基于汽车VIN搜索的数据库索引查询方法与流程
本发明涉及数据库技术领域,尤其涉及一种基于汽车vin搜索的数据库索引查询方法。
背景技术:
车辆识别号码(vehicleidentificationnumber)也称车架号码,简称vin,是一组由十七个英数组成,用于汽车上的独一无二的号码,可以识别汽车的生产商、引擎、底盘序号及其他性能等资料。其中,为避免与数字的1,0混淆,英文字母“i”、“o”、“q”均不会被使用。gb7258-2012规定:“汽车、摩托车、半挂车和中置轴挂车应具有唯一的车辆识别代号。vin技术标准包含不同的细节分支,各个细节分支中的编码位置代表的意义有细微差别,vin号码由三大部分组成:wmi(世界制造厂商识别代号),vds(车辆说明部分),vis(车辆指示部分)
vin的搜索,大量应用于车辆下线后的各个环节,如汽车的注册、保险、年检、维修和保养,直至回收或报废。最常见的应用范畴是通过搜索vin匹配汽车的车型,从而得到车型以后可以进而匹配到维修此车型的零配件,epc图等数据。常见的vin搜索数据库都会将vin号码定为主键,有主键的数据库表对应是树状结构,即平衡树结构,换句话说,就是整个表就变成了一个索引,也就是所谓的“聚集索引”。一个表一般只有一个主键,对应只有一个聚集索引,因为主键的作用就是把“表”的数据格式转换成“聚集索引(平衡树)”的格式放置。现有的技术中,常见的vin搜索数据库是数据库设计人员建立的,在数据库设计人员眼里,vin代码仅仅是普通的编码,只能将vin号码看成是普通的编码进行检索,当遇到大的数量级,如万亿级别的vin号码时搜索效率将逐步降低,搜索时间将大大增加。
技术实现要素:
本发明的目的是,提供一种基于汽车vin搜索的数据库索引查询方法,能够有效加快搜索速度,减少搜索时间。
为实现该目的,提供了一种基于汽车vin搜索的数据库索引查询方法,该方法包括以下处理步骤:
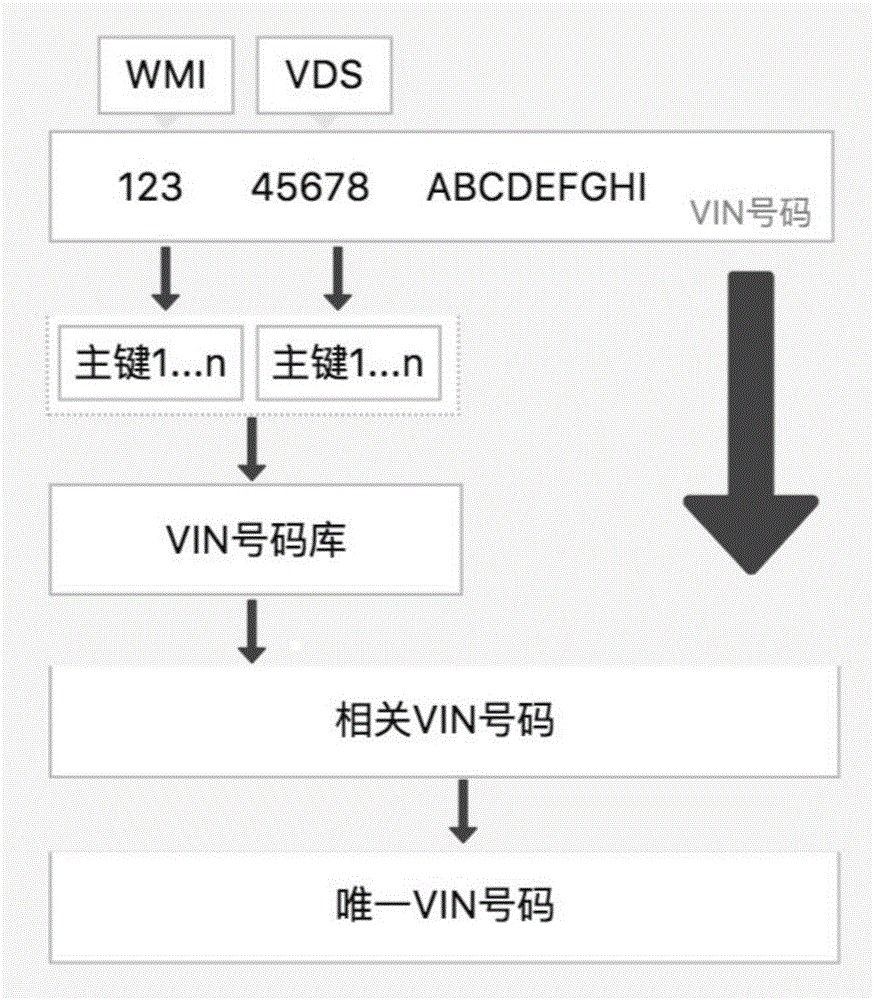
步骤1:分析需要查询的vin号码获得该vin号码的wmi号码和vds号码;
步骤2:将获得的wmi号码和vds号码拆分为主键,然后通过非聚集索引锁定数据库中相关的vin号码;
步骤3:将需要查询的vin号码在步骤2中锁定的相关vin号码中通过聚集索引锁定需要查询vin号码的唯一对应位置。
优选地,在步骤2中,用wmi号的第1位、第2位、第3位与vds号的第4位、第5位位结合作为主键。
优选地,所述wmi号第1位为生产国家或地区代码,wmi号第2位为汽车制造商代码,wmi号第3位为汽车类型代码,其中,部分品牌中通过将wmi号的第1位、第2位、第3位组合代码表示该品牌;vds号的第4位和第5位分别为发动机型号和制动及变速器型号。
优选地,在步骤2中,非聚集索引为在数据库管理系统对数据库中的wmi号码与vds号的第4位和第5位分别加上索引,形成多个独立的索引结构,其中每个索引结构即非聚集索引,互相之间不存在关联。
优选地,每形成一个新的索引结构,对应字段中的数据就复制一份出来,用于生成索引。
优选地,非聚集索引和聚集索引一样,均采用平衡树作为索引的数据结构。
优选地,在步骤3中,通过需要查询的vin号码的vis在在步骤2中锁定的相关vin号码中通过聚集索引定位需要查询的vin号码唯一对应位置。
本发明与现有技术相比,其有益效果在于:
本发明中通过汽车vin搜索与行业标准,从而能够有效优化vin的数据库索引查询方法,提升搜索速度,减少用户等待时间,降低服务器成本。通过本发明能够有效保障搜索的正确性和稳定性。
附图说明
图1为本发明的流程框图。
具体实施方式
下面结合实施例,对本发明作进一步的描述,但不构成对本发明的任何限制,任何在本发明权利要求范围所做的有限次的修改,仍在本发明的权利要求范围内。
如图1所示,一种基于汽车vin搜索的数据库索引查询方法,该方法包括以下处理步骤:
步骤1:分析需要查询的vin号码获得该vin号码的wmi号码和vds号码;
步骤2:将获得的wmi号码和vds号码拆分为主键,然后通过非聚集索引锁定数据库中相关的vin号码;
步骤3:将需要查询的vin号码在步骤2中锁定的相关vin号码中通过聚集索引锁定需要查询vin号码的唯一对应位置。
在步骤2中,用wmi号的第1位、第2位、第3位与vds号的第4位、第5位位结合作为主键。所述wmi号第1位为生产国家或地区代码,wmi号第2位为汽车制造商代码,wmi号第3位为汽车类型代码,其中,部分品牌中通过将wmi号的第1位、第2位、第3位组合代码表示该品牌,即,通过部分品牌前3位与vds号的第4位、第5位位结合作为主键。从而能够形成多个主键。vds号的第4位和第5位分别为发动机型号和制动及变速器型号。
在步骤2中,非聚集索引为在数据库管理系统对数据库中的wmi号码与vds号的第4位和第5位分别加上索引,形成多个独立的索引结构,其中每个索引结构即非聚集索引,互相之间不存在关联。每形成一个新的索引结构,对应字段中的数据就复制一份出来,用于生成索引。非聚集索引和聚集索引一样,均采用平衡树作为索引的数据结构。
在步骤3中,通过需要查询的vin号码的vis在在步骤2中锁定的相关vin号码中通过聚集索引定位需要查询的vin号码唯一对应位置。
在本实施例中,非聚集索引和聚集索引在同一数据库中,索引树结构中各节点的值来自于数据库表中的索引字段。假如给用户user表的名字name字段加上索引,那么索引就是由name字段中的值构成,在数据改变时,数据库管理系统dbms会一直维护索引结构的正确性。从而如果给数据库表中多个字段加上索引,那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。从而通过数据库管理系统的建立所需的非聚集索引,能够有效的查找到所有包含对应主键字段的所有vin号码的,从而使得通过输入的vin号码进一步定位的vin号码数量级大大降低,使得搜索速度大大提升,减少搜索时间。
现有的技术并没有利用到vin号码的行业标准意义,只能将vin号码看成是普通的编码进行检索,例如假设有1亿条vin号码,默认分块假设为10条,十进制分级,那么层级就是8个层级,从而8次以后查询到所需要搜索的额vin号码。当遇到大的数量级(万亿级别)的vin号码时搜索效率将逐步降低。本发明将vin号码的行业标准进行非聚集索引的检索,将提升5-10倍以上的检索效率,解决搜索大数据量的vin号码的问题。
以上仅是本发明的优选实施方式,应当指出对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些都不会影响本发明实施的效果和专利的实用性。
技术特征:
技术总结
本发明公开了一种基于汽车VIN搜索的数据库索引查询方法,该方法包括以下处理步骤:步骤1:分析需要查询的VIN号码获得该VIN号码的WMI号码和VDS号码;步骤2:将获得的WMI号码和VDS号码拆分为主键,然后通过非聚集索引锁定数据库中相关的VIN号码;步骤3:将需要查询的VIN号码在步骤2中锁定的相关VIN号码中通过聚集索引锁定需要查询VIN号码的唯一对应位置。通过本发明能够有效的优化VIN的数据库索引查询方法,提升搜索速度,减少用户等待时间,降低服务器成本。
技术研发人员:段绍斌;李廷鸿;邓志超;刘裕雄
受保护的技术使用者:广州前实网络科技有限公司
技术研发日:2018.10.11
技术公布日:2019.03.22
- 还没有人留言评论。精彩留言会获得点赞!