精确指数和准确SOFTMAX计算的制作方法
本申请要求享有于2017年10月15日提交的美国专利申请15/784,152的优先权,该申请通过引用并入本文。
本发明总体上涉及关联计算,并且具体地涉及使用关联计算的数据挖掘算法。
背景技术:
数据挖掘是发现大数据集中的模式的计算过程。数据挖掘使用不同的技术来分析大数据集,其中的一种技术是分类。分类用于基于存储在数据集中的、其组成员资格已知的数据项来预测数据实例的组成员资格。softmax回归是各种多类分类方法中使用的已知数据挖掘分类方法中的一种,例如,多项逻辑回归、多类线性判别分析、朴素贝叶斯分类器、人工神经网络,以及应用于包括计算机视觉、语音识别、自然语言处理、音频识别、社交网络过滤、机器翻译、生物信息学和其他的领域的其他深度学习算法。
softmax回归将任意实数值的n维向量“压缩”到范围[0,1]中的实数值的n维向量,其加起来为1,并且在等式1中定义:
其中n是数据集的大小,并且xi和xj是浮点数,分别表示存储在数据集中位置i和j的原始值。
在分类算法中,softmax回归计算对象属于n个定义的类中的每个类的概率。
可以在存储器中使用等式2表示二进制浮点(fp)数x:
x=(-1)s*(a+1)*2b等式2
其中s是由单个比特表示的数字的符号(负/正),a是尾数(mantissa),并且b是指数。符号比特s的值1指示负数,并且值0指示正数。
使用等式2的公式来表示x,等式1的ex可以由等式3表示:
ex的计算可以使用等式4中定义的标准泰勒级数来完成:
泰勒级数也可以表示为:
ex=y1+y2+y3+…等式5
其中y1=1,
可以认识到,使用多个乘法运算和除法运算来执行泰勒级数计算。为了在该计算中具有高精确度,可能要求可能显著地减慢该过程的许多系数和乘法运算。x越大,可能需要的系数越多,并且计算可能变得越重。
可以认识到,用于计算ex的泰勒级数可以在现有设备上并行地完成。当前的关联存储器设备(例如,在美国专利申请第14/588,419号、美国专利申请第14/555,638号和美国专利第15/146,908号中描述的关联存储器设备,这些申请全部转让给本申请的共同受让人)可以通过同时计算数据集中所有项的泰勒级数来提供出色的性能和响应时间。
尽管如此,对大数据集(n>150000)使用softmax回归即使在上面提到的关联存储器设备上也很难实现,因为softmax回归不是线性的,并且最终结果可能仅在计算出数据集中的每个对象j的值exj以便计算和
技术实现要素:
根据本发明的实施例,提供了一种用于关联存储器设备的方法。该方法包括将数字x的多比特尾数a划分为多个更小的部分尾数a_j,针对每个部分尾数a_j的每个可能值离线计算多个部分指数f(a_j),以及将多个部分指数f(a_j)存储在关联存储器设备的查找表(lut)中。
此外,根据本发明的实施例,离线计算包括使用大量泰勒级数系数。
此外,根据本发明的实施例,该方法还包括将部分尾数a_j的每个可能值k与多个部分尾数ai_j进行比较,一次比较一个值,每个部分尾数ai_j存储在关联存储器设备的分区sec-a_j的列i中,并且标记存储值k的、每个分区sec-a_j的每个列i。
更进一步地,根据本发明的实施例,该方法还包括从lut的行k读取部分指数f(a_j),并且同时将每个所读取的部分指数f(a_j)写入每个相关联的分区sec-f_j的所有标记的列。
另外,根据本发明的实施例,该方法还包括同时在每个列i上将存储在每个sec-f_j中的部分指数相乘,以及将相乘的结果存储在分区sec-ex的列i中,结果是e的x次幂的值。
另外,根据本发明的实施例,该方法还包括利用存储在所述分区sec-ex中的值来计算softmax、softplus、sigmoid或tanh中的任何一个。
此外,根据本发明的实施例,该方法还包括同时在sec-ex的每个行上对具有预定义值的比特数进行计数,以及将所述计数的结果存储在向量sum中。
另外,根据本发明的实施例,预定义值是一。
此外,根据本发明的实施例,该方法还包括对存储在sec-ex中的值进行归一化,并且将所述归一化的值存储在sec-s中。
此外,根据本发明的实施例,归一化包括同时将所述sec-ex的每个列i除以存储在sum中的值,从而在sec-s中提供softmax回归的结果。
根据本发明的实施例,提供了一种系统。该系统包括用于存储数字x的尾数a的多个部分尾数a_j的关联存储器阵列,以及用于利用部分尾数来计算e的x次幂的指数计算器。
此外,根据本发明的实施例,关联存储器阵列包括:多个部分尾数分区,用于在分区sec-a_j的每个列i中存储部分尾数ai_j;多个部分指数分区,用于在分区sec-j的每个列i中存储部分指数f(a_j)的值;以及分区sec-ex,用于在每个列i中存储通过将存储在部分指数分区的列i中的部分指数的值相乘而计算的值,从而提供e的x次幂。
另外,根据本发明的实施例,指数计算器还包括:查找表(lut),用于使用部分尾数的所有可能值来存储预先计算的e的部分指数的值;部分指数指派器,用于同时将存储在sec-a_j中的每个列i中的值与值k进行比较,以标记存储值k的所有列,并且同时向部分指数分区sec-j中的每个标记的列i写入从lut读取的值;以及指数乘法器,用于将存储在部分指数分区的每个列i中的值相乘,并且将相乘的结果存储在分区sec-ex中。
此外,根据本发明的实施例,关联存储器阵列还包括:向量sum,用于存储所有存储在sec-ex的列中的值的和;以及分区sec-s,用于在每个列i中存储通过将存储在sec-ex的列i中的值除以和而计算的softmax回归si的值。
此外,根据本发明的实施例,该系统还包括:指数加法器,用于对存储在sec-ex的所有列i中的所有指数值求和;以及归一化器,用于同时将存储在sec-ex的每个列i中的每个值除以和,并且将除法的结果存储在分区sec-s的列i中,从而在sec-s中提供准确softmax的值。
附图说明
在说明书的结论部分中特别指出并清楚地要求保护被视为本发明的主题。然而,通过参考以下详细描述,当结合附图阅读时,可以最好地关于组织和操作方法以及其目的、特征和优点来理解本发明,在附图中:
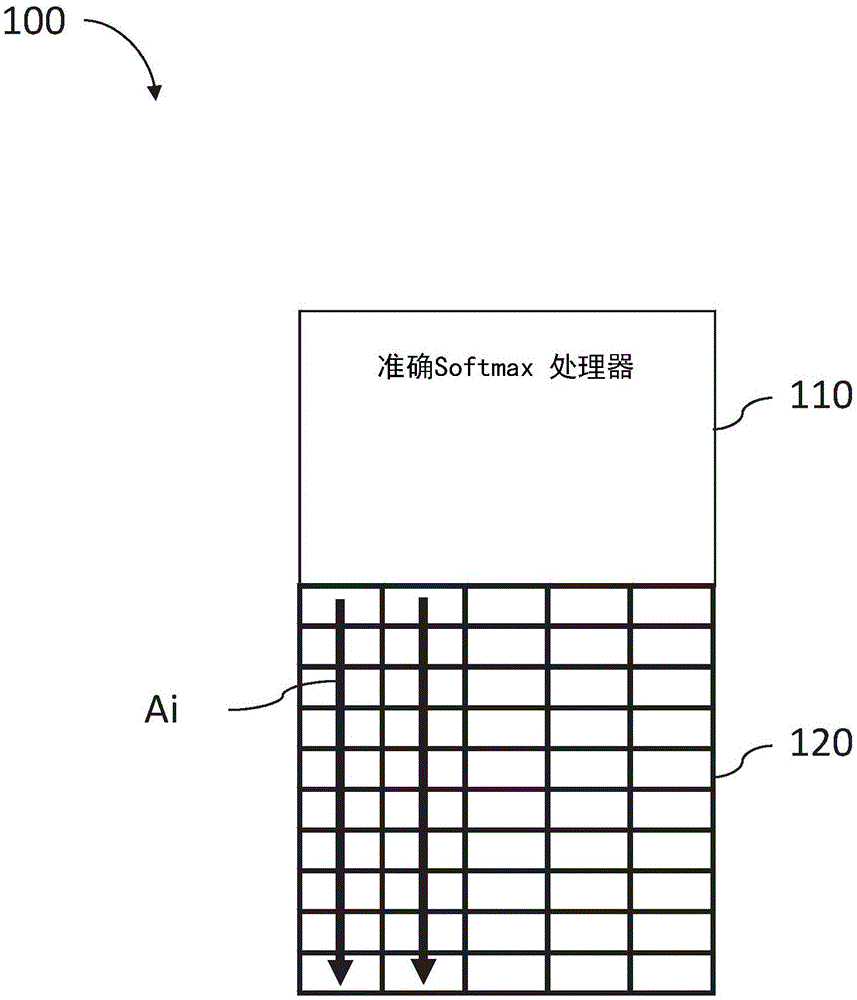
图1是根据本发明的实施例构造和操作的准确softmax系统的示意图;
图2是根据本发明的实施例的图1的准确softmax系统的关联存储器阵列元件的一部分的示意图;
图3是根据本发明的实施例的存储由图1的准确softmax系统使用的部分指数的查找表(lut)的示意图;
图4是根据本发明的实施例构造和操作的包括指数计算器的准确softmax系统的详细示意图;
图5是描述根据本发明的实施例的准确softmax系统的示例性操作流程的流程图;
图6是根据本发明的实施例的使用浮点数的5比特部分尾数计算的部分指数的示例性lut的示意图;以及
图7是根据本发明的实施例的使用定点数的8比特部分尾数计算的部分指数的示例性lut的示意图。
应认识到,为了说明的简单和清楚起见,附图中所示的元素不一定按比例绘制。例如,为了清楚起见,元素中的一些元素的尺寸可能相对于其他元素被夸大。此外,在认为适当的情况下,可以在附图中重复附图标记以指示对应或类似的元素。
具体实施方式
在以下详细描述中,阐述了许多具体细节以便提供对本发明的透彻理解。然而,本领域技术人员将理解,可以在没有这些具体细节的情况下实践本发明。在其他实例中,没有详细描述公知的方法、过程和组件,以免模糊本发明。
申请人已经意识到,针对整个数据集的softmax回归的高度正确的结果(本文中称为“准确softmax”),可以在关联存储器设备上(例如,在美国专利申请第14/588,419号、美国专利申请第14/555,638号和美国专利申请第15/146,908号中描述的关联存储器设备,这些申请全部转让给本发明的共同受让人)以o(1)的复杂度来实现。
现在参考的图1示意性地示出了根据本发明的优选实施例构造和操作的准确softmax系统100。准确softmax系统100包括准确softmax处理器110和关联存储器阵列120,准确softmax处理器110可以同时计算对数字的大数据集进行的softmax回归的高度正确的值,关联存储器阵列120可以存储来自要对其执行softmax回归的大数据集的每个值xi的尾数ai。
关联存储器阵列120包括多个分区,每个分区由多个行和列构成。尾数ai可以存储在关联存储器阵列120的列i中。
申请人已经意识到,要针对其计算准确softmax回归的每个浮点(fp)值x(等式2)的尾数a可以表示为m个变量a_j的和,其中每个变量是由尾数a的总比特中的若干比特构成的部分尾数。可以认识到,符号a_j表示尾数a的部分尾数j。
每个部分尾数a_j的值是a_j的比特乘以由部分尾数a_j在整个尾数a内的位置确定的二的相关次幂(p1,p2...)的值,如等式6中定义的。
a=2p1*a_1+2p2*a_2+…a_m等式6
可以认识到,在本说明书中,二的幂有时写为2p,有时写为2^p。
对于一般的10比特尾数a,一个可能的表示可以是2个变量a_1和a_2,每个变量为5比特。当a_1包括a的5个msb比特并且a_2包括a的5个lsb比特时,a的值可以由等式7表示:
a=32*a_1+a_2等式7
10比特尾数a的可能表示的另一示例可以是4个变量a_1、a_2、a_3和a4。a_1包括a的3个msb比特,a_2包括接下来的3个msb比特,a_3包括接下来的3比特,并且a4包括lsb比特和符号比特,如等式8中定义的:
a=128*a_1+16*a_2+4*a_3+a4等式8
申请人已经意识到,当利用关联存储器阵列120起作用时,将尾数a表示为部分尾数a_j的和可能是有利的。(每个浮点值xi的)尾数ai的每个特定部分尾数j——标记为部分尾数ai_j可以存储在关联存储器阵列120的单独分区sec-j的相同列i中,如现在参考的图2所示。
图2是关联存储器阵列120的一部分的示意图,其被划分成分区sec-a_1、sec-a_2、sec-a_3...sec-a_m,每个分区存储每个尾数ai的不同比特。分区sec-a_1可以在列i中存储每个fp数xi的部分尾数ai_1的比特;分区sec-a_2可以在列i中存储部分尾数ai_2的比特,并且分区sec-a_m可以在列i中存储部分尾数ai_m的比特。关联存储器阵列120的其他分区(未在图2中具体示出)可以由softmax处理器110使用,以存储softmax回归计算的中间和最终结果,如下文详细描述的。可以认识到,准确softmax处理器110可以同时在多个分区上操作,并且可以在关联存储器阵列120的不同分区上执行不同的操作。还可以认识到,在分区的所有列上同时进行计算。
使用尾数a作为m个部分尾数a_j的和(等式6)的表示,ex可以由等式9表示:
其中p1、p2...表示应该上升的2的幂次,并且根据原始尾数a中的比特的位置来定义。例如,跨越位置5-10中的比特的部分尾数的p值是5。使用标准数学指数乘积规则(xa+b=xa*xb),ex可以表示为e的m个部分指数的乘积,其中每个这样的指数的每个部分尾数a_j仅包括原始尾数a的若干连续比特,如等式10中定义的:
为了简单起见,利用部分尾数a_j计算出的e的每个部分指数可以表示为f(a_j):
…
这产生了简化的表示,如等式11所示。
ex=f(a_1)*f(a_2)*…*f(a_m)等式11
可以认识到,一旦部分指数f(a_1),f(a_2),...,f(a_m)的值已知,则可能要求附加的乘法f(a_1)*f(a_2)*...*f(a_m)来完成对原始指数ex的计算。
申请人已经意识到,部分指数f(a_1),f(a_2),...,f(a_m)的值不改变,并且因此可以预先对其进行计算并将其存储在查找表(lut)300中,如现在参考的图3所示。
lut300包括2py个条目,部分尾数a_j的每个可能值一个条目,其中py是最大a_j中的比特数、指数b中的比特数的函数,如等式12中定义的:
py=1+最大a_j中的比特数+b中的比特数等式12
lut300中的每个条目可以存储每个部分指数f(a_j)的计算的结果以及部分尾数a_j的每个有效值。在lut300的行0中,可以假设部分尾数a_j的值是0来计算每个f(a_j)的值。在lut300的行1中,可以假设部分尾数a_j的值是1来计算每个f(a_j)的值,依此类推,直到lut300的最后一行,其中可以假设部分尾数a_j的值是2py来计算每个f(a_j)的值。
可以认识到,存储在lut300中的值可以以高精确度预先计算并且具有与所需要的一样多的系数。该计算可以在实际计算准确softmax之前仅执行一次。
现在参考的图4更详细地、示意性地示出了根据本发明的优选实施例构造和操作的图1的准确softmax系统100。准确softmax处理器110包括指数计算器400、指数加法器116和归一化器118。
另外,还示意性地示出了准确softmax处理器110可以在其上操作的关联存储器阵列120的不同分区。关联存储器阵列120包括:用于在每个列i中存储部分尾数ai_j的值的分区sec-a_j,用于存储部分指数f(ai_j)的分区sec-f_j,用于在每个列i中存储exi的值的分区sec-ex,用于存储计算softmax回归所需要的所有指数的和的向量sum,以及用于在每个列i中存储每个xi的计算出的softmax回归si的分区sec-s。
指数计算器400包括(图3的)lut300、部分指数指派器112、指数乘法器114。部分指数指派器112可以对lut300的部分尾数的所有可能值k循环。对于每个k,部分指数指派器112可以同时在所有分区sec-a_j上并行地比较存储在每个列i中的所有部分尾数ai_j的值,并且标记具有与k相同的值的、每个分区中的所有列。
并行地,部分指数指派器112可以读取lut300的行k的部分指数f(a_j)的值,并且可以同时地将每个值f(a_j)写入每个相关联的分区sec-f_j中的所有先前标记的列i。部分指数指派器112的操作可以采用2py个步骤,每个步骤对不同的k值进行操作。
指数乘法器114可以同时将存储在每个分区f_j的每个列i中的所有部分指数f(ai_j)相乘,以使用等式11来计算ex。可以认识到,指数乘法器114可以在所有分区的所有列上同时执行乘法,并且可以将每个exi存储在分区sec-ex的列i中。对于每次乘法,该操作可以采用一个步骤。
指数加法器116可以计算所有exi的和。exi的每个值可以被转换为l比特的定点数,并且可以存储回分区sec-ex的列。可以认识到,每个定点数可以存储在分区sec-ex的l个行中。l可以是32、64或任何其他不会影响计算的精确度的数字。指数加法器116可以从lsb开始到msb在分区sec-ex的行上迭代,并且对每行中具有值1的所有比特进行计数。然后,指数加法器116可以将对每行进行的计数的结果存储在关联存储器阵列120中的专用向量sum中。
计数操作的一个可能的实施例在2017年7月13日提交的题为“findingkextremevaluesinconstantprocessingtime(在恒定的处理时间内查找k个极值)”的美国专利申请15/648,475中进行了描述,并且该申请转让给本发明的共同受让人。计算所有exi的和可以采用l*计数个操作步骤。
一旦计算和并且将其存储在关联存储器阵列120中的向量sum中,则归一化器118可以通过将存储在分区sec-ex中的列i中的每个exi的值除以存储在sum中的值来同时计算每个列i中的softmax回归的最终结果si。对所有si值的计算可以采用大约几百个时钟的一个步骤。
现在参考的图5是描述根据本发明的优选实施例构造和操作的准确softmax系统100的操作的流程图500。在作为启动步骤的步骤510中,可以利用部分指数f(a_j)的所有值来创建lut300。在步骤520中,部分指数指派器112可以初始化用于传递通过lut300的输入值k。在步骤530中,部分指数指派器112可以同时将每个部分尾数ai_j的值与k的值进行比较,并且可以标记所有分区中的、存储其值与k等同(ai_j==k)的部分尾数的所有列。
在步骤540中,部分指数指派器112可以从lut300的相关条目(行k)得到f(a_j)的值,并且在步骤550中,部分指数指派器112可以同时将每个f(a_j)的值写入每个相关sec-f_j中的所有标记的列。例如,值f(a_2)(针对具有值k的部分尾数a_2计算的)可以被写入分区sec-f_2的所有列,因为存储在分区a_2中的部分尾数的值等于k。
在步骤560中,部分指数指派器112可以检查其在lut300中的位置。可以重复步骤520-560,直到扫描整个表。在扫描整个lut300之后,在步骤570中,指数乘法器114可以通过将所有部分指数相乘来同时计算所有指数exi,并且在步骤580中,指数加法器116可以计算并存储所有指数exi的和。在步骤590中,归一化器118可以通过将存储在sec-ex中的每个列i中的每个exi的值除以存储在sum中的和来针对分区sec-ex的每个列i同时计算准确softmaxsi,并且将准确softmax值si存储在分区sec-s中以供进一步使用。
本领域技术人员可以认识到,流程500中示出的步骤不旨在是限制性的,并且可以利用更多或更少的步骤,或利用不同的步骤序列或其任何组合来实践该流程。
可以认识到,指数计算器400可以用于涉及ex的计算的任何计算,包括诸如本文描述的softmax之类的、神经网络中的许多激活函数,以及诸如sigmoid函数
具体示例可以是10比特尾数。使用等式2,16比特半精度浮点(fp)数x可以在存储器中表示为x=(-1)s*(a+1)*2b,其中s是符号比特,a是10比特尾数并且b是5比特指数。e的指数可以表示为
应用各自具有5比特的部分尾数的数学指数规则可以给出
可以认识到,该示例的查找表包含2048个条目(每个部分尾数(a_1或a_2)有5比特,指数b有5比特并且符号s有1比特,这提供11比特并且产生211=2048个可能的值)。图6示出了适用于该示例的lut300a。
在该示例中,计算的大部分需要搜索从0到2047的k的值并且将相关联的值从lut300a写入关联存储器阵列120中的分区sec-f_1和sec-f_2。这可能花费总共2048个时钟,每个k值一个时钟。针对f(a_1)*f(a_2)进行一次附加的乘法,这要求花费几百个时钟。
应认识到,当使用定点指数而不是浮点指数时,16比特fp数xi可以表示为x=y/2b=(256*y1+y2)/2b,其中y1表示8个msb比特,y2表示8个lsb比特,并且b可以具有0到16之间的固定值。
为了简单起见,在该示例中忽略符号比特,因为其对计算的总体性能没有影响。在这种情况下,e的指数可以表示为
lut300b中的每个条目可以存储256个可能值中的、y1和y2的部分指数的值。可以认识到,在这种情况下,包括对从0到256的每个输入值的搜索操作以及将适当值写入关联存储器阵列120中的分区sec-f_1和sec-f_2的操作的整个计算可能花费256个时钟。一次定点附加乘法可能花费大约几百个附加时钟,为整个数据集提供小于0.3微秒的总计算时间。
可以认识到,针对大数据集中所有项的softmax的总计算可能花费少于2微秒(对于fp数大约为2500个时钟,对于定点数大约为1500个时钟)。
可以认识到,在现有技术的gpgpu(使用图形处理单元的通用计算)上,softmax计算的执行花费大约8毫秒,这比本发明的执行慢4000倍。
可以认识到,每个部分指数f(a_j)的离线计算可以以几种方式完成。一种方式可以是使用等式4的泰勒级数来计算部分指数。然而,由于部分尾数小于完整尾数,例如,仅部分尾数中的5比特与完整尾数中的10比特进行比较,计算可能会快得多。
应认识到,通过离线计算每个部分指数f(a_j),本发明可以利用与所期望的一样多的泰勒级数的系数来计算f(a_j)。结果可以是所有部分指数f(a_j)的正确值。
还可以认识到,可以通过添加该过程的进一步并行化来实现性能的进一步改进。如果关联存储器阵列120足够大以存储数据集的多个副本,则可以实现这种并行性。如前面定义的,lut一次遍历一个条目,直到扫描所有条目。对于2048个条目的lut,部分指数指派器112的计算时间可以是2048个时钟。然而,将数据集复制到关联存储器阵列120的附加分区是可能的。在这种情况下,部分指数指派器112可以分割lut并且关于数据集的每个副本仅使用lut的一半。因此,部分指数指派器112可以两倍快地起作用,并且可以在仅1024个时钟中完成其计算。如果数据可以被复制y次,则部分指数指派器112的计算可以小y倍。
当x很大时,ex可能变得非常大并且可能产生溢出。为了避免这种情况,减小指数的大小可能是有用的。使用标准算术,将除法的分子和分母乘以任何选定的值c是可能的。将此规则应用于softmax回归可以在等式13中描述:
使用标准数学指数规则,结果可以是等式14
对于所有j=1,n,c可以被定义为存储在分区ex中的exi的最大值,c=(-1)max(exj),产生较小的指数值。在2017年8月29日提交的题为“methodformin-maxcomputationinassociativememory(用于在关联存储器中进行最小值-最大值计算的方法)”的美国专利申请第15/688,895号和2015年1月12日提交的题为“memorydevice(存储器设备)”、公布号为2015/0200009的美国专利申请第14/594,434号(其中复杂度为o(1))中定义了用于以复杂度o(1)在大数据集中查找最大值的方法。
可以认识到,使用本发明可以为大数据集提供具有最高精确度的准确softmax回归,其中计算复杂度为o(1)。另外,在本发明的准确softmax系统100中计算softmax回归的平均时间可以花费少于8微秒,这比gpu(图形处理单元)中可以实现的快几个数量级。
虽然本文已经说明和描述了本发明的某些特征,但是本领域普通技术人员现在将想到许多修改、替换、改变和等同物。因此,应理解,所附权利要求旨在覆盖落入本发明的真正精神内的所有这些修改和改变。
- 还没有人留言评论。精彩留言会获得点赞!