一种基于主题模型的HSK作文生成方法与流程
本发明属于文本信息处理技术领域,具体涉及一种基于主题模型的hsk作文生成方法。
背景技术:
在it行业和互联网高速发展的时代,人们正梦想着使自然语言可计算,以便我们可以在大规模非结构化文本下发掘出隐藏的信息和知识。人工智能(ai)技术正在快速增长。20年前,ibm公司在1997年研制的深蓝(deepblue)打败国际象棋世界冠军garrykasparov,2016年3月alphago以其montecarlo树搜索算法击败李世石。这是人工智能研究的一个重要里程碑。
另一方面,ai和大数据的结合为自然语言处理技术带来前所未有的发展。人工智能机器人因其工作原理是基于规则进行逻辑推理,所以适用于程序化劳作,可以处理数据量较大、时效性要求高的工作。大数据支持一些破冰的想法打破了许多行业,甚至写作的传统框架。随着计算机技术和人工智能技术的发展,人类最高智慧而产生的文学写作,已经进入了“电脑制造”的时代。同时也带来写作观念、写作行为和写作思维方式的变化。自然语言生成是诸如知识库或逻辑形式的机器表示系统生成自然语言的自然语言处理任务。可以说,自然语言生成系统就像一个将数据转换为自然语言表示的翻译器。然而,由于自然语言的固有表达性,产生最终语言的方法不同于编译器的方法。
汉语水平考试(hsk)是为测试母语为非汉语者的汉语水平而设立的一项国际汉语能力标准化考试。相当于英语的四级、六级考试,以及托福、雅思考试等。国内外关于英语考试的研究,尤其是英语考试写作的研究已经有丰硕的成果。但是,目前对汉语水平考试写作的研究还较少,尤其是研究现有的自然语言处理技术智能答题的能力。随着hsk在全世界范围的推广,越来越多海外的汉语学习者开始参与hsk考试。国内对于hsk考试的研究也不断加大。
写作题主要考察的是语序,语法,内容和语言逻辑,是很好的研究自然语言生成的课题。写作任务看起来是比较困难的挑战。但是,经过分析写作任务,和训练机器学习模型,也可以将写作任务转化成可训练的文本生成任务。随着大数据技术,自然语言处理以及其他人工智能技术的不断发展,逐渐掀起了用算法自动生成新闻报道的探索和实践。随着新闻写作自动生成技术的不断实践和发展,不断印证了人工智能技术可以帮助人们快速便捷的进行数据处理和整合。在新闻媒体界的发展必将改变新闻媒体的传播内容和传播方式。然而,现有技术的自动生成文本在连贯性和逻辑性上效果欠佳,语法错误出现较多,错别字较多,这些问题亟待改善。
技术实现要素:
针对上述现有技术中存在的问题,本发明的目的在于提供一种可避免出现上述技术缺陷的基于主题模型的hsk作文生成方法。
为了实现上述发明目的,本发明提供的技术方案如下:
一种基于主题模型的hsk作文生成方法,包括:训练lda模型,得到句子和文本、词语和文本的分布,计算交叉熵,选择与主题关键词最相近的句子,然后生成文本。
进一步地,选用训练数据集训练lda模型,选用训练数据集的步骤包括:选择“hsk动态作文语料库”作为基本语料库;首先按照语料库中对作文的修改标注,将语料处理为标准作文语料,即按照语料库中标注出的错误和给出的修改,将标注作文处理为规范的作文,将这些规范作文样本,作为标准语料,进行对lda模型的训练。
进一步地,训练lda模型的步骤包括:
lda算法开始时,随机地给定参数θd和φt,然后不断迭代和学习以下步骤a、b、c所描述的过程,最终得到收敛的结果就是lda的输出;
a.对一个特定的文档ds中的第i词汇wi,假设词汇wi对应的主题为tj,则:
pj(wi|ds)=p(wi|tj)×(tj|ds);
b.现在我们可以枚举主题集合t中的主题,得到所有的pj(wi|ds),其中j取值1~k,然后可以根据这些概率值结果为ds中的第i个词wi选择一个主题;
c.对词汇集合d中所有w进行一次p(w|d)的计算并重新选择主题看作一次迭代。
进一步地,计算交叉熵的步骤包括:
对于概率分布p和q,其交叉熵为
其中,
进一步地,所述基于主题模型的hsk作文生成方法的具体步骤为:选用训练数据集对lda模型进行训练,得到文本集主要内容的分布,以及各个句子在主题下的分布;计算候选句子和文档之间的交叉熵,选择交叉熵较小的句子;将候选句子按照在原候选文本中的相对位置参数排序;输出自动生成的作文。
进一步地,用lda模型生成一篇文本的方法包括:
a.从狄利克雷分布α中取样生成文档i的主题分布θi;
b.从主题的多项式分布θi中取样生成文档i第j个词的主题zij;
c.从狄利克雷分布β中取样生成主题zij的词语分布
d.从词语的多项式分布
进一步地,所述lda模型中所有可见变量以及隐藏变量的联合分布是
p(wi,zi,θi,φ|α,β);
对公式中θi和
p(wi|α,β)=∫∫∑p(wi,zi,θi,φ|α,β);
假设语料库中有m篇文本,其中所有的词汇w和词汇对应的主题z如下所示
w=(w1,...,wm);
z=(z1,...,zm);
wm表示第m篇文本中的词汇,zm则表示这些词对应的主题的编号。
进一步地,在所述lda模型中,假设现在要生成第m篇文本,先查看第m篇文本的文本-主题的分布,然后生成第n个词的主题编号zm,n;
在词汇-主题的分布中,查找编号为zm,n的主题,并选择该主题下的词汇,最终得到词汇wm,n,由此便可以生成语料中第m篇文档的第n个词;
在lda模型中,m篇文档会对应有m个独立的dirichlet-multinomial共轭结构;k个主题对应于k个独立的dirichlet-multinomial共轭结构;
其中,nm=(nm(1),...,nm(k)),nm(k)表示第m篇文本中第k个主题对应的词的个数;根据dirichlet-multinomial共轭结构,得到θm的后验分布为dir(θm|nm+α);
计算得到整个文本集中主题生成的概率
得到
w′=(w(1),...,w(k));
z′=(z(1),...,z(k));
w(k)表示这些词语都是主题k生成的,z(k)则是对应这些词的主题的编号;得到
nk=(nk(1),...,nk(t));
nk(t)是主题k产生的词汇中词t的个数;
得到整个文本集中词生成的概率为
得到
最终,得到lda模型的gibbssampling公式为:
进一步地,所述基于主题模型的hsk作文生成方法包括步骤如下:
(1)选用训练数据集对lda模型进行训练,得到文本集主要内容的分布,以及各个句子在主题下的分布;
(2)计算候选句子和文档之间的交叉熵,选择交叉熵较小的句子;
(3)将候选句子按照在原候选文本中的相对位置参数排序;
(4)输出自动生成的作文。
本发明提供的基于主题模型的hsk作文生成方法,通过训练lda主题模型,得到句子和文本、词语和文本的分布,并通过计算交叉熵,选择与主题关键词最相近的句子,然后生成文本,且自动生成的文本在连贯性和逻辑性上效果好,语法错误较少,错别字较少,能够很好地完成写作任务,可以很好地满足实际应用的需要。
附图说明
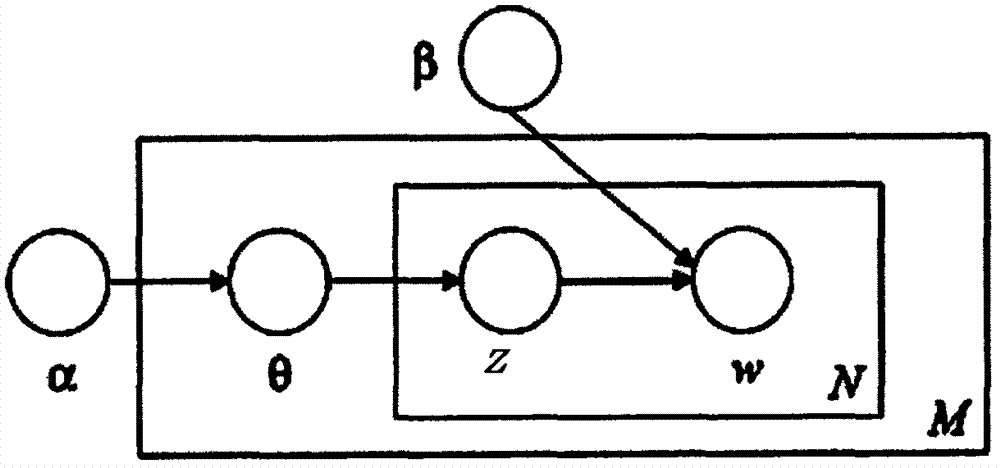
图1为lda基本模型图;
图2为lda联合概率模型图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明做进一步说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种基于主题模型的hsk作文生成方法,包括步骤:选用训练数据集训练lda主题模型,得到句子和文本、词语和文本的分布,并通过计算交叉熵,选择与主题关键词最相近的句子,然后生成文本。
hsk5第一个写作任务是要使用所给词语,写一篇短文本。2013年7月新汉语水平考试五级真题写作部分第一题如下。
请结合下列词语(要全部使用,顺序不分先后),写一篇80字左右的短文。
简历信息突出特色应聘
根据题干所给词语,写作,这是一个典型的材料作文任务。我们可以大致看出,题干中所给出的五个词语绝对不是没有任何关联的。因此,可以通过先确定主题,然后再围绕这个主题展开写作,并使用题干中所给的全部词语。分析上述例题,我们可以判定出,主题是“求职”,因此,在写作时,就可以围绕“求职”这个主题进行写作。
由此,可以得到写作的基本步骤:
(1)根据题干所给词语,确定主题。写作任务要始终围绕这个主题来进行。
(2)用所给词造句。因为题干要求所给词汇必须全部用到,因此,可以用所给词语造句,但是要保证造出的句子要与主题相统一。
通过以上对这个写作任务的分析容易看出,这个写作任务的重点在于围绕一个特定的主题来展开写作,另外,要保证题干所列出的词汇,在写作中全部出现。
因此,想要用机器实现自动生成作文,完成这个写作任务的话,就要按照主题来完成写作任务。从这个角度出发,本发明提出了基于lda主题模型的自动写作方法,来实现机器的自动作文任务。
针对这个写作任务,本发明提出了基于主题模型的自动写作方法,并采用句子抽取的策略完成文本的生成。句子抽取的策略,主要是通过从候选文本中抽取适当的句子,再将这些句子排序组合,从而生成完整的篇章。基于主题模型的句子抽取,即通过主题及关键词对候选文本中的句子进行选择和抽取。
因此,在生成一篇文本时,先要在所给定的几个关键词的基础上,再生成几个相应的词。然后,用这些词在候选文本中筛选和抽取句子。最后,再利用句子在候选文本中的相对位置对抽取到的句子进行排序,最终得到一篇生成文本。
选用训练数据集的步骤包括:
1)选择“hsk动态作文语料库”作为基本语料库;
“hsk动态作文语料库”是由北京语言大学崔希亮教授主持的一个国家汉办科研项目。是母语为非汉语的外国人参加高等汉语水平考试(hsk高等)作文考试的答卷语料库,经过多年的修改补充,语料库先收集了11569篇作文。语料中原始语料包含了考生作文答卷,以及考生作文分数等非常详尽的信息。另外,语料中的标注语料库则对考生作文中的错误有非常全面的修改标注,标注内容主要有(1)字处理:包括错别字标注,漏字标注,多字标注等。(2)标点符号处理:包括错误标点标注,空缺或者多余标点的标注。(3)词处理:包括错词,缺词,搭配错误等标注。(4)句处理:包括病句标注,句式杂糅等方面的错误标注。(5)篇章处理:包括句间连接方法,语义表达方面的错误标记。
2)对语料进行处理;
由于“hsk动态作文语料库”是人工标记的考生作文语料,首先按照语料库中对作文的修改标注,将语料处理为标准作文语料,即按照语料库中标注出的错误和给出的修改,将标注作文处理为规范的作文。将这些规范作文样本,作为标准语料,进行对lda模型的训练。另外,从互联网上获取中小学生作文10000篇,作为语料库的丰富和补充。
训练lda主题模型的步骤包括:
lda算法开始时,随机地给定参数θd和φt,θd代表文档i的主题分布,φt代表主题t的词语分布,然后不断迭代和学习以下步骤a、b、c所描述的过程,最终得到收敛的结果就是lda的输出:
a.对一个特定的文档ds中的第i词汇wi,假设词汇wi对应的主题为tj,则:
pj(wi|ds)=p(wi|tj)×(tj|ds);
b.现在我们可以枚举主题集合t中的主题,得到所有的pj(wi|ds),其中j取值1~k,然后可以根据这些概率值结果为ds中的第i个词wi选择一个主题;
c.对词汇集合d中所有w进行一次p(w|d)的计算并重新选择主题看作一次迭代。
交叉熵用来衡量2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小。因此用交叉熵来选取句子,构造生成文本。
计算交叉熵的步骤包括:
对于概率分布p和q,其交叉熵为
其中,
隐含狄利克雷分布(latentdirichletallocation,lda)是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。在自然语言处理中,隐含狄里克雷模型是一种生产性的统计模型,可以通过不可观测的群体来解释观测群体,并由此来解释数据某些部分的相似性。
在lda模型中,每个文档可以被看作是各种主题的混合,其中每个文档被认为具有通过lda分配给它的一个主题分布。
lda是一种典型的词袋模型,它认为一篇文档是一组词汇的集合,词汇之间都是独立存在的,没有先后的关系。文档仅仅包含一小部分的主题,并且该主题经常只使用一小部分的词汇。因此,可以通过lda得到文档与主题,主题与词汇的分布。
beta分布是二项式分布的共轭先验概率分布:对于非负实数和,有如下关系
beta(p|α,β)+count(m1,m2)=beta(p|α+m1,β+m2)(2.1);
公式中,count(m1,m2)是beta分布beta(m1+m2,p)的计数。在这里,观测到的群体数据服从二项分布,并且,参数的先验分布和后验分布都服从beta分布。在这种情况下,我们说服从beta-binomial共轭。
狄利克雷分布(dirichlet分布)是多项式分布的共轭先验概率分布:
“将
同理,公式中,
由此可见,狄利克雷分布是多项式分布的共轭先验概率分布,而beta分布是二项式分布的共轭先验概率分布。
因此,用lda生成模型,生成一篇文本的方法如下:
a.从狄利克雷分布α中取样生成文档i的主题分布θi;
b.从主题的多项式分布θi中取样生成文档i第j个词的主题zij;
c.从狄利克雷分布β中取样生成主题zij的词语分布
d.从词语的多项式分布
用lda生成模型生成包含多个主题的文本:
chooseparameterθ~p(θ);
foreachofthenwordsw_n:
chooseatopiczn~p(z|θ);
chooseawordwn~p(w|z);
定义θ是一个主题向量,向量θ是非负归一化的向量,其中的每一列表示每个主题在文档出现的概率;p(θ)是关于θ的分布,并且为狄利克雷分布;n和wn同上;zn表示选择的主题,p(z|θ)表示选择特定θ时主题z的概率分布,具体为θ的值,即p(z=i|θ)=θi;p(w|z)表示选择主题z时主题w的概率分布。
以上方法的描述即为,选定一个主题向量θ,并计算文档中每个主题的概率。在主题分布向量θ选择一个主题z,从主题和词汇的分布中,根据主题z的词汇概率分布生成主题相关的词语。
其模型如图1所示。因此整个模型中所有可见变量以及隐藏变量的联合分布是
p(wi,zi,θi,φ|α,β)(2.3)
对公式中θi和
p(wi|α,β)=∫∫∑p(wi,zi,θi,φ|α,β)(2.4)
将该联合概率分布对应到图上,得到图2;
假设语料库中有m篇文本,其中所有的词汇w和词汇对应的主题z如下所示
w=(w1,...,wm)(2.5)
z=(z1,...,zm)(2.6)
wm表示第m篇文本中的词汇,zm则表示这些词对应的主题的编号。
由此,可以分析,图中α→θ→z这个过程,假设现在要生成第m篇文本,先查看第m篇文本的文本-主题的分布,然后生成第n个词的主题编号zm,n。由于过程α→θ对应于狄利克雷分布,并且过程θ→z对应于multinomial分布,因此这个过程整体是一个dirichlet-multinomial共轭结构。
图中β→w这个过程,在词汇-主题的分布中,查找编号为zm,n的主题,并选择该主题下的词汇,最终得到词汇wm,n,由此便可以生成语料中第m篇文档的第n个词。
另外,由于lda模型是一个词袋模型,因此,过程α→θ→z和过程β→w是相互独立的,且没有时间先后顺序。由此,lda模型中,m篇文档会对应有m个独立的dirichlet-multinomial共轭结构;同理,k个主题就会对应于k个独立的dirichlet-multinomial共轭结构。
由于
公式中的nm=(nm(1),...,nm(k)),其中nm(k)表示第m篇文本中第k个主题对应的词的个数。然后,根据dirichlet-multinomial共轭结构,可以得到θm的后验分布为dir(θm|nm+α)。
因为文本集中的m篇文档的主题生成的过程是相互独立的过程,所以,我们可以得到m个相互独立的dirichlet-multinomial共轭结构,由此,我们可以计算得到整个文本集中主题生成的概率
同样的,可以得到
w′=(w(1),...,w(k))(2.9)
z′=(z(1),...,z(k))(2.10)
w(k)表示,这些词语都是主题k生成的,z(k)则是对应这些词的主题的编号。由于,文本中随机两个由主题k生成的词是相互独立,可以交换的,因此,整个过程还是一个dirichlet-multinomial共轭结构。
在此,可以得到
nk=(nk(1),...,nk(t))(2.11)
nk(t)是主题k产生的词汇中词t的个数。进一步,可以得到整个文本集中词生成的概率为
合并公式,可以得到
最终,得到lda模型的gibbssampling公式为:
本实施例以题目关键词为“大自然、食物、人类、科学、耕地”进行作文生成,步骤如下:
(1)选用训练数据集对lda主题模型进行训练,得到文本集主要内容的分布,以及各个句子在主题下的分布。
(2)计算候选句子和文档之间的交叉熵,选择交叉熵较小的句子。
(3)将候选句子按照在原候选文本中的相对位置参数排序。
(4)输出自动生成的作文。
利用自动评价系统对自动生成作文进行评价。
利用训练的lda模型,进行文本生成,其中,文本字数控制在200字左右。再对生成文本的质量进行评价,hsk5作文评分标准如表1所示:
表1hsk作文评分标准
本实施例生成的作文如下:
从古至今,衣、食、住这三个方面,一直都是大自然留给人类最重要也是最困挠着人类的问题。如今没有食物对人类的供给,导致所有的人类遭受到饥饿的痛苦,随着文明的发展,人口的增多,人们不得不借用科学的力量来解决人口增长导致食物不足的问题。但这违背了大自然的规律,虽然短时间内可以满足人类的需求,但人们已意识到不断大量使用化肥和农药使耕地面积逐渐减少。世界上许多国家的农民们生产“绿色食品”,而且人们都希望没有污染的食品。如果不使用化肥,那么粮食产量会大量减少,就不能养活地球上的全部人类。但如果人类一直用农药和化肥来增加粮食产量,而不采取合理措施,那样,后果会更加严重。我想没有健康的家不会幸福的。所以在短时间内人类要合理利用耕地,等待科学有进一步的发展。就像古人创造了耕田一样,我想人类不会那么轻易屈服于大自然。我坚信地球的主人永远都是人类。
可以发现,文本包含所有关键词,且主题清晰,内容切题,逻辑清楚,内容连贯,符合高档分作文的标准。本实施例利用本发明的方法很好地完成了根据关键词写作的任务,生成的文本可以很好地围绕关键词展开,并切合主题。
本发明提供的基于主题模型的hsk作文生成方法,通过训练lda主题模型,得到句子和文本、词语和文本的分布,并通过计算交叉熵,选择与主题关键词最相近的句子,然后生成文本,且自动生成的文本在连贯性和逻辑性上效果好,语法错误较少,错别字较少,能够很好地完成写作任务,可以很好地满足实际应用的需要。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!