著图gd做几何变换处理,得到第d个变换后的真实显著图集合gd′;步骤4、重复步骤1.2至步骤3,获得所述光场数据集合l中d个增强后的微透镜图像集合i′=(i1′,i2′,…,id′,…,i′d)和d个变换后的真实显著图集合记为g′=(g1′,g2′,…,gd′,…,g′d);步骤5、构建第d个光场数据ld(u,v,s,t)的显著目标检测模型;步骤5.1、获取c层的deeplab-v2卷积神经网络,所述deeplab-v2卷积神经网络包括卷积层、池化层和丢弃层;步骤5.2、对所述c层的deeplab-v2卷积神经网络进行修改,得到修改后的lfnet卷积神经网络;步骤5.2.1、在所述deeplab-v2卷积神经网络的第一层之前加入一层卷积核大小为m×m的卷积层lf_conv1_1和relu激活函数lf_relu1_1;设置所述卷积层lf_conv1_1在进行卷积操作时,所述卷积核的移动步长为m;所述relu激活函数lf_relu1_1的数学表达式是φ(a)=max(0,a),其中a表示所述卷积层lf_conv1_1的输出,并作为relu激活函数lf_relu1_1的输入,φ(a)表示relu激活函数lf_relu1_1的输出;步骤5.2.2、除了卷积层lf_conv1_1和deeplab-v2卷积神经网络中已连接丢弃层的卷积层外,在所述deeplab-v2卷积神经网络中的其他卷积层后均加入一个丢弃层;步骤5.2.3、将所述deeplab-v2卷积神经网络中的第c-1层的输出通道个数设定为b个,b为像素类别个数;步骤5.2.4、在所述deeplab-v2卷积神经网络的第c层后增加一个上采样层,利用所述上采样层对所述deeplab-v2卷积神经网络的第c层输出的特征图fd(q,r,b)进行上采样操作,获得上采样后的特征图fd′(q,r,b);其中,q、r和b分别表示所述特征图fd(q,r,b)的宽度、高度和通道数;步骤5.2.5、在所述上采样层后增加一个剪切层,根据所述第d个真实显著图gd的长v和宽u,利用所述剪切层对所述特征图fd′(q,r,b)进行剪切,获得所述微透镜图像id的像素类别预测概率图fd″(q,r,b);步骤5.3、以所述增强后的微透镜图像集合i′作为所述lfnet卷积神经网络的输入,以所述变换后的真实显著图集合g′作为标签,使用交叉熵损失函数,并利用梯度下降算法对所述lfnet卷积神经网络进行训练,从而得到光场数据的显著目标检测模型,利用所述显著目标检测模型实现对光场数据的显著目标检测。与现有技术相比,本发明的有益效果在于:1、本发明利用第二代光场相机采集了复杂多变场景的光场数据,这些场景包含了多种尺寸的显著性目标、多种光源、显著目标与背景相似、背景杂乱等难点,充分补充了当前光场显著数据在数据和难度上的不足,并提高了当前光场显著数据的质量。2、本发明利用深度卷积网络在图像处理方面强大的功能提取图像特征,融合光场数据的空间信息和视角信息,使用空洞金字塔网络捕捉微透镜图像的上下文信息,对图像场景中的显著目标进行检测,解决了当前二维或三维显著目标检测方法无法使用视角信息的缺陷,提高了复杂场景下的图像显著目标检测的精度和鲁棒性。3、本发明所使用微透镜图像中的多视角信息反应着场景的空间几何特征,直接将微透镜图像输入到卷积神经网络中,实现了显著目标检测,克服了当前光场显著目标检测方法独立处理深度和颜色信息的缺点,兼顾深度感知和视觉显著性,有效利用了深度和颜色的互补性,提高了图像显著目标检测的准确度。附图说明图1为本发明的显著目标检测方法工作流程图;图2为本发明方法获取的子孔径图像;图3为本发明方法获取的微透镜图像;图4为本发明方法获取的数据集部分场景和真实显著图;图5为本发明方法微透镜图像输入网络模型的详细过程图;图6为本发明方法所使用的deeplab-v2模型结构图;图7为本发明方法和其他光场显著目标检测方法在第二代光场相机采集的数据集上,获取的部分显著目标检测结果对比图;图8为为本发明方法以“查全率/查准率曲线”为度量标准,在第二代光场相机采集的数据集上,与当前其他光场显著性提取方法进行量化对比的分析图。具体实施方式本实施例中,一种基于深度卷积网络的光场显著目标检测方法,其流程图如图1所示,并按如下步骤进行:步骤1、获得微透镜图像id;步骤1.1、利用光场设备获取光场文件,并进行解码得到光场数据集合记为l=(l1,l2,…,ld,…,ld),其中ld表示第d个光场数据,并将第d个光场数据记为ld(u,v,s,t),u和v表示空间信息中任一水平像素和竖直像素,s和t表示视角信息中任一水平视角和竖直视角;d∈[1,d],d表示光场数据的总数;在本实施例中,使用第二代光场相机获取光场文件,并用lytropowertoolbeta工具对光场文件进行解码,获得光场数据ld(u,v,s,t);光场数据ld(u,v,s,t)是利用双平面参数法表示,在四维(u,v,s,t)坐标空间中,一条光线对应着光场的一个采样点,u、v平面表示空间信息平面,s、t平面表示视角信息平面;在本发明的实验中,共获取640个光场数据,平均分成5份,轮流选择1份作为测试集,其余4份作为训练集。步骤1.1中的d表示训练数据集,d=512;步骤1.2、固定水平视角s和竖直视角t,并遍历第d个光场数据ld(u,v,s,t)中所有水平像素和竖直像素,得到第d个光场数据ld(u,v,s,t)中第t行第s列视角下的子孔径图像且的高度和宽度分别记为v和u,v∈[1,v],u∈[1,u],在本实验中,v=375,u=540;步骤1.3、遍历光场数据ld(u,v,s,t)中所有水平视角和竖直视角,获得第d个全部视角下的子孔径图像集合其中,s∈[1,s],t∈[1,t],s表示最大水平视角所在行,t表示最大竖直视角所在列;具体实施中,s=14,t=14;如图2所示,图2中左图是所有视角的子孔径图像集合,图2中右图是第6行第11列视角下的子孔径图像步骤1.4、定义选取的视角个数为m×m,利用式(1)从第d个全部视角下的子孔径图像集合nd中选择以中央视角为中心的第d个图像集合md;具体实施中,m=9,共选取了81个视角图像;实验显示,更多的视角可以提供更多的信息,能进一步提升显著目标检测模型的性能,但是,更多的视角需要消耗大量存储和计算时间,增加实验难度;式(1)中,并对向下取整数;步骤1.5、根据x=(v-1)×m+t,y=(u-1)×m+s得到第d个微透镜图像id中第x行第y列的像素点id(x,y),从而得到高度和宽度分别为h和w的第d个微透镜图像id,如图所3所示,其中,x∈[1,h],y∈[1,w],h=v×m,w=u×m;在本实施例中,h=3375,w=4860,图3中左图是微透镜图像id,图3中右图是微透镜图像id局部放大图,在局部放大图中方格内的所有像素代表同一空间信息、不同视角信息的像素集合。步骤2、从第d个图像集合md选取第d个中央视角的子孔径图像,记为对第d个中央视角的子孔径图像标注显著性区域,并令显著性区域的像素为1,令非显著性区域的像素为0,从而得到第d个微透镜图像id的第d个真实显著图gd,第d个真实显著图gd的高度和宽度分别为v和u,具体实施中,v=375,u=540;如图4所示,图4中第一行和第三行是微透镜图像,第二行和第四是真实显著图。步骤3、对第d个微透镜图像id进行数据增强处理,得到第d个增强后的微透镜图像集合id′;对第d个真实显著图gd做几何变换处理,得到第d个变换后的真实显著图集合gd′;在本实施例中,对第d个微透镜图像id进行旋转、翻转、增加色度、增加对比度、增加亮度、降低了亮度和增加高斯噪声处理,实现了数据增强,数据增强可以提高显著目标检测模型的泛化能力。步骤4、重复步骤1.2至步骤3,获得光场数据集合l中d个增强后的微透镜图像集合i′=(i1′,i2′,…,id′,…,i′d)和d个变换后的真实显著图集合记为g′=(g1′,g2′,…,gd′,…,g′d);步骤5、构建第d个光场数据ld(u,v,s,t)的显著目标检测模型;步骤5.1、获取c层的deeplab-v2卷积神经网络,deeplab-v2卷积神经网络包括卷积层、池化层、丢弃层和合并层,具体实施中,c=24,deeplab-v2采用深度卷积神经网络,由16层卷积层、5层池化层、2层丢弃层和1层合并层组成,用于语义分割,其详细结构如图6所示,deeplab-v2含有空洞金字塔网络结构,以多个比例捕捉图像的上下文,实现多个尺度大小的显著目标检测。步骤5.2、对c层的deeplab-v2卷积神经网络进行修改,得到修改后的lfnet卷积神经网络,lfnet卷积神经网络的详细结构如图5所示;步骤5.2.1、在deeplab-v2卷积神经网络的第一层之前加入一层卷积核大小为m×m的卷积层lf_conv1_1和relu激活函数lf_relu1_1;设置卷积层lf_conv1_1在进行卷积操作时,卷积核的移动步长为m;具体实施中,m=9;在步骤1.4和步骤1.5构建微透镜图像id时,选取的视角个数为9×9,为了网络可以更好的提取并融合多视角信息,所以设置卷积层lf_conv1_1的卷积核大小为9×9,步长为9;relu激活函数lf_relu1_1的数学表达式是φ(a)=max(0,a),其中a表示卷积层lf_conv1_1的输出,并作为relu激活函数lf_relu1_1的输入,φ(a)表示relu激活函数lf_relu1_1的输出;步骤5.2.2、除了卷积层lf_conv1_1和deeplab-v2卷积神经网络中已连接丢弃层的卷积层外,在deeplab-v2卷积神经网络中的其他卷积层后均加入一个丢弃层;在本实施例中,加入丢弃层,可以有效防止过拟合,同时提高显著目标检测模型的泛化能力;步骤5.2.3、将deeplab-v2卷积神经网络中的第c-1层的输出通道个数设定为b个,b为像素类别个数;具体实施中,c-1=23,b=2;显著目标检测模型是对像素进行分类,分为显著和非显著两类。步骤5.2.4、在deeplab-v2卷积神经网络的第c层后增加一个上采样层,利用上采样层对deeplab-v2卷积神经网络的第c层输出的特征图fd(q,r,b)进行上采样操作,获得上采样后的特征图fd′(q,r,b);其中,q、r和b分别表示特征图fd(q,r,b)的宽度、高度和通道数;步骤5.2.5、在上采样层后增加一个剪切层,根据第d个真实显著图gd的长v和宽u,利用剪切层对特征图fd′(q,r,b)进行剪切,获得微透镜图像id的像素类别预测概率图fd″(q,r,b);步骤5.3、以增强后的微透镜图像集合i′作为lfnet卷积神经网络的输入,以变换后的真实显著图集合g′作为标签,使用交叉熵损失函数,并利用梯度下降算法对lfnet卷积神经网络进行训练,从而得到光场数据的显著目标检测模型,利用显著目标检测模型实现对光场数据的显著目标检测。按照步骤1.1至步骤2对测试集进行处理,获得测试集的微透镜图像,测试集的微透镜图像输入到显著目标检测模型中,得到测试集的像素类别预测概率图ftest″(q,r,b),利用式(2)提取显著图fs″,式(2)中ftest″(q,r,2)代表概率图ftest″(q,r,b)第二个通道的数值;对显著图fs″归一化,得到最终的显著图fs。fs″=ftest″(q,r,2)(2)为了更公平的评价本发明方法中得到的显著目标检测模型的性能,轮流选择训练集和测试集,对5次测试结果取平均作为评价显著目标检测模型性能的最终指标。图7为本发明的基于深度卷积网络的显著目标检测方法与当前其他光场显著目标检测方法进行定性的对比,其中,ours表示本发明的基于深度卷积网络的显著目标检测方法;multi-cue表示基于聚焦流、视角流、深度和色彩的光场显著目标检测方法;dilf表示基于色彩、深度和背景先验的光场显著目标检测方法;wsc表示基于稀疏编码理论的光场显著目标检测方法;lfs表示基于目标和背景建模的显著目标检测方法。4种方法均在本发明使用的第二代光场相机采集的真实场景数据集上进行测试。表1为本发明的基于深度卷积网络的显著目标检测方法以“f-measure”、“wf-measure”、“平均精度ap”、“平均绝对值误差mae”为度量标准,并利用第二代光场相机采集的数据集,与当前其他光场显著目标检测方法进行量化对比的分析表,“f-measure”是“查全率/查准率曲线”度量的统计指标,其值越接近1,表明显著目标检测的效果越好,“wf-measure”是“加权查全率/查准率曲线”度量的统计指标,其值越接近1,表明显著目标检测的效果越好,“ap”度量了显著目标检测的结果的平均精准度,其值越接近1,表示显著目标检测的效果越好,“mae”度量了显著目标检测的结果与真实结果的平均绝对差异程度,其值越接近0,表明显著目标检测的效果越好。图8为本发明的基于深度卷积网络的显著目标检测方法以“准确率-召回率曲线pr曲线”为度量标准,与当前其他光场显著目标检测方法进行量化对比的分析图,若一个pr曲线被另外一个pr曲线完全“包住”,则后者的性能优于前者。表1显著目标检测方法oursmulti-cuedilfwsclfsf-measure0.81180.66490.63950.64520.6108wf-measure0.75410.54200.48440.59460.3597ap0.91240.65930.69220.59600.6193mae0.05510.11980.13900.10930.1698由表1的定量分析表可见,本发明方法获得的“f-measure”、“wf-measure”、“ap”和“mae”均高于其他光场显著目标检测方法。由图8的pr曲线图可见,本发明方法表现出“查全率/查准率曲线”靠近右上角,均包含其他方法的pr曲线,且当查全率相同时,错检概率较低。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1