展示海量车辆位置分布信息的多层聚合方法及系统与流程
本发明涉及车辆位置展示技术领域,具体涉及一种展示海量车辆位置分布信息的多层聚合方法及系统。
背景技术:
共享单车等类似基于位置的监管平台,通常使用b/s架构(browser/server,浏览器/服务器模式),核心功能是基于电子地图,实时查看车辆的位置分布信息。根据这些信息,判断是否出现车辆供过于求、供不应求、进入禁停区、未按规定停放等现象,进而发出报警信息、进行线下处理等。目前单车监管平台,使用方主要是政府,用于监管共享单车的停放。
共享单车作为最常用的公众出行交通工具之一,具有非常明显的潮汐现象,分布也显现极端不均匀现象。比如上下班场景,上班高峰时间段,大量车辆从各个方向聚合到地铁站;下班高峰时间段,车辆则往各个方向驶离地铁站;其它时间段,车辆则通常较少移动。车辆活跃率有明显的高峰低谷。
正因如此,在查看车辆分布信息时,会遇到以下问题:
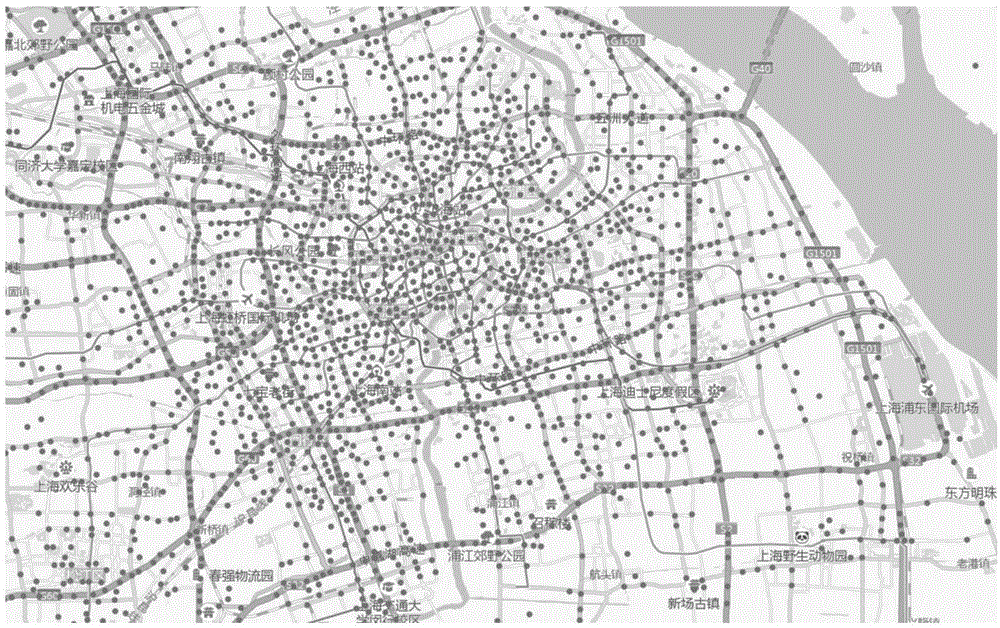
1、车辆太多,直接展示车辆分布,信息不够聚焦;比如上海总共约150万辆共享单车,展示效果如图1所示。
2、高峰时,车辆太密集,缺乏量化数据;
3、客户端频繁渲染海量实体点,导致系统负载非常高,甚至出现浏览器崩溃等现象。
现有技术方案可以通过热力图方式,起到“定性”作用,一目了然地展示车辆聚集区域。相比直接展示车辆分布信息,使用热力图能比较方便地查看车辆堆积的情况。颜色越深,则车辆堆积更严重,如图2所示,比较直观。
通过热力图的方式,能够一目了然地展示车辆聚集区域。但是对于单车监管平台,需要的不仅仅是“定性”,更多是需要“定量”。监管的目的是发现问题,并通知相关的人员去解决问题。因此需要准确地获取详细地址(如xx地铁站等)、车辆总数等信息。
技术实现要素:
本发明主要解决的技术问题是更友好、更快速地展示海量车辆的位置分布信息。
“更友好”具体体现在大范围时(如全上海或各行政区)聚合统计及小范围时(某个路口、某个白色停车区、某个公园)详情分布两种技术相结合,实现“粗中有细”、“粗能到细”、“能粗能细”;
“更快速”具体体现在面对海量离散不均匀分布车辆(大于100万)位置数据展示时,未出现明显统计及展示延迟(低于1秒)。
本发明采用的技术方案如下:
本发明提供了一种展示海量车辆位置分布信息的多层聚合方法,所述多层聚合方法包括以下步骤:
浏览器端提交当前地图视窗的范围、地图缩放级别参数,向服务端发起聚合数据请求,获取各个行政区域的聚合数据;
浏览器端继续提交当前地图视窗的范围,当浏览器端的地图缩放级别超过街道后,不再使用服务端的聚合数据,向服务端发起车辆位置信息请求,从服务端获取当前地图视窗范围内车辆数据;
服务端向浏览器端返回车辆数据,浏览器端收到返回的车辆数据后,根据四叉树算法进行浏览器聚合。
进一步地,所述聚合数据包括行政区域名、区域码、车辆总数信息。
进一步地,所述车辆数据包括车辆编号、车辆品牌、车辆位置信息。
进一步地,所述服务端包含车辆表、行政区域表和车辆所在区域表,所述车辆表存储车辆的信息,所述行政区域表存储行政区域的信息,所述车辆所在区域表存储所有车辆与行政区域的关系信息。
进一步地,当服务端收到浏览器端发起的聚合数据请求时,按照以下步骤执行服务端聚合操作:
通过行政区域表查询出在当前地图视窗范围中的行政区域;
通过车辆所在区域表聚合出各个行政区域内的车辆总数。
进一步地,当服务端收到浏览器发起的车辆位置信息请求时,执行sql语句,查询出当前地图视窗范围中的所有车辆及车辆位置信息。
进一步地,浏览器端根据服务端返回的结果集list,总数量count、行政区域预定义最多展示的总数量max,共同决定是否进行浏览器聚合。
进一步地,浏览器端决定是否进行浏览器聚合具体包括以下步骤:
如果count小于或等于max,此时还在浏览器的直接渲染能力之内,直接展示各个车辆位置详情;
如果count大于max,决定执行浏览器聚合:首先将当前地图视窗分成左上lt、左下lb、右上rt、右下rb四个相等的细分区域,并循环结果集list,将结果集list中的所有点重新计算、划分到四个细分区域中,得到list′、count′、max′;
基于四个细分区域,如果一个细分区域的总数量count′小于或等于max,则直接展示各个车辆位置详情;如果大于max,则只展示聚合结果,不再展示各个车辆位置详情;
点击所述聚合结果,则循环执行以上步骤。
本发明还提供了一种展示海量车辆位置分布信息的多层聚合系统,所述多层聚合系统包括浏览器端和服务端,浏览器端提交当前地图视窗的范围、地图缩放级别参数,向服务端发起聚合数据请求,获取各个行政区域的聚合数据;浏览器端继续提交当前地图视窗的范围,当浏览器端的地图缩放级别超过街道后,不再使用服务端的聚合数据,向服务端发起车辆位置信息请求,从服务端获取当前地图视窗范围内车辆数据;服务端向浏览器端返回车辆数据,浏览器端收到返回的车辆数据后,根据四叉树算法进行浏览器聚合。
进一步地,浏览器端根据客户端返回的结果集list,总数量count、行政区域预定义最多展示的总数量max,共同决定是否进行浏览器聚合。
进一步地,浏览器端决定是否进行浏览器聚合具体包括以下步骤:
如果count小于或等于max,此时还在浏览器的直接渲染能力之内,直接展示各个车辆位置详情;
如果count大于max,决定执行浏览器聚合:首先将当前地图视窗分成左上lt、左下lb、右上rt、右下rb四个相等的细分区域,并循环结果集list,将结果集list中的所有点重新计算、划分到四个细分区域中,得到list′、count′、max′;
基于四个细分区域,如果一个细分区域的总数量count′小于或等于max,则直接展示各个车辆位置详情;如果大于max,则只展示聚合结果,不再展示各个车辆位置详情;
点击所述聚合结果,则循环执行以上步骤。
本发明还提供了一种存储器,所述存储器存储有计算机程序,所述计算机程序执行如下步骤:
浏览器端提交当前地图视窗的范围、地图缩放级别参数,向服务端发起聚合数据请求,获取各个行政区域的聚合数据;
浏览器端继续提交当前地图视窗的范围,当浏览器端的地图缩放级别超过街道后,不再使用服务端的聚合数据,向服务端发起车辆位置信息请求,从服务端获取当前地图视窗范围内车辆数据;
服务端向浏览器端返回车辆数据,浏览器端收到返回的车辆数据后,根据四叉树算法进行浏览器聚合。
本发明的有益效果在于可以更友好、更快速地展示海量车辆的位置分布信息,通过多层聚合方法,全方面达到“定量”目的:
1、服务端聚合。服务端首先按照行政区域进行聚合,行政区域通常包含省(直辖市)、市、区(县)、街道(镇)四层。
2、客户端聚合。对于街道以下展示区域,则使用四叉树算法,再次聚合。
附图说明
图1为现有技术车辆展示效果图;
图2为通过热力图展示车辆效果图;
图3为展示车辆位置的总览信息图;
图4为展示详细的车辆分布信息图。
图5为本发明多层聚合数据交互流程图;
图6为本发明服务端的主要数据结构图;
图7为本发明客户端聚合模型图。
具体实施方式
本发明使用者查看车辆分布信息时,根据电子地图的缩放级别(电子地图的比例尺),逐级展示不同的结果数据。比如上海市管理员登陆系统时,首先展示全上海的总览信息,如图3所示。
当缩放地图或者点击总览信息,则打开上海各区的聚合信息,以此类推,最终才展示详细的车辆分布信息,如图4所示。通过逐级展示的方式,控制了每次展示的信息总量,减少浏览器渲染压力。同时在数据不失真的前提下,做到了数据“定量”、信息聚焦。
下文中,结合附图和实施例对本发明作进一步阐述。
实施例一:
本发明提供了一种展示海量车辆位置分布信息的多层聚合方法,整个多层聚合过程,会涉及到“浏览器端”、“服务端”两个角色,如图5所示,详细的数据交互流程如下:
1、getaggregationdata(获取聚合数据)。这个过程主要是浏览器端发起请求,用于获取各个行政区域的聚合数据。返回的数据应该包括:行政区域名、区域码、车辆总数等信息。通常情况下,这个步骤需要提交的参数包括:当前地图视窗的范围window(包含窗口左上角、右下角的经纬度)、地图缩放级别level等。
2、getbikepostion(获取车辆位置信息)。当浏览器端的地图缩放级别超过街道后,不再使用服务端的聚合数据,而是直接获取当前地图视窗内所有车辆的位置信息。返回的数据应该包括:车辆编号、品牌、位置等信息。这个步骤需要提交的参数主要是当前地图视窗的范围window(包含窗口左上角、右下角的经纬度)。
3、browseraggregation(浏览器聚集)。收到上一步返回的数据后,浏览器端根据四叉树算法,进行浏览器聚合。当前视窗内局部区域的车辆总数如果超过设置的阈值,则显示成聚合信息,否则直接显示车辆。
服务端的主要数据结构如图6所示,总共有3张核心表,其中:
1、车辆表bike,存储了车辆的信息,包括车辆编号、车辆品牌、最后位置等信息;
2、行政区域表region,存储了行政区域的信息,包括区域名、区域码、上级区域码、界面信息等;
3、车辆所在区域表bike_region_relation,存储了所有车辆与区域的关系信息,用于描述某辆车在某个行政区域中。
当服务端收到客户端(浏览器端)发起的getaggregationdata请求时,服务端按以下步骤执行服务端聚合操作:
1、通过region表查询出在当前视窗window范围中的行政区域,即表border字段与参数window区域出现重叠;
2、通过bike_region_relation表聚合出上一步的结果中各个行政区域内的车辆总数。
这两步可以合并成以下sql语句:
selectb.regioncode,b.regionname,count(1)ascountfromregionr
lefjoinbike_region_relationbonr.code=b.regioncode
wherest_overlaps(r.border,[window])
groupbyr.code
以上sql中的[window]是一个参数,值为参数window表达的视窗范围。
当服务端收到客户端发起的getbikepostion请求时,服务端执行以下sql语句,查询出在当前视窗window范围中的所有车辆及位置信息:
selectname,brand,lastpointfrombike
wherest_within(lastpoint,[window])
以上sql中的[window]是一个参数,值为参数window表达的视窗范围。
本发明客户端聚合采用四叉树(一种每个节点最多有四个子树的数据结构)算法,四叉树算法的基本思想是将地理空间递归划分为不同层次的树结构,非常合适用于二维图片中定位像素的场景。因为二维空间(图经常被描述的方式)中,平面像素可以重复的被分为四部分,树的深度由图片、计算机内存和图形的复杂度决定。模型如图7所示。
在实际使用场景中,客户端会根据上一步返回的结果集list,总数量count、区域预定义的最多展示的总数量max,共同决定是否执行客户端聚合,详细步骤如下:
1、如果count小于或等于max,此时还在浏览器的直接渲染能力之内,所以直接展示各个车辆位置详情即可;
2、如果count大于max,此时直接展示,会导致浏览器展示变慢甚至崩溃,因此需要执行客户端聚合。首先需要将当前区域window分成左上lt、左下lb、右上rt、右下rb四个相等的区域,并循环结果集list,将结果集中的所有点重新计算、划分到四个细分区域中,分别所得list′、count′、max′;
3、上一步得到的四个细分区域,如果某个细分区域的总数量count′小于或等于max,则直接展示车辆位置详情;如果大于max,则只展示聚合结果,不再展示详情;
4、点击某个聚合结果,则循环执行以上步骤。
实施例二:
本发明提供了一种展示海量车辆位置分布信息的多层聚合系统,所述多层聚合系统包括浏览器端和服务端,浏览器端提交当前地图视窗的范围、地图缩放级别参数,向服务端发起聚合数据请求,获取各个行政区域的聚合数据;浏览器端继续提交当前地图视窗的范围,当浏览器端的地图缩放级别超过街道后,不再使用服务端的聚合数据,向服务端发起车辆位置信息请求,从服务端获取当前地图视窗范围内车辆数据;服务端向浏览器端返回车辆数据,浏览器端收到返回的车辆数据后,根据四叉树算法进行浏览器聚合。
进一步地,浏览器端根据客户端返回的结果集list,总数量count、行政区域预定义最多展示的总数量max,共同决定是否进行浏览器聚合。
进一步地,浏览器端决定是否进行浏览器聚合具体包括以下步骤:
如果count小于或等于max,此时还在浏览器的直接渲染能力之内,直接展示各个车辆位置详情;
如果count大于max,决定执行浏览器聚合:首先将当前地图视窗分成左上lt、左下lb、右上rt、右下rb四个相等的细分区域,并循环结果集list,将结果集list中的所有点重新计算、划分到四个细分区域中,得到list′、count′、max′;
基于四个细分区域,如果一个细分区域的总数量count′小于或等于max,则直接展示各个车辆位置详情;如果大于max,则只展示聚合结果,不再展示各个车辆位置详情;
点击所述聚合结果,则循环执行以上步骤。
实施例三:
本发明还提供了一种存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行如下步骤:
浏览器端提交当前地图视窗的范围、地图缩放级别参数,向服务端发起聚合数据请求,获取各个行政区域的聚合数据;
浏览器端继续提交当前地图视窗的范围,当浏览器端的地图缩放级别超过街道后,不再使用服务端的聚合数据,向服务端发起车辆位置信息请求,从服务端获取当前地图视窗范围内车辆数据;
服务端向浏览器端返回车辆数据,浏览器端收到返回的车辆数据后,根据四叉树算法进行浏览器聚合。
在本发明的一种替代方案中:增加服务端的聚合层级,避免客户端聚合。如服务端的聚合层级,除了省(直辖市)、市、区(县)、街道(镇)四层,可以再增加“小区”、“道路”、“地铁站”等更细的层级。由于街道以下的区域,已经在服务端聚合好,客户端则不再需要聚合。
本发明优选使用了postgresql作为数据库,解决gis(geographicinformationsystem,地理信息系统)场景下的海量数据低延迟读写及聚合统计,实现服务端聚合功能。优先使用高德地图api的四叉树算法及类库,实现客户端聚合功能。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!