一种用于中文微博情感分类的特定情感词典的生成方法与流程
本发明涉及计算机社会媒体文本情感分析领域,提出了一种用于中文微博情感分类的特定情感词典的生成方法。
背景技术:
情感词典的构建是情感分析任务的一个基本和重要的方面。其中,词或短语是表达积极或消极情感的基本元素。目前,微博已成为互联网上一种时尚的交流方式。个人用户可以通过新浪微博等媒介自由、方便、即时地表达他们对产品和公共事件的看法。由于微博的长度特别短和丰富的词汇量,微博表示的向量空间模型非常稀疏。因此,词典方法更适合于微博情感分析。但不同领域使用的情感词汇是不同的,在不同的领域中出现的同一个词可能表达不同的观点,这就导致了情感表达的多样性和情感词汇的语义多变性。由于词或短语的情感往往取决于一个特定的领域,并且,在一个特定领域中,使用通用情感词典对情感词汇的人工标注是耗时耗力的,因此,通用情感词典并不能很好的对特定领域的情感进行分类,不能满足特定领域情感分类的需求。
现有技术中提出了诸如基于语言规则的方法、基于语料库的方法和基于词典的方法来自动地构建领域特定的情感词典。但是,由于微博的语法的表达形式多样,用户在组织微博时没有按照语法规则,因此,基于语言规则的方法并不能适微博所有情况;基于语料库的方法又严重依赖于语料库的规模,基于词典的方法与通用的情感词典的质量密切相关。因此,上述三种方法均不适应于微博特定领域情感词典的构建。
另外,已有的情感分析研究往往关注于类似“美好”、“厌恶”和“喜欢”等显式的情感特征(explicitsentimentfeatures)。这些情感特征的一个明显要素是有明显的情感指示。这些直接在实体或者方面上表达情感的情感词、短语和习语被称作显式情感特征。事实上,许多用户使用语言修辞或事实的语句来表达含蓄间接地情感。隐式情感特征(implicitsentimentfeatures)通常是指表达正面或负面情感而不具有明显情感指示词的特征。这些特征往往陈述了一个事实或者间接地表达了情感。包含了隐式情感特征“油老虎”、“洪荒之力”、“水军”和“五毛特效”的四个微博如图3所示。因为没有任何的情感指示,隐式情感特征的识别一直是一个有挑战性的问题。
技术实现要素:
本发明旨在通过提取显性和隐性的情感特征来构建微博特定的情感词典,并根据情感特征的情感极性(正面、负面和中性)对微博进行情感分类。
为达到上述目的,针对微博特定情感词汇的构建和所提到的隐式情感特征特点,本发明提出了一种用于中文微博情感分类的特定情感词典的生成方法,包括以下步骤:
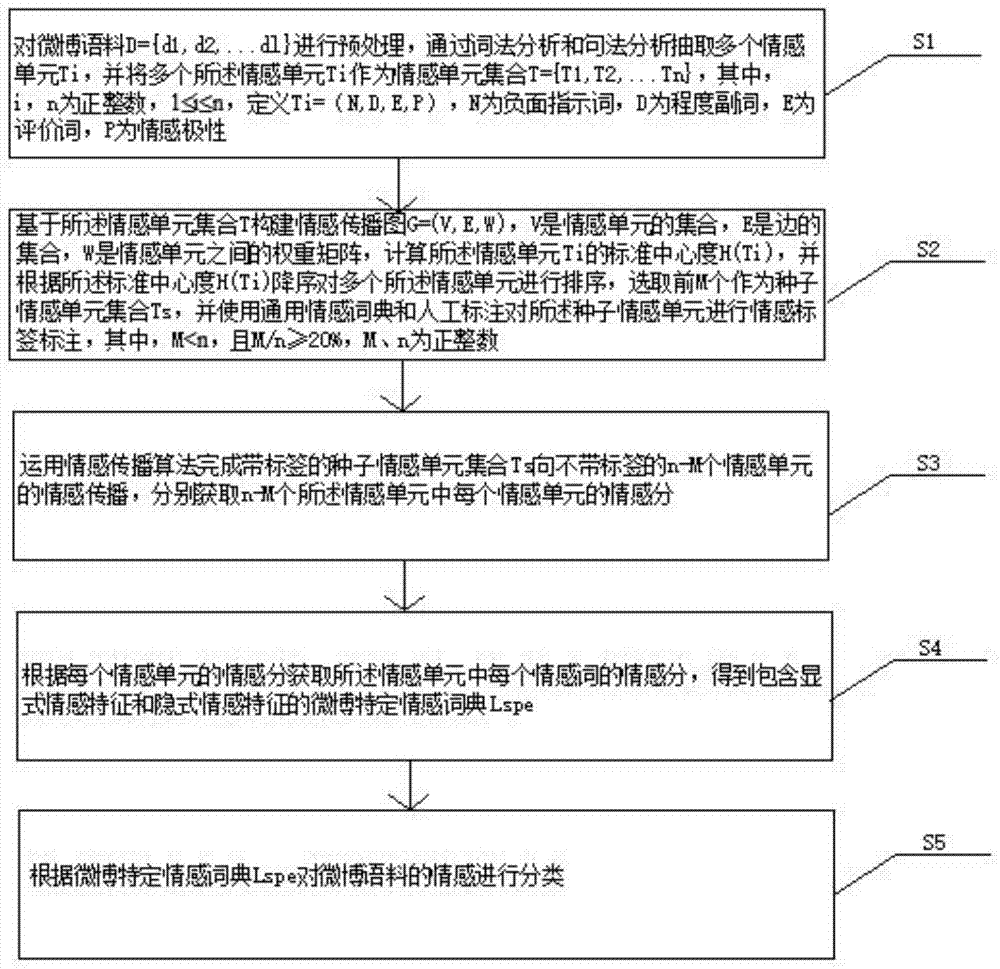
s1,对微博语料d={d1,d2,…dl}进行预处理,通过词法分析和句法分析抽取多个情感单元ti,并将多个所述情感单元ti作为情感单元集合t={t1,t2,…tn},其中,i,n为正整数,1≤i≤n,定义ti=(n,d,e,p),n为负面指示词,d为程度副词,e为评价词,p为情感极性;
s2,基于所述情感单元集合t构建情感传播图g=(v,e,w),v是情感单元的集合,e是边的集合,w是情感单元之间的权重矩阵,计算所述情感单元ti的标准中心度h(ti),并根据所述标准中心度h(ti)降序对多个所述情感单元ti进行排序,选取前m个作为种子情感单元集合ts,并使用通用情感词典和人工标注对所述种子情感单元进行情感标签标注,其中,m<n,且m/n≥20%,m、n为正整数;
s3,运用情感传播算法完成带标签的种子情感单元集合ts向不带标签的n-m个情感单元的情感传播,分别获取n-m个所述情感单元中每个情感单元的情感分;
s4,根据每个情感单元的情感分获取所述情感单元中每个情感词的情感分,得到包含显式情感特征和隐式情感特征的微博特定情感词典lspe;
s5,根据微博特定情感词典lspe对微博语料的情感进行分类。
根据本发明实施例提出的用于中文微博情感分类的特定情感词典的生成方法,首先对微博语料进行预处理,并选取多个情感单元,接着使用多个情感单元构建情感传播图,并计算情感单元的标准中心度,进而通过标准中心度的又大到小对情感单元进行排列,选取前m个情感单元作为种子情感单元,接着,通过通用情感词典和人工标注对种子情感单元进行情感标签标注,最后,通过情感传播算法完成带标签的种子情感单元集合向不带标签的情感单元的情感传播,并获取每个情感单元中每个情感单元的情感分,得到包含显式情感特征和隐式情感特征的微博特定情感词典,进而根据微博特定情感词典对微博语料的情感进行分类。
根据本发明的一个实施例,所述步骤s1包括:
s11,使用规则的方法过滤掉微博数据集d={d1,d2,…dl}中链接、停用词、重复词和噪音信息;
s12,使用词性标注工具对d={d1,d2,…dl}进行词法分析,且使用依存语法分析工具对d={d1,d2,…dl}进行句法分析;
s13,抽取d={d1,d2,…dl}中的形容词、动词、副词和名词作为候选情感特征w={w1,w2,…wn},并过滤掉低频词;
s14,并且抽取依存句法分析结果中的负面修饰关系和程度修饰关系;
s15,将抽取的所述候选情感特征、所述负面修饰关系和所述程度修饰关系作为情感单元ti,多个所述情感单元组成情感单元集合t={t1,t2,…tn}。
根据本发明的一个实施例,标准中心度
其中,
n为语料中情感单元的总数量,ni为ti在图g中的度,hits(ti)为语料中ti出现的次数,hits(tj)为语料中tj出现的次数,hits(ti,tj)为ti和tj在局部和社会上下文下出现在同一个窗口下的次数,情感单元之间的关系矩阵记为pij。
根据本发明的一个实施例,步骤s3还包括:
s31,将情感单元的初始情感分向量记为score(t):
score(t)=[score(t1),score(t2),…score(tn)]
对score(t)进行归一化:
其中,为tpos正面的情感单元的集合,tneg为负面的情感单元的集合;
s32,去除图g的较小的连接边来进行剪枝操作,其中,对矩阵p′的每一行保留k个较大的值,其余赋值为0,以确定每个情感单元的k个较大的单元作为其情感邻居,
s33,定义情感传播的概率转移矩阵如下:
其中,β∈[0,1]为适应性参数,a为部分行为1/n,其余行全为0的矩阵,j为所有元素为1/n的矩阵。加入矩阵a的目的是保证矩阵p′没有非0行;
s34,情感标签传播的过程定义如下:
其中score(tit+1)为ti在t+1迭代下的情感分,α∈[0,1]为权重参数,
s35,当迭代停止时,根据对score(t)进行归一化:
根据本发明的一个实施例,步骤s4还包括:
s41,根据情感单元的情感分来计算情感特征的情感分:
其中,n(wi)为词wi在语料中的出现频次,n在情感单元ti的负面指示词,为在情感单元ti中的程度副词
s42,获取包含显式情感特征和隐式情感特征的微博特定情感词典lspe。
根据本发明的一个实施例,步骤s5还包括:
将所述微博特定的情感词典lspe应用到情感分类中,其中,考虑了显式和隐式的情感特征、中文微博领域的20条语义合成规则,并且微博di的情感分score(di)由所有的情感单元求和得到,以根据微博的情感分来确定其最终的情感极性。
与现有技术相比,本发明具有以下有益效果:(1)本发明提出了一种新的情感单元情感传播框架,可以在中文微博数据集上生成微博特定的情感词典,并且生成的词典既包含了显式的情感特征,也包含了隐式的名词或者名词短语情感特征;(2)使用社会关系、主题特征和局部上下文信息来构建情感传播图及其邻接矩阵。情感传播算法从带标签的单元向不带标签单元传播情感。通过情感标签传播,可以得到显式和隐式情感特征的情感分;(3)在uci和weibo两个微博数据集上验证了提出的框架。实验结果验证了本发明可以生成高质量微博特定的情感词典,并在情感分类任务取得了较好的结果,提高情感分类的准确率。
附图说明
图1是根据本发明实施例的用于中文微博情感分类的特定情感词典的生成方法的流程图。
图2是融合社会关系和局部上下文的中文特定领域情感词典生成框架图。
图3是包含四个隐式特征“油老虎”、“洪荒之力”、“水军”和“五毛特效”的微博。
图4是在情感单元上下文传播框架下的三个微博处理流程图。
图5是在微博中的目标情感单元的局部上下文和社会关系上下文示意图。
图6是来自于新浪微博用户关系及其发布的微博图。
图7是uci数据集5折交叉验证下得到的情感词典的一致率图。
图8是weibo数据集5折交叉验证下得到的情感词典的一致率图。
图9是在uci数据集上的名词性情感特征的词云图。
图10是在weibo数据集上的名词性情感特征的词云图。
图11是在uci数据集下的情感分类结果(正面、负面和中性)。
图12是在weibo数据集下的情感分类结果(正面和负面)。
具体实施方式
下面结合附图来进一步描述本发明。
如图1至图12所示,本发明框架主要分为以下五个步骤,它们逐层相接并最终将其进行融合。学习过程主要包括以下步骤:
s1,对微博语料d={d1,d2,…dl}进行预处理,通过词法分析和句法分析抽取多个情感单元ti,并将多个所述情感单元ti作为情感单元集合t={t1,t2,…tn},其中,i,n为正整数,1≤i≤n,定义ti=(n,d,e,p),n为负面指示词,d为程度副词,e为评价词,p为情感极性。
其中,步骤s1包括:s11,使用规则的方法过滤掉微博数据集d={d1,d2,…dl}中链接、停用词、重复词和噪音信息;
s12,使用词性标注工具对d={d1,d2,…dl}进行词法分析,且使用依存语法分析工具对d={d1,d2,…dl}进行句法分析;
s13,抽取d={d1,d2,…dl}中的形容词、动词、副词和名词作为候选情感特征w={w1,w2,…wn},并过滤掉低频词;
s14,并且抽取依存句法分析结果中的负面修饰关系和程度修饰关系;
s15,将抽取的所述候选情感特征、所述负面修饰关系和所述程度修饰关系作为情感单元ti,多个所述情感单元组成情感单元集合t={t1,t2,…tn}。
在预处理阶段,首先过滤掉微博中链接、停用词、重复词和其他噪音信息。使用哈工大语言技术平台(ltp)中的词性标注和依存语法分析工具来进行词法分析和句法分析。对于微博中的特定字符,我们首先抽取由#标注的话题标签信息、@标注的用户关系和表情符号等。定义可能表达情感的词或短语为候选的显式和隐式的情感特征。词法分析可以分析的词语标注信息(partsofspeech,pos)、主题特征和社交网络中用户关系等。我们抽取形容词、动词、副词和名词作为候选的情感特征,并过滤掉频次较低的词。通过分析语言元素之间的依赖关系,依存句法分析揭示了它们的语法结构。抽取依存句法分析结果中的负面修饰关系和程度修饰关系。另外,微博情感数据记为d={d1,d2,…dl},w={w1,w2,…wn}为潜在的情感特征集,其中wk为情感词或者短语,1≤k≤n。n为负面指示词,例如“不”,“不是”和“没有”等。d为程度副词,例如“完全地”和“相当地”等。
其中,情感单元集合记为t={t1,t2,…tn},其中ti为情感单元,1≤i≤n。ts为种子情感单元的集合,|ts|=m。程度副词和负面指示词会影响情感的情感强度和极性。例如,如图4所示,在情感单元(不,很,好,负面)中,“好”是正面的情感词,而“很”增强了负面情感的程度。
s2,基于所述情感单元集合t构建情感传播图g=(v,e,w),v是情感单元的集合,e是边的集合,w是情感单元之间的权重矩阵,计算所述情感单元ti的标准中心度h(ti),并根据所述标准中心度h(ti)降序对多个所述情感单元ti进行排序,选取前m个作为种子情感单元集合ts,并使用通用情感词典和人工标注对所述种子情感单元进行情感标签标注,其中,m<n,且m/n≥20%,m、n为正整数。
需要说明的是,使用局部上下文和社会关系来构建情感单元之间的连接图。其中,情感单元的局部上下文包括相关微博中的其他情感单元,即相关微博的评论信息,以及同一个微博用户发布的其他微博。情感单元的社会关系上下文包括转发和回复信息、主题特征、用户关系信息等。
另外,特定的情感单元ti的局部上下文和社会关系上下文如图5所示。其中,在微博d中的目标情感单元ti的局部上下文和社会关系上下文示意图。tj和tk是ti的局部上下文。ti的社会关系上下文包括d1、d2和d3,其中d1是回复或者转发的微博,d2代表和ti有共同主题的微博,d3是和d有用户关系的微博。
需要说明的是,构建情感传播图,需要确定两个情感单元之间的邻居关系,因此定义传播窗口定义为一个特定单元ti的前n个情感单元和后n个情感单元。共现关系指的是两个词出现在同一个窗口下的同现关系。可以使用共现关系和语义规则来推断不带标签情感单元的情感极性。若两个情感单元出现在同一个窗口的概率较高,则两个情感单元的互信息也越高。
举例来说,来自于新浪微博的用户关系和发布的微博及情感极性如图6所示。不同用户之间组成了带方向的关注和被关注的关系,例如,usera是userb的粉丝,而userb没有关注usera。标签“@usera”表示相关的上下文是关于usera。由“#”和“#”标记的主题标签暗示了微博的主题,例如在微博“#大众辉腾#这车实在是个油老虎.”中,进而可以推断词微博是关于#大众辉腾#。此外,不同的用户可以讨论相同的主题,例如#大众辉腾#and#重返好声音#。在图6中,在userd发布的微博“无与伦比的安全性,令人赞叹的细节工艺!”中,“无与伦比”和“令人赞叹”都表达了正面的情感倾向。
除了共现关系,根据连词可以直接判断情感单元之间的语义关系。由并列连词连接的情感单元有较大的概率拥有相同的情感极性和相似的情感强度。例如,在userc发布的微博“超级低音,如同天籁之声#重返好声音#”中,由“如同”连接的(-,超级,低音)和(-,-,天籁)都表达了正面的情感倾向。而由转折连词连接的两个情感单元拥有相反的情感极性。例如,在usera发布的微博“体验不是很好,但我“稀饭”!”中,由“但”连接的两个子句表达了相反的情感倾向。
除了连接词,还可利用表1的语言语义规则来判断情感单元之间的语义关系。其中,规则1-11展示了词性和合成规则的情感元素合成规则。规则12-17展示了条件子句情感合成的6条规则。除了这些语义规则,还需要考虑虚拟语气、疑问句、讽刺和反语现象。这三种需要特殊处理的句子如规则18-20所示。虚拟语气是用来表示说话者不是一个事实,而是一个假设、愿望、怀疑或推测。尽管在问题句子中可能有情绪指示词,但句子并没有表达任何情感。讽刺或讽刺导致了微博的情感极性的逆转。
表1中文微博领域的20条情感语义合成规则
在得到两个情感单元之间的关系以后,ti和tj之间的边定义为pij=pmi(ti,tj)
其中,n为语料中情感单元的总数量,hits(ti)为语料中ti出现的次数,hits(tj)为为语料中tj出现的次数,hits(ti,tj)为ti和tj在局部和社会上下文下出现在同一个窗口下的次数。情感单元之间的关系矩阵记为pn×n。
此外,为度量在情感传播图g中的节点(情感单元)的连接度,定义ti连接到tj连接pi′j概率如下:
其中,n为情感单元的总数量,ni为ti在图g中的度(degree)。有较高标准中心度的节点表明此节点在网络中越重要,因此,使用标准中心度来衡量节点在图g的连接度。
若h(ti)越高,则ti的连接度越高;反之,则越低。由于较高值的h(ti)表明ti对于情感标签传播的贡献也越大。因此,根据h(ti)值的大小对所有的ti排序,并选取前m个情感单元作为种子情感单元集合ts,从而,种子情感单元可以为情感传播图g提供正确的情感来源。具体的种子情感单元选取算法如表2所示。
表2种子情感单元的选取算法
在得到种子情感单元后,我们使用通用的情感词典和人工校准来对其进行情感标注。已有的情感词典往往不包含网络词汇,我们加入诸如“山寨”、“型男”和“桑心”等网络流行语加入到通用的情感词典中。人工校准是对种子情感单元的标签进行检查,并对不准确的标签进行纠正。
s3,运用情感传播算法完成带标签的种子情感单元集合ts向不带标签的n-m个情感单元的情感传播,分别获取n-m个所述情感单元中每个情感单元的情感分。
步骤s3还包括:
s31,将情感单元的初始情感分向量记为score(t):
score(t)=[score(t1),score(t2),…score(tn)]
对score(t)进行归一化:
其中,为tpos正面的情感单元的集合,tneg为负面的情感单元的集合;
s32,去除图g的较小的连接边来进行剪枝操作,其中,对矩阵p′的每一行保留k个较大的值,其余赋值为0,以确定每个情感单元的k个较大的单元作为其情感邻居,
s33,定义情感传播的概率转移矩阵如下:
其中,β∈[0,1]为适应性参数,a为部分行为1/n,其余行全为0的矩阵,j为所有元素为1/n的矩阵。加入矩阵a的目的是保证矩阵p′没有非0行;
s34,情感标签传播的过程定义如下:
其中score(tit+1)为ti在t+1迭代下的情感分,α∈[0,1]为权重参数,
s35,当迭代停止时,根据对score(t)进行归一化:
表3情感传播算法
s4,根据每个情感单元的情感分获取所述情感单元中每个情感词的情感分,得到包含显式情感特征和隐式情感特征的微博特定情感词典lspe。
步骤s4还包括:
s41,根据情感单元的情感分来计算情感特征的情感分:
其中,n(wi)为词wi在语料中的出现频次,n在情感单元ti的负面指示词,d为在情感单元ti中的程度副词。
s42,获取包含显式情感特征和隐式情感特征的微博特定情感词典lspe。
s5,根据微博特定情感词典lspe对微博语料的情感进行分类。
步骤s5还包括:将所述微博特定的情感词典lspe应用到情感分类中,其中,考虑了显式和隐式的情感特征、中文微博领域的20条语义合成规则,并且微博di的情感分score(di)由所有的情感单元求和得到,以根据微博的情感分来确定其最终的情感极性。
表4在hownet、ntusd和sxu三种情感词典和uci、weibo数据集下的参数设置
需要说明的是,在模型学习过程中的一些参数设定和细节。表4展示了情感单元上下文传播框架的参数集记为φ={h,m,k,t,α,β}。其中h为种子情感单元选取算法中窗口的大小,它决定了特定的单元的上下文。m是种子情感单元的数量。k是情感传播图的情感单元的数量,它影响迭代次数和计算的稳定性。t是迭代的次数。score(t)的收敛性直接取决于情感传播矩阵
图7和图8展示了通过5折交叉验证得到的情感词典的一致率情况。通过情感标签传播,得到显式和隐式情感特征的情感极性和强度。一致率指的是两个情感词典中情感特征和极性都一致的百分比。不同的数据集产生的情感词典的规模是不一致的,因此一致率混淆矩阵是不对称的。综合5折交叉验证的数据集产生的情感词典作为最终的情感词典。特别地,本发明使用投票的方法来确定情感特征最终的情感倾向。
表5生成的情感词典包括四种词性及百分比
表5展示了在uci和weibo数据集下生成的情感词典细节。从表5可以发现,uci情感词典包含11428个情感特征,其中8665个显式情感特征和2763个隐式情感特征。weibo情感词典包含24415个情感特征,其20189个显式情感特征和4226个隐式情感特征。通用的情感词典中大多数是动词和形容词,而名词性的情感特征在生成的uci和weibo微博特定的情感词典中分别占2763(24.2%)和4226(17.5%)。这表明隐式的情感特征是微博情感表达中的主要情感指示。诸如“胡乱地”、“幸好”和“节俭地”等少量的副词同样也表达了情感倾向。副词的情感特征在uci情感词典中占185(1.6%),在weibo情感词典中308(1.3%)。在两种情感词典中,负面的情感特征要多余正面的情感特征。负面和正面的特征在uci情感词典中分别占6322(55.2%)和5106(44.8%),在weibo情感词典中12935(53.0%)和11480(47.0%)。
表6和表7展示了本发明提出的方法和基线系统在uci和weibo数据集的情感分类结果,图11和图12展示了整体准确率对比情况。可以看出sucpf方法较其他五种基线方法在准确率上均有提升。例如,sucpf方法在sxu词典和uci数据集下较基准方法分别提高7.1%、4.8%、5.9%、5.4%、4.5%和6.2%,在sxu词典和weibo数据集下较基准方法分别提高了14.5%、2.9%、4.2%、6.4%、5.3%和5.1%。这表明sucpf能够得到更好的情感词典和情感分类结果。这主要是因为提出的sucpf框架是一种利用已有的情感词典和人工标注的半监督框架。sucpf方法使用局部上下文、主题特征和上下文关系来抽取显式和隐式的情感特征。
表6在三种通用情感词典在uci数据的情感分类结果
图9和图10展示了在两个微博数据集上抽取的50个名词性情感特征。可以发现,这些词表达强烈地暗示着积极或消极的情感和观点。不同的微博数据集有相同的隐式情感特征,例如“坏蛋”、“流弊”和“香菇”。本发明同样能发现新的情感特征,包括显式的情感特征例如“坏蛋”、“神粳病”和“弱者”,隐式的情感特征例如“救火队员”、“潮男”和“行业病”。这表明用户习惯于在微博等社会媒体中使用隐式特征来间接地表达他们对于产品、服务等情感。本发明有很好的领域适应性和对于显式和隐式情感特征的识别能力。
综上所述,本发明的使用一种规则和统计相结合的策略来构建包含显式情感
表7在三种通用情感词典在weibo数据的情感分类结果
特征和隐式情感特征的微博特定情感词典,与同类代表性方法相比,其总体计算准确度更高,具有更高的稳定性,可以有效地构建领域特定的情感词典,准确抽取显式和隐式情感特征。
本文结合说明书附图和具体实施例进行阐述只是用于帮助理解本发明的方法和核心思想。本发明所述的方法并不限于具体实施方式中所述的实施例,本领域技术人员依据本发明的方法和思想得出的其它实施方式,同样属于本发明的技术创新范围。本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!