适用于广域网的分布式交通大数据并行聚类方法与流程
本发明属于数据处理技术领域,特别涉及适用于广域网的分布式交通大数据并行聚类方法。
背景技术:
大数据分布式地存储在广域网环境里,对结构复杂、总量巨大(达到tb甚至pb级别)的数据进行移动集中后再进行传统的基于局域网的并行化聚类运算,因时间、金钱和设备等成本无法直接适用。而利用抽样降低数据规模,使用降维减少数据复杂度,都对聚类结果的准确性有影响。这就亟需我们改变本地局域网传统的聚类挖掘方法,从而使得数据聚类的效率和准确率得到提高。
在实际应用方面,电动车群体行为模式的分布式交通大数据的聚类问题是亟待解决的问题。目前是交通事故高发时期,电动车已成为新的道路交通安全隐患,由于电动车违规引起的事故占相当比例,如果能发现电动车违规的群体行为模式并制定相应的应对方案,就能有效地控制电动车违规事件的发生,使得交通事故得到减少。
违规的电动车数据能从监控录像得到,同时对图像处理后还能得到当时路面上一起等待过马路的电动车数量、路口逆行、违反规定载物、超载、超速、走机动车道等信息,而该路段的车速及红灯时长和路面宽度等信息是已知的。每个违规的电动车都必然有这些维度的信息,同时每个地方都有很多电动车违规的数据,但是若从整个国家的层面上挖掘电动车违规的群体行为模式却必须面对大数据的广域网内拷贝移动问题,十分有必要发明一个卓有成效的分布式交通大数据并行聚类方法。
技术实现要素:
针对上述现有技术存在的问题,本发明提出一种适用于广域网的分布式交通大数据并行聚类方法。
本发明处理的对象是分布式地存储在广域网的大数据,提出一个适用于广域网的基于mapreduce的分布式并行聚类计算框架,同时在实际应用中基于该框架优化改进聚类算法,使得聚类计算在广域网内跨节点能分布式并行执行与增量执行,大数据的分布式并行聚类运算按时序周期分为历史全量阶段和多个周期增量阶段持续执行。实现对历史全量大数据的分布式并行聚类运算,挖掘出群体行为模式后再用多个增量大数据的聚类运算不断地修正聚类结果。
本发明采用的技术方案如下:
1.最大最小距离法优化k-means聚类算法
设待聚类数据集r={rp|p=1,2,…,n},数据记录rp的属性个数是q,则rp={rp1,rp2,…,rpq}。
为了避免k-means算法随意选择过于邻近的初始中心点,提高聚类质量,对其用最大最小距离法进行优化,得到k个初始聚类中心。具体方法如下:
从待聚类数据集r中随意选择一个数据记录作为第一个聚类中心z1,分别计算待聚类数据集r中其它数据记录到z1的欧式距离,其中欧式距离最大的数据记录作为第二个聚类中心z2;然后分别计算已确定的聚类中心到待聚类数据集r中其余各个数据记录的最小欧式距离,并从中找出最大值,若该最大值大于λ×|z2-z1|,其中λ是检验参数,0<λ<1,则对应的数据记录作为第三个聚类中心z3;以此类推迭代若干次,直到再也找不出最大值大于λ×(|z2-z1|+|z3-z2|+…+|zk-zk-1|)/(k-1)的数据记录为止。
用以上最大最小距离法获得的k个数据记录作为k-means算法的初始聚类中心,记为z1,z2,…,zk,聚类中心zj=(zj1,zj2,…,zjq)所在的类用cj表示,其中j∈[1,k]。
step1:用下面的公式(1)计算数据集r中的各个数据记录rp到各个聚类中心zj的欧式距离d(rp,zj),把各个数据记录划分到距离最小的类,获得新类cj。
step2:用下面公式(2)计算新类cj的聚类中心zj。
其中nj是类cj中的数据记录个数,rp∈cj。
step3:用下面的公式(3)计算本次迭代的聚类质量评估函数j(t)。
其中d(rp,zj)表示数据记录rp与所属子类cj的聚类中心zj的欧式距离。
step4:上一次的聚类质量评估函数j(t-1)和本次的j(t)比较,如果两者之差满足给定阈值,则结束算法;否则返回到step1继续执行聚类迭代操作。
2.基于mapreduce的分布式并行聚类计算框架
2.1适用于广域网的基于mapreduce的分布式并行聚类计算,其实现的基本思想是:
2.2每个数据源节点里的数据分为多个数据块。
2.3每个数据块的聚类运算各由一个map运算负责,把数据块里的全部数据记录根据指定的聚类策略进行归并聚类;
2.4在数据源节点本地由combine运算把map运算所得聚类结果合并起来得到数据规模较小的中间结果;
2.5所有数据源节点把中间结果都传输到中心节点,在该中心节点上用reduce运算把所有中间结果合并为全局聚类结果。
2.6若达到最大迭代次数或全局聚类结果收敛,则结束,输出最终聚类结果;否则reduce把比较参数输出并分发到各个数据块,从步骤2.3开始进行新一轮聚类分析,继续下一次迭代。
3.历史全量大数据分布式并行聚类运算
历史全量阶段聚类运算处理的对象是数据源节点已有的全量数据,其具体步骤如下:
3.1把数据源节点dsi(i=1,2,…,n)已有的数据分为m个数据块dbi1,dbi2,…,dbim。
3.2对每个数据块dbij用最大最小距离法优化kmeans聚类算法进行map运算,根据给定的策略将dbij里全部数据记录进行归并聚类,得到各个数据块的本地聚类结果。
3.2.1历史全量大数据的map运算
map运算的目标是用最大最小距离法优化kmeans聚类算法,实现数据块dbij里数据记录的类别划分。具体步骤如下:
a、读取数据块dbij的数据记录,用<key1,value1>键值对表示,key1是数据记录rp在输入数据中的位移,value1是数据记录rp的信息(rp,1,rp,2,…,rp,q)。
b、用上述的最大最小距离法得到数据块dbi,j的k个初始聚类中心点。
c、从分布式缓存(distributedcache)中读取上一轮聚类迭代获得的k个聚类中心点,首轮聚类时为上述k个初始聚类中心点。
d、分别计算每个数据记录rp与k个聚类中心点之间的欧式距离,找出离该记录欧式距离最近的聚类中心点,同时将该聚类中心点的编号id作为key2,该数据记录信息作为value2输出。
3.3数据源节点dsi所有数据块的聚类结果由combine运算在本地进行归并,获得的局部聚类中间结果数据量较小。
3.3.1历史全量大数据的combine运算
所有本地数据块dbi,j经过各自的map运算处理后会产生大量的key2值相同的<key2,value2>键值对数据,为了降低网络通信开销,各数据源本地分别用combine运算并行地合并本地相同的键值对。具体步骤如下:
a、输入<key2,value2>,key2为聚类中心点id,value2为具有相同聚类中心点id的数据对象;
b、将key2值相同的该类簇包含的所有数据记录的各维属性之和分别累加得到rp1之和、rp2之和、…、rpq之和;
c、得到<key3,value3>输出,key3为本地聚类中心点id,value3为每个类簇包含的数据记录的个数count与该类簇包含的所有数据记录的各维属性和vectorsum。
3.4全部数据源节点的中间结果传送到中心节点用reduce运算进行二次合并归约操作,并获得全局聚类结果。
3.4.1历史全量大数据的reduce运算
所有数据源节点的中间结果<key3,value3>经过广域网传输到中心节点,进行reduce运算,即二次合并所有数据源节点相同key值的数据,并生成新的聚类中心。具体步骤如下:
a、中心节点通过广域网接收所有数据源节点经过combine运算后得到的局部聚类中间结果。
b、在中心节点对于聚类中心点id相同(即同一类簇)的来自不同数据源节点的所有数据记录分别累加value值,获得同一类簇的所有数据记录的个数和allcount与该类簇包含的所有数据记录的各维属性和allvectorsum。
c、按下面公式(4)求均值,分别得到各个类簇的新聚类中心点newcenter:
3.5若迭代次数达到最大值gmax或全局聚类结果收敛,则输出聚类结果并结束;否则,在中心节点通过广域网发送新聚类中心到所有数据源节点中的每个数据块,返回步骤3.2进行新一轮并行聚类迭代操作。
4.周期增量大数据分布式并行聚类运算
周期增量阶段聚类运算处理的对象是数据源节点每个周期的增量数据,基于已有聚类结果对增量分块数据做并行聚类运算,具体步骤如下:
4.1把数据源节点dsi(i=1,2,…,n)当前周期内对应的增量数据分别分为δm个增量数据块δdbi,1,δdbi,2,…,δdbi,δm(常常δm<m)。
4.2根据步骤3历史全量阶段或上一周期增量阶段得到的聚类结果,用map运算来对每个增量数据块δdbi,j里的每一条数据记录与若干个已获得的聚类中心的距离进行并行计算。按照距离最小原则将所得距离满足约束条件的数据记录分配到对应类,具体方法为:
4.2.1周期增量大数据的map运算
设前一个周期增量或历史全量阶段的聚类运算获得k个类,聚类中心表示为zj(j=1,2,…,k),周期增量大数据map运算的具体步骤如下:
a、将每个增量数据块δdbi,j里的数据记录δrp表示为δrp=(δrp1,δrp2,…,δrpq)。
b、分别计算k个聚类中心与δrp的欧式距离。
c、与给定的领域半径δ比较,若k个距离都小于δ,将δrp归并到与其最近的类;否则将δrp作为孤立点丢弃。
4.3数据源节点dsi里当前所有数据记录(包括当前周期增量数据、前序周期增量数据和历史全量数据)根据所属类,通过combine运算并行地对每个类在该节点的局部偏离误差进行计算。
4.3.1周期增量大数据的combine运算
设数据源节点dsi(i=1,2,…,n)的聚类中心zj(j=1,2,…,k)表示为zj=(zj,1,zj,2,…,zj,q),聚类中心zj所在的类用cj表示,周期增量大数据的combine运算的具体步骤如下:
a、计算数据源节点dsi内被划分到类cj的数据记录总数
b、用下列公式(5)统计得到类cj的局部偏离误差和:
c、数据源节点dsi通过广域网传输k个
4.4步骤4.3.1全部数据源节点的局部偏离误差传送到中心节点后,在该节点通过reduce运算根据对应类进行合并,得到每个类的跨数据源节点的全局偏离误差。
4.4.1周期增量大数据的reduce运算
周期增量大数据的reduce运算的具体步骤如下:
c、中心节点通过广域网接收类cj在所有数据源节点的局部偏离误差
d、类cj的全局偏离误差
i表示数据源节点个数,i=1,2,…,n;j表示聚类个数,j=1,2,…,k;
c、若
本发明的优点:
1、本发明基于mapreduce模型的三个运算map、combine和reduce,对优化改进后的聚类算法实现了在广域网内分布式的并行执行,在数据源节点并行完成计算复杂度难的步骤,获得的聚类结果又在数据源节点里被合并成较小数据量的中间结果后再传输到中心节点,移动的数据量大大减少了,数据移动的成本也降低了,运算的效率也得到了提高;
2、本发明方法先做历史全量大数据的分布式并行聚类运算,得到聚类结果后,再定期对多个增量大数据基于已有的聚类结果进行聚类运算,从而避免了已归类的历史大数据的重复聚类,使得周期增量阶段需要聚类的数据规模极大缩减了,同时计算复杂度也大大降低了,聚类运算性能得到了极大的提高。
附图说明
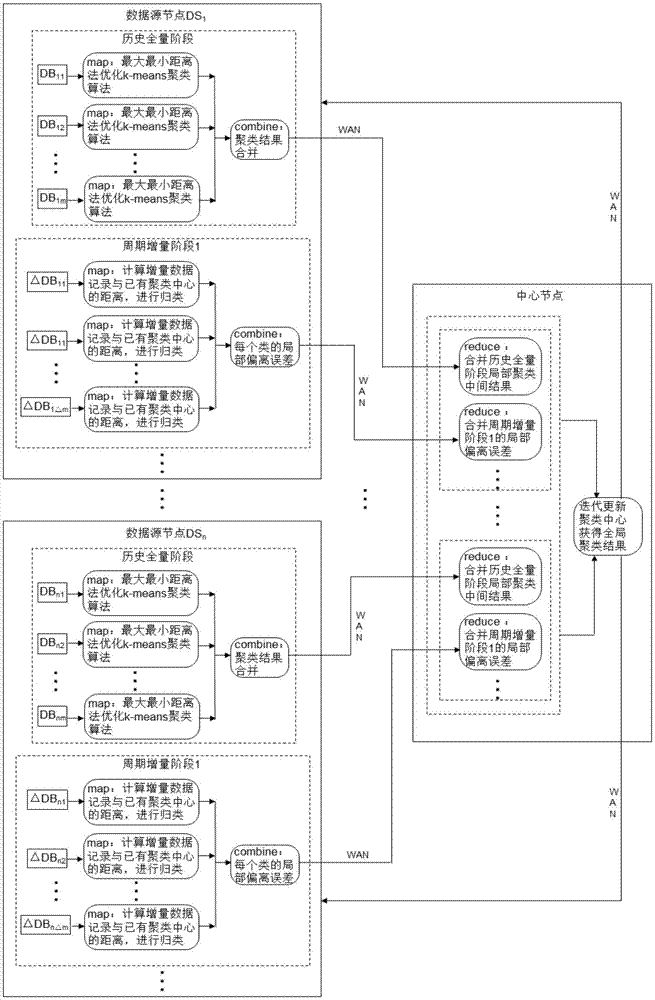
图1是本发明方法的流程图。
图2是本发明方法实施例和现有技术方法聚类准确率对比图。
图3是本发明方法实施例和现有技术方法聚类算法执行时间对比图。
具体实施方式
下面结合具体实施例和附图,对本发明的技术方案作进一步完整、清楚地描述,应当理解,这里所用的实施例只是为了解释本发明,并不是限制本发明。其它行业的分布式大数据群体行为模式的发现也可以用本发明的方法来实现。
本发明用电动车违规交通数据为例来说明本发明技术方案的具体实现方法。
由于电动车数量的不断增多,导致各种电动车违章现象不断出现,给交通安全带来了巨大的隐患,如果能发现电动车违章的群体行为模式,同时对症下药,避免电动车违章频繁发生,从而使得交通事故的发生能大大减少。这里,我们想发现全国的违章电动车的群体行为模式,也就是要对全国的违章电动车进行聚类,不需要把各个地区庞大的电动车违章数据汇总到一起后再进行统一聚类,本发明在各个地区就可以轻易地实现分布式的并行聚类。
电动车闯红灯、路口等待人数、路口逆行、违反规定载物、超载、超速、走机动车道等多发违法现象在全国各个地区可以通过交通管理部门的摄像头图像处理技术和交警处理后记录的电动车违法记录获得;路段实时平均车速、红灯时长、路口之间的距离、马路宽度等影响电动车是否违法的因素是交通部门已经掌握的数据。
用某省道路交通监控系统采集的电动车轨迹数据,选取a城市、b城市两个城市子系统分别记为数据源节点ds1和ds2,省会城市c为中心节点.ab两个城市到c的距离各是400千米、235千米,网络连接采用带宽为300mbps的专用网络,构建基于hadoop的mapreduce框架,服务器配置为xeone5-2603v31.6ghz6核,8gbddr4,1.2tb硬盘;ab两城市作为数据源节点各用3台服务器,而c城市作为中心节点用5台服务器。本实施例中的关键参数设置为:60个map运算(源节点数据采用均分,即把每个源节点的数据平均分成60块,每块对应一个map运算)、4个combine运算、4个reduce运算,最大迭代次数gmax值是10,领域半径δ为0.005。
参照图1,图1中,db11db12…db1m是数据源节点ds1(a城市道路交通监控系统采集的电动车违法轨迹数据)物理划分成的m个数据块(在本实施例中m的值是60),其它数据源节点类同;δdb11,δdb12,…,δdbiδm是数据源节点ds1当前周期内的增量数据分为δm个增量数据块,其它数据源节点类同,δm<m;wan为广域网。
电动车群体行为模式的分布式大数据并行聚类系统,包括历史全量阶段大数据并行聚类和周期增量阶段大数据并行聚类。
一、在mapreduce架构下历史全量阶段大数据并行聚类,包括以下步骤:
(一)迭代次数初始化:g=0;
(二)并行执行每一个数据源节点的每一个数据块dbij的map运算,得到数据块dbij的本地聚类结果<key2,value2>。具体步骤如下:
1、待聚类数据块dbij记为r,共有t个数据记录,则r=(r1,r2,…,rt)数据记录的属性维度为q,则第p个数据记录rp表示为rp=(rp,1,rp,2,…,rp,q),其中1<p<t。
2、各个map函数分别读取数据块dbi,j的数据记录,用<key1,value1>键值对表示,key1是数据记录rp在输入数据中的位移,value1是数据记录rp的信息rp=(rp,1,rp,2,…,rp,q)。
3、用最大最小距离法得到数据块dbi,j的k个初始聚类中心点,记为z1,z2,…,zk,聚类中心zj=(zj1,zj2,…,zjq)所在的类用cj表示,其中j∈[1,k]。具体步骤如下:
①从r(即数据块dbij)中随意选择一个数据记录作为第一个聚类中心z1,假设选择的是r1,则z1=r1。
②计算r中所有数据记录到z1的欧式距离,第二个聚类中心z2就选择和z1欧式距离最大的数据记录。
③分别计算z1和z2到r中剩下的每个数据记录rp的欧式距离,记为d1p和d2p,找出z1和z2到rp的距离最小值记为min(d1p,d2p)。
④从min(d1p,d2p)中找出最大值记为max(min(d1p,d2p)),对应的数据记录记为rp。
⑤若λ×|z2-z1|<max(min(d1p,d2p)),则把rp当成第三个聚类中心z3;其中λ(0<λ<1)是检验参数。
⑥分别计算z1、z2和z3分别到r中剩下的每个数据记录rp的欧式距离,分别记为d1p、d2p、d3p,找出max(min(d1p,d2p,d3p))所对应的数据记录;
⑦若λ×(|z2-z1|+|z3-z2|)/2<max(min(d1p,d2p,d3p)),则max(min(d1p,d2p,d3p))所对应的数据记录就成为新的聚类中心z4,
⑧按步骤⑥至⑦方法类推迭代若干次,直到再也找不出最大值大于λ×(|z2-z1|+|z3-z2|+…+|zk-zk-1|)/(k-1)的数据记录为止。
用以上最大最小距离法获得的k个数据记录作为k-means算法的初始聚类中心,记为z1,z2,…,zk,聚类中心zj=(zj1,zj2,…,zjq)所在的类用cj表示,其中j∈[1,k]。
4、从分布式缓存(distributedcache)中读取上一轮聚类迭代获得的k个聚类中心点(首轮聚类时为k个初始聚类中心点)。
5、分别用下面公式(1)计算数据块中每个数据记录rp与k个聚类中心点zj=(zj1,zj2,…,zjq)之间的欧式距离d(rp,zj),找出离该记录距离最近的聚类中心点,同时将该聚类中心点的编号id作为key2,该数据记录信息作为value2输出。
(三)在每一个数据源节点,并行执行如下的combine运算,合并同一个数据源节点中不同数据块dbij的map运算的输出结果。具体步骤如下:
1、输入<key2,value2>,key2为聚类中心点id,value2为具有相同聚类中心点id的数据对象。
2、将key2值相同的该类簇包含的所有数据记录的各维属性之和累加到一起得到rp1之和,rp2之和,…,rpq之和;
3、得到<key3,value3>输出,key3为本地聚类中心点id,value3为每个类簇包含的数据记录的个数count与该类簇包含的所有数据记录的各维属性和vectorsum。
(四)在中心节点并行执行reduce运算,获得全局聚类中心。
1、中心节点通过广域网接收所有数据源节点经过combine运算后得到的局部聚类中间结果。
2、在中心节点对于聚类中心点id相同(即同一类簇)的来自不同数据源节点的所有数据记录分别累加value值,获得同一类簇的所有数据记录的个数和allcount与该类簇包含的所有数据记录的各维属性和allvectorsum。
3、按公式(4)求均值,得到各个类簇的新聚类中心点newcenter,该聚类中心点就是全局聚类中心。
(五)、迭代次数g加1;
(六)、在中心节点用下面的公式(3)计算本次迭代的聚类质量评估函数j(t)。
其中d(rp,zj)表示数据记录rp与所属子类cj的聚类中心zj的欧式距离,nj是类cj中的数据记录个数,rp∈cj。
(七)、上一次的聚类质量评估函数j(t-1)和本次的j(t)比较,如果两者之差满足给定阈值或迭代次数g大于最大值gmax,则输出聚类结果并结束;否则,在中心节点通过广域网发送新聚类中心到所有数据源节点中的每个数据块,然后返回步骤(二)中的第4步重新进行下一轮并行聚类迭代操作。
二、在mapreduce架构下对每一个周期增量阶段大数据并行聚类,包括以下步骤:
(一)接收前一个周期增量或历史全量阶段的聚类运算获得的k个类,聚类中心记为zj(j=1,2,…,k)。
(二)并行执行每个增量数据分块δdbi,j的map聚类运算。用map运算来对每个增量数据块δdbi,j里的每一条数据记录与若干个已获得的聚类中心的距离进行并行计算。按照距离最小原则将所得距离满足约束条件的数据记录分配到对应类。具体步骤如下:
1、读取数据块δdbi,j里的任一数据记录,该记录表示为δrp=(δrp1,δrp2,…,δrpq)
2、分别计算k个聚类中心与δrp的欧式距离d(δrp,zj),其中j∈[1,k]。
3、d(δrp,)与给定的领域半径δ比较,若k个距离都小于δ,根据min(d(δrp,z1),d(δrp,z2),…,d(δrp,zk))将数据记录归并到与其最近的类;否则将δrp作为孤立点丢弃。
4、从数据块δdbi,j再次随机读取另一个待聚类的数据记录δrp’,转到步骤2重新执行,直到δdbi,j里的所有数据记录都处理完毕。
5、输出δdbi,j的聚类结果(zj,δrp)。
(三)并行执行每个数据源节点dsi的combine运算,统计每个类在该节点的局部偏离误差和,通过广域网传输k个
设数据源节点dsi(i=1,2,…,n)的聚类中心zj(j=1,2,…,k)表示为zj=(zj,1,zj,2,…,zj,q),聚类中心zj所在的类用cj表示。
并行combine运算具体步骤如下:
1、计算数据源节点dsi内被划分到类cj的数据记录(包括当前周期增量数据、前序周期增量数据和历史全量数据)总数
2、用下列公式(8)统计得到类cj的局部偏离误差和:
3、数据源节点dsi通过广域网传输k个
(四)在中心节点并行执行reduce运算,通过该运算对类cj(j=1,2,…,k)进行合并,得到每个类的跨数据源节点的全局偏离误差
1、中心节点通过广域网接收类cj在所有数据源节点的局部偏离误差。
2、类cj的全局偏离误差
其中,i表示数据源节点个数,i=1,2,…,n;j表示聚类个数,j=1,2,…,k
3、若
4、输出周期增量聚类结果,整个算法结束。
三、比较实验:
方法1:把ab两城市的所有数据分别移动到中心节点c城市,集中存储于c城市某局域网中的5台服务器,再进行传统的基于局域网的并行化聚类运算,即在中心节点的5台服务器上并行执行map运算,完成该运算后再直接reduce运算。
方法2:基于各自节点的全量数据,在ab两城市节点各采用的3台服务器上并行执行map运算和combine运算,把combine运算得到的局部聚类结果传送到c城市这个中心节点,同时在中心节点的服务器上执行reduce运算得到全局聚类结果。
方法3:在方法2的基础上使用本发明方法。
三种方法都是基于hadoop的mapreduce框架,用平均分配到服务器上的map运算、combine运算和reduce运算实现聚类算法的并行化,所以三种方法的并行加速能力基本相同,因此主要比较当数据量规模增长时聚类的时间和正确率的变化。三种方法聚类结果如下表1所示:
表1三种方法聚类结果
表1中数据量是指参加并行聚类的数据记录条数,移动时间(指将数据从ab两个城市分别移动集中到中心节点c城市的总时间)、map运算、combine运算、reduce运算和总时间的单位为小时h,聚类准确率是%。
对比三种方法的聚类准确率,从图2可以看出,当数据量相同时三种方法的聚类准确率也大致相等,同时聚类准确率随着数据量的增大逐步提高,得到结论:决定聚类准确率的重要因素是参加聚类的数据量规模。这也就从另一方面说明了企图用降维抽样来降低数据规模以达到提高计算效率的方法必然会牺牲聚类准确率,而对全量数据做聚类是确保准确率的有效方法。
再对三种方法的聚类总时间比较,如图3所示,本发明方法通过使用广域网的分布式增量大数据并行聚类机制,其聚类运算总时间比方法1减少64.55%,比方法2减少39.65%,计算效率提高异常明显。因此,本发明方法能避免大数据在广域网内拷贝移动和重复聚类运算,是分布式存储环境下能提高大数据挖掘性能的有效方法。
四、对本发明方法聚类结果的分析与决策
对最终获得的全局聚类结果进行分析后,得到全国电动车违法违章的群体行为类型,依据不同的行为模式特点,找出有效的解决方案,如路口的位置设置得更合理、根据道路交通状况调整红绿灯时长等。
再有,把获得的全局聚类结果通过广域网传输回到各个地方后,通过与地方的局部聚类结果比较后,可以得到地方电动车违法行为群体模式与全国电动车违法行为群体模式的差异。
再有,把获得的全局聚类结果通过广域网传输回到各个地方后,通过与地方的局部聚类结果比较后,可以得到地方电动车违法行为群体模式与全国电动车违法行为群体模式的差异。
- 还没有人留言评论。精彩留言会获得点赞!