一种配送方法和装置与流程
本申请涉及物流
技术领域:
,特别涉及一种配送方法和装置。
背景技术:
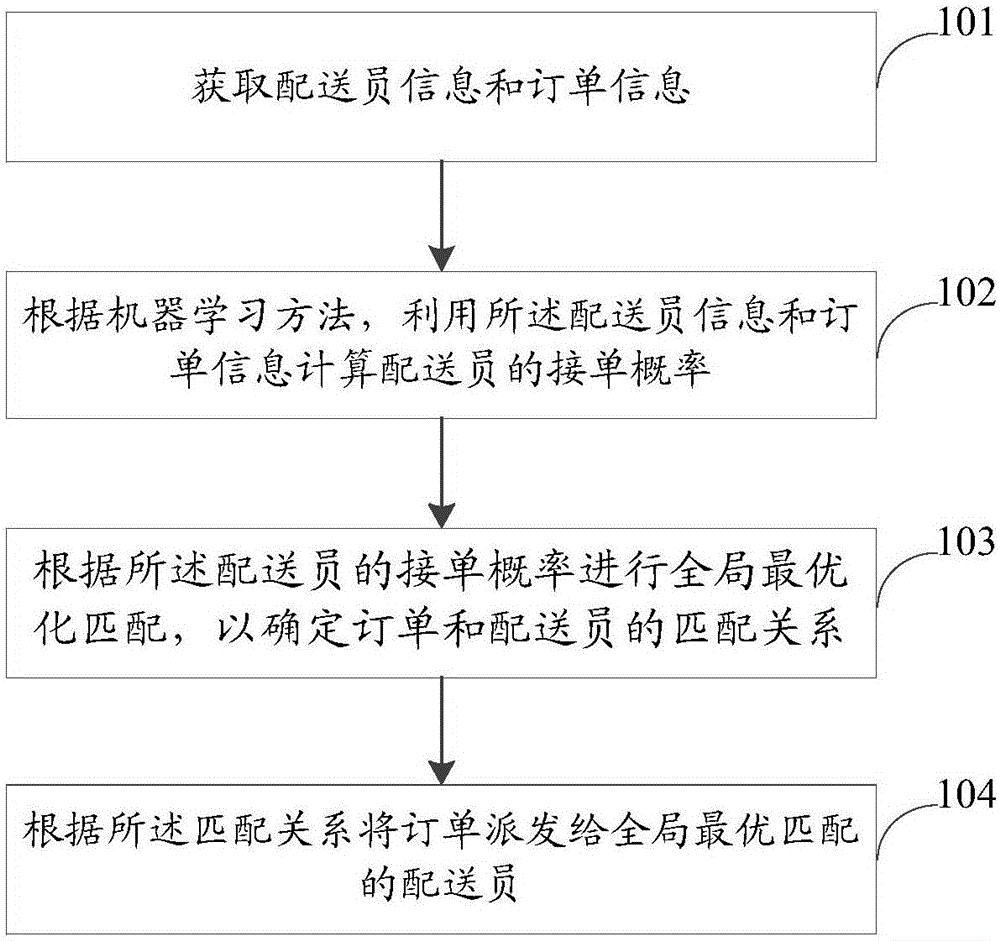
:随着社会信息化技术的发展,人们受互联网的影响越来越大,很多经济活动都通过线上交易。特别是普通的日常生活也往往通过网络交易,比如包裹快递、订餐等。以订餐配送为例,由于客户流分散,实时需求程度高,需求时间段集中等特点,如何合理利用资源、优化订单分配、提高配送效率以满足客户需求是目前需要解决的问题。技术实现要素:本申请实施例提供了一种智能配送派单的方法,可以实现全局最优化匹配,优化资源的分配和利用。具体的,本申请实施例为:一种智能配送派单的方法,该方法包括:获取配送员信息和订单信息;根据机器学习方法,利用所述配送员信息和订单信息计算配送员的接单概率;根据所述配送员的接单概率进行全局最优化匹配,以确定订单和配送员的匹配关系;根据所述匹配关系将订单派发给全局最优匹配的配送员。进一步地,所述配送员信息包括配送员位置信息,所述订单信息包括收发货位置信息。进一步地,,所述根据机器学习方法,利用所述配送员信息和订单信息计算配送员的接单概率的方法包括:事先设置特征权重向量和偏置值;根据设置的损失函数和所述特征权重向量迭代计算更新所述特征权重向量;在增长函数中利用所述特征权重向量和偏置值计算得到配送员的接单概率。进一步地,,根据所述配送员的接单概率进行全局最优化匹配,以确定订单和配送员的匹配关系方法包括:根据事先设置的匹配加权值对所述配送员的接单概率进行加权计算,得到配送员匹配评估值;根据所述配送员的匹配评估值和分配策略分值计算匹配总和值,将匹配总和值最高时对应的分配策略作为最优化的分配策略,根据最优化的分配策略确定订单和配送员的匹配关系。本申请实施例还提出一种智能配送派单的装置,该装置包括:信息获取单元,用于获取配送员信息和订单信息;接单概率预测单元,用于根据机器学习方法,利用所述配送员信息和订单信息计算配送员的接单概率;匹配单元,根据所述配送员的接单概率进行全局最优化匹配,以确定订单和配送员的匹配关系;订单派发单元,根据所述匹配关系将订单派发给全局最优匹配的配送员。进一步地,,所述接单概率预测单元包括:概率计算子单元,在增长函数中利用特征权重向量和偏置值计算得到配送员的接单概率;特征权重向量迭代子单元,根据设置的损失函数和所述特征权重向量迭代计算更新所述特征权重向量。进一步地,所述匹配单元包括:匹配评估单元,用于根据事先设置的匹配加权值对所述配送员的接单概率进行加权计算,得到配送员匹配评估值;全局最优匹配计算单元,根据所述配送员的匹配评估值和分配策略分值计算匹配总和值,将匹配总和值最高时对应的分配策略作为最优化的分配策略,根据最优化的分配策略确定订单和配送员的匹配关系。应用本申请公开的技术方案,由于利用机器学习方法更为准确地计算出接单概率,并从全局角度考虑最优分配效果,从而最大效率利用资源,优化订单分配,实现智能派单。附图说明图1是本发明实施例一的智能配送派单的方法流程图。图2是本发明实施例一对应的装置结构示意图。图3是本发明实施例二中计算配送员接单概率的方法流程图。图4是本发明实施例二中接单概率预测单元202的内部结构示意图。图5是本发明实施例二中根据全局最优话匹配方法确定匹配关系的方法流程图。图6是本发明实施例二中匹配单元203内部结构示意图。具体实施方式为使本申请的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本申请作进一步详细说明。图1是本发明实施例一的智能配送派单的方法流程图。如图1所示,该方法包括:步骤101:获取配送员信息和订单信息。步骤102:根据机器学习方法,利用所述配送员信息和订单信息计算配送员的接单概率。步骤103:根据所述配送员的接单概率进行全局最优化匹配,以确定订单和配送员的匹配关系。步骤104:根据所述匹配关系将订单派发给全局最优匹配的配送员。图2是本发明实施例一对应的装置结构示意图。如图2所示,该装置包括:信息获取单元201、接单概率预测单元202、匹配单元203、订单派发单元204。其中,信息获取单元201用于获取配送员信息和订单信息;接单概率预测单元202用于根据机器学习方法,利用所述配送员信息和订单信息计算配送员的接单概率;匹配单元203根据所述配送员的接单概率进行全局最优化匹配,以确定订单和配送员的匹配关系;订单派发单元204根据所述匹配关系将订单派发给全局最优匹配的配送员。也就是说,本发明实施例一中,可以利用机器学习方法计算出配送员的接单概率,利用这个接单概率将配送员和订单进行匹配,将全局最优匹配的配送员作为需要下发订单的配送员。由于本实施例派单的方法考虑了全局最优效果,可以为客户、配送员和商家几方面进行综合考虑,可以最大效率利用资源,优化订单分配。当然,由于优化了订单分配,从而可以从总体上提高配送效率。实际应用中,配送员信息可以包括其位置信息,订单信息可以包括收发货位置信息。位置信息可以用经纬度表示,用现有的gps技术就可以获取。当然,配送员信息还可以包括其他信息,比如:是否处于工作状态、配送员接单偏好、配送员等级、配送员标签、配送员接单权限、配送员未完成订单情况、配送员当前时间推荐的订单量、配送员当天完成的订单量、配送员被屏蔽的情况、配送员最近历史接单情况等等。订单信息还可以包括其他信息,比如:将要分配订单的时效、配送员未完成订单的时效、订单的商家id号、订单货物类型。实际应用中,至于配送员信息和订单信息究竟包括哪些信息是由应用本发明实施例方案的用户自行确定的,并不受本发明实施例的限定。由于配送员(m个)和订单(n个)的数量很庞大,可以事先过滤部分无关信息,减少计算量。比如,可以先将m个配送员和n个订单交叉配对,初步形成匹配关系。然后根据获取的配送员信息和订单信息进行信息筛选,将如下情况相关的匹配过滤掉:当前不处于工作状态的配送员、不接受该订单货物类型的配送员、接单偏好不匹配的订单、路线偏差大的订单、被商家屏蔽的配送员、无接单权限的配送员、当前订单量饱和的配送员等等。将这些信息过滤的目的是减少计算量。当然,如果不考虑计算量的问题,也可以不事先过滤。本发明实施例二为如何实现上述步骤102提供了具体的机器学习的方案。本领域技术人员知道,机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。图3是实现步骤102的具体方法流程图。如图3所示,该方法中机器学习计算配送员接单概率的方法包括:步骤301:事先设置特征权重向量和偏置值。步骤302:根据设置的损失函数和所述特征权重向量迭代计算更新所述特征权重向量。步骤303:在增长函数中利用所述特征权重向量和偏置值计算得到配送员的接单概率。这里所述的特征权重向量、偏置值、损失函数、增长函数是机器学习中涉及到的技术特征。图4是该方法对应的装置示意图,即接单概率预测单元202的内部结构示意图。如图4所示,该装置包括:概率计算子单元401和特征权重向量迭代子单元402。其中,概率计算子单元401用于在增长函数中利用特征权重向量和偏置值计算得到配送员的接单概率。特征权重向量迭代子单元402根据设置的损失函数和所述特征权重向量迭代计算更新所述特征权重向量。这里的特征权重向量是机器学习中需要学习的各种特征对象所设置的权值,偏置值是一个预先设置的数值,损失函数是在机器学习形成稳定模型时需要的,增长函数是用来计算接单概率的模型。假设在机器学习模型训练中可以利用特征对象很多,比如上述的各种配送员信息以及订单信息。机器学习的模型也有很多,比如logistic、xgboost等。下面以logistic模型为例说明如何进行训练。在选取训练的特征对象时,通常可以考虑对象的变量属性。比如:时间变量是一个复合变量,可以包含日期和时刻,如2017年8月和18点10分。地址变量为复合变量,可以包含地址名称和经纬度。地址名称为离散型随机变量,经纬度为连续性变量,时间为周期性变量。通常可以选择一个主要特征,如何选择特征可以通过衡量该特征和将要被预测的变量最相关的情况来确定。衡量变量之间相关性的指标可以由皮尔逊系统和互信息来体现。其中,皮尔逊系统通常用来衡量两个连续性随机变量的相关性,计算出来的结果是线性相关的。如果既有连续性,又有离散型、周期型或复合型的变量,则可以选择互信息来衡量变量之间的相关性。在本实施例的logistic模型中,假设需要训练的特征对象为配送员位置信息、接单时间以及出发日期这三个变量。配送员接单概率设为y,配送员位置为x1,接单时间为x2,出发日期为x3,特征权重向量为wt,偏置值为b。那么,根据logistic模型可以得到:y=h(x)=sigmoid(wtx+b)(公式1)其中,对于样本(x1,y1),(x2,y2),......(xn,yn),其中y∈(0,1),表示将x1作为特征对象训练时得到接单概率y1,将x2作为特征对象训练时得到接单概率y2,将x3作为特征对象训练时得到接单概率y3。h(x)(y1,x1)表示x1和y1之间的相关性,h(x)(y2,x2)表示x2和y2之间的相关性,h(x)(y3,x3)表示x3和y3之间的相关性。假设计算后得到如表一所示的结果:h(x)(y1,x1)h(x)(y2,x2)h(x)(y3,x3)0.910.430.82表一从表一中可知,,得到的接单概率与x1的相关性最强,达到了0.91。因此,在实际应用中可选择配送员位置x1作为训练模型的最佳特征。也就是说,可以将问题简化为:计算在配送员位置这个特征下其对于该订单的承接概率,或者说,满足订单条件下配送员位置的概率分布。在模型中引入损失函数:利用公式1和公式2不断进行迭代:其中,wold表示迭代前的权重向量,wnew表示迭代后的权重向量。经过不断的迭代,可以得到趋于稳定的权重向量。这样,通过公式1的logistic模型计算,就可以得到可靠的配送员接单概率。本发明实施例二为如何实现上述步骤103提供了具体的匹配订单和配送员关系的方法。图5是实现步骤103的具体方法流程图。如图3所示,该方法中根据全局最优话匹配方法确定匹配关系的方法包括:步骤501:根据事先设置的配送员加权值对所述配送员的接单概率进行加权计算,得到配送员匹配评估值。实际应用中,计算匹配评估值时,还可以考虑配送员信息。如前所述,配送员信息可以包括配送员等级这类体现配送员业务成绩的信息,这里就可以利用配送员历史的业务成绩计算匹配分值。具体的,可以为接单概率和配送员信息分别设置匹配加权值,然后进行加权平均,以确定配送员的匹配分值。比如:某配送员a的接单概率为0.8,对应的加权值为18,其等级为“王者”,记5分,对应的加权值为1,则该配送员a获得的匹配分值应该为0.8*18+5*1=19.5分。这里考虑了配送员的业务成绩,实际应用中,也可以考虑其他信息或者仅考虑接单概率即可。步骤502:根据所述配送员的匹配评估值和分配策略分值计算匹配总和值,将匹配总和值最高时对应的分配策略作为最优化的分配策略,根据最优化的分配策略确定订单和配送员的匹配关系。这里所述的匹配分值即步骤501计算出来的匹配分值,分配策略分值是一个二值化的值,分配为1,不分配为0。假设:x1,x2,......xmi∈{1...m}表示有m个配送员;y1,y2,......ynj∈{1...n}表示有n个订单;αij表示配送员i和订单j之间的匹配分值;βij表示分配策略分值,βij=1表示将订单j分配给配送员i,βij=0表示不将订单j分配给配送员i。那么,目标函数f可以表示为:f=max∑i∑jαijβij(公式4)(约束:k为参数)也就是说,通过∑i∑jαijβij公式可以计算出所有的订单分配给不同配送员的匹配总和值,而max∑i∑jαijβij则是若干个匹配总和值中最高分值,或者说对应了一种最优化的分配策略。这种最优化的分配策略对应了将某个订单j分配给某个配送员i的匹配关系,也是一种最优化的匹配关系。图6是确定匹配关系对应的装置图,即匹配单元203内部结构示意图。如图6所示,该装置包括匹配评估单元601和全局最优匹配计算单元602。其中,匹配评估单元601,用于根据事先设置的匹配加权值对所述配送员的接单概率进行加权计算,得到配送员匹配评估值。全局最优匹配计算单元602,根据所述配送员的匹配评估值和分配策略分值计算匹配总和值,将匹配总和值最高时对应的分配策略作为最优化的分配策略,根据最优化的分配策略确定订单和配送员的匹配关系。确定最优的匹配关系之后,就可以将订单派发给全局最优匹配的配送员,实现配送任务。本发明实施例并不是单一从配送员接单概率或其它信息来考虑是否将某个订单分配给某个配送员,而是从全局角度出发考虑分配的合理性,使得整个系统在一段时间内的运行是最合理、最优化的。应用本发明各实施例方案,由于利用机器学习的方法可以更为准确地计算出配送员承接订单的概率,并通过全局最优化匹配方法将配送员和订单进行匹配,从而从整体上最大效率地利用资源。以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1