一种基于机器学习的数据库性能负载评估系统和方法与流程
本发明是一种基于机器学习的数据库性能负载评估系统和方法,属于人工智能机器学习领域,涉及数据库运维。
背景技术:
数据库应用要求较低的响应时间和高性能,所以在部署数据库应用之前会进行性能负载测试。但是随着数据库应用的持久运行,用户越来越多,数据量越来越大,导致数据库的性能和负载增加,如果不及时加以干预和处理,可能会导致系统宕机等不同程度的故障发生。所以,实时监控数据的性能和负载现在变得相当重要。
目前数据库的性能负载监控工具非常多样,但是这些工具通常只是简单显示一些关键运行指标,有时并不能真实反映数据库的运行状况。当数据库出现高响应和低性能的情形时,通常还是需要dba专家分析,这些监控工具对于问题的定位和分析并没有起到很大的作用。
虽然本领域中常用的性能专家模型和负载专家模型对于普通性能负载监控工具来说,在分析数据库问题和定位故障方面有了很大的提高,但是它也存在下面的一些缺点:
1)专家模型是高级dba多年来知识和经验的积累,这对于数据库运维人员的从业经验和精通程度有很高的要求,无形中提高了人力成本。
2)专家模型除了规则定义,还有复杂的脚本和代码,这需要稳定的开发人员和运维队伍,对人员流通有较高的要求。
3)专家模型是高级dba的经验积累,它对于一些指标和规则的定义是否真实拟合数据库的性能和负载有着不确定性,因为每个dba对于指标和规则的理解都会有些偏差。如果出现一些小概率的异常情况,专家模型的指标并没有涉及到,那么就需要高级dba从大量的历史数据中发现影响性能和负载的因素,这过程旺旺是非常耗时的。
综合以上说明,需要一种新的技术方案以解决上述问题。
技术实现要素:
发明目的:本发明公开一种基于机器学习的数据库性能负载评估系统及评估方法,利用机器学习算法训练数据生成性能负载学习模型,利用此模型对新数据加以预测评估。一方面,该评估系统的结论比专家模型对特征的分析更加合理,更不会遗漏重要的性能负载指标,对数据库性能和负载的问题定位更加准确;另一方面又降低对数据库运维人员的知识和能力要求,可以极大节省人力成本,提供工作效率。
技术方案:为达到上述目的,本发明基于机器学习的数据库性能负载评估系统可采用如下技术方案:
一种基于机器学习的数据库性能负载评估系统,包括:
数据获取模块,用以从数据库awr报告中和数据库日志中抓取特征数据;
数据预处理模块,用以将特征数据中的单一值特征删除,缺失特征删除,高相关性特征删除,同时用以将缺失数据填充、使数据规范化;
训练数据模型模块,用以训练数据生成模型;
模型评估模块,用以根据不同的机器学习模型的评价指标,使用验证集评估模型;
模型调优模块,用以对模型自动调优而调整模型的超参数;
模型预测模块,用以预测模型,分为离线预测和在线预测;离线预测指的是利用训练集分离出来的测试集;在线预测是指数据采集器采集到的实时数据,需要经过缩放器进行数据规范化后在进行预测。
进一步的,数据预处理模块中,单一值特征删除为:当某一列特征值全部相同时,直接删除;
缺失特征删除为:当特征列缺失比例达到特定阈值时则删除该特征列;
高相关特征删除为:通过皮尔逊相关系数计算特征变量之间的相关性,构建相关关系矩阵,当发现特征相关性高于某个阈值时将其中一个特征删除;
缺失值填充包括:用缺失值的前一行数据去填充;用缺失特征列的平均值去填充;性能和负载按照等级划分为a,b,c,d,e,根据各个等级的平均值填充缺失值。
数据规范化为:将原始特征数据进行归一化缩放,采用离差标准化和标准差标准化;数据规范化过程中的缩放器保存于本地,当对新采集的数据进行预测时需要利用该缩放器进行同等程度的数据规范化。
进一步的,训练数据模型模块中,将数据集分为训练集,验证集和测试集。其中训练集,验证集和测试集占数据集的比例分别为70%,15%,15%;
本系统采用集成算法训练模型,梯度提升树算法gbm基于梯度下降算法得到提升数模型。回归模型使用训练器lgbmregressor,分类模型使用训练器lgbmclassifier。
进一步的,在评估模型过程中使用earlystop技术和checkpoint技术;
earlystop:提前停止训练,看发现训练过程中验证集的验证误差不会再发生变化时,训练会在k轮之后自动停止,k为预设值;
checkpoint技术:该技术会自动保存训练过程中最优的训练模型。
进一步的,模型调优模块中的超参数包括:
迭代轮数epochs
学习率learning_rate
设置树深度max_depth
学习器叶子最大数目max_leaves
弱学习器的数量数目n_estimators
损失函数objective。
有益效果:本发明基于机器学习的数据库性能负载评估系统从多个实例的数据库awr报告和数据库日志中提取关于性能和负载的多个特征指标,经过数据加工(数据清洗和转换),将这些海量数据作为训练集并运用机器学习技术加以训练,最终生成性能和负载学习模型,利用此模型对新产生的特征数据进行预测,评估数据库的性能和负载情况。该评估系统的性能回归模型和负载回归模型的均方根误差在4~6左右,性能分类模型和负载分类模型准确率达到99.3左右,已经达到生产应用要求。该系统是人工智能在数据库应用上的一次创新和应用,减少企业的人力成本,达到良好的经济效益。
而对应上述基于机器学习的数据库性能负载评估系统,本发明还提供了基于机器学习的数据库性能负载评估方法的技术方案:
一种基于机器学习的数据库性能负载评估方法,包括以下步骤:
(1)、数据获取:从数据库awr报告中和数据库日志中抓取特征数据;
(2)、数据预处理:将特征数据中的单一值特征删除,缺失特征删除,高相关性特征删除,同时用以将缺失数据填充、使数据规范化;
(3)训练数据生成模型;
(4)、评估模型:根据不同的机器学习模型的评价指标,使用验证集评估模型;
(5)、模型调优:对模型自动调优而调整模型的超参数;
(6)、模型预测:分为离线预测和在线预测;离线预测指的是利用训练集分离出来的测试集;在线预测是指数据采集器采集到的实时数据,需要经过缩放器进行数据规范化后在进行预测。
步骤(2)中,单一值特征删除为:当某一列特征值全部相同时,直接删除;
缺失特征删除为:当特征列缺失比例达到特定阈值时则删除该特征列;
高相关特征删除为:通过皮尔逊相关系数计算特征变量之间的相关性,构建相关关系矩阵,当发现特征相关性高于某个阈值时将其中一个特征删除;
缺失值填充包括:用缺失值的前一行数据去填充;用缺失特征列的平均值去填充;性能和负载按照等级划分为a,b,c,d,e,根据各个等级的平均值填充缺失值。
数据规范化为:将原始特征数据进行归一化缩放,采用离差标准化和标准差标准化;数据规范化过程中的缩放器保存于本地,当对新采集的数据进行预测时需要利用该缩放器进行同等程度的数据规范化。
步骤(3)中,将数据集分为训练集,验证集和测试集。其中训练集,验证集和测试集占数据集的比例分别为70%,15%,15%;
本系统采用集成算法训练模型,梯度提升树算法gbm基于梯度下降算法得到提升数模型。回归模型使用训练器lgbmregressor,分类模型使用训练器lgbmclassifier。
步骤(4)中,使用earlystop技术和checkpoint技术;
earlystop:提前停止训练,看发现训练过程中验证集的验证误差不会再发生变化时,训练会在k轮之后自动停止,k为预设值;
checkpoint技术:该技术会自动保存训练过程中最优的训练模型。
步骤(5)中的超参数包括:
迭代轮数epochs
学习率learning_rate
设置树深度max_depth
学习器叶子最大数目max_leaves
弱学习器的数量数目n_estimators
损失函数objective。
有益效果:对应上述基于机器学习的数据库性能负载评估系统的有益效果,本负载评估方法做出的结论比专家模型对特征的分析更加合理,更不会遗漏重要的性能负载指标,对数据库性能和负载的问题定位更加准确;另一方面又降低对数据库运维人员的知识和能力要求,可以极大节省人力成本,提供工作效率。
附图说明
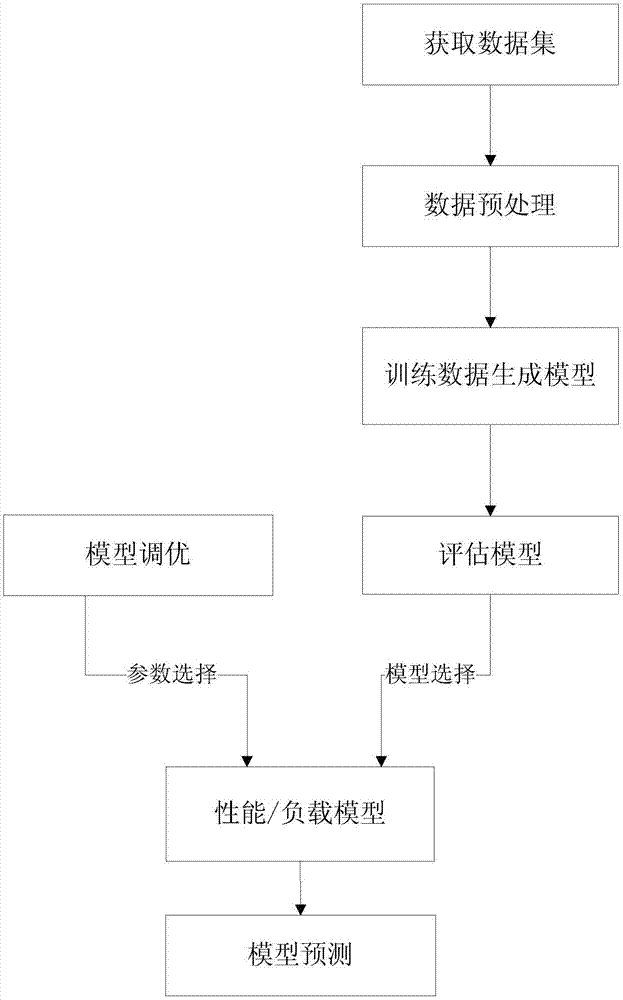
图1是本评估系统中基于机器学习的数据库性能负载评估方法的流程图。
具体实施方式
请结合图1所示,
本发明提供一种基于机器学习的数据库性能负载评估系统,包括:
数据获取模块,用以从数据库awr报告中和数据库日志中抓取特征数据;
数据预处理模块,用以将特征数据中的单一值特征删除,缺失特征删除,高相关性特征删除,同时用以将缺失数据填充、使数据规范化;
训练数据模型模块,用以训练数据生成模型;
模型评估模块,用以根据不同的机器学习模型的评价指标,使用验证集评估模型;
模型调优模块,用以对模型自动调优而调整模型的超参数;
模型预测模块,用以预测模型,分为离线预测和在线预测;离线预测指的是利用训练集分离出来的测试集;在线预测是指数据采集器采集到的实时数据,需要经过缩放器进行数据规范化后在进行预测。
数据预处理模块中,单一值特征删除为:当某一列特征值全部相同时,直接删除;
缺失特征删除为:当特征列缺失比例达到特定阈值时则删除该特征列;
高相关特征删除为:通过皮尔逊相关系数计算特征变量之间的相关性,构建相关关系矩阵,当发现特征相关性高于某个阈值时将其中一个特征删除;
缺失值填充包括:用缺失值的前一行数据去填充;用缺失特征列的平均值去填充;性能和负载按照等级划分为a,b,c,d,e,根据各个等级的平均值填充缺失值。
数据规范化为:将原始特征数据进行归一化缩放,采用离差标准化和标准差标准化;数据规范化过程中的缩放器保存于本地,当对新采集的数据进行预测时需要利用该缩放器进行同等程度的数据规范化。
训练数据模型模块中,将数据集分为训练集,验证集和测试集。其中训练集,验证集和测试集占数据集的比例分别为70%,15%,15%;
本系统采用集成算法训练模型,梯度提升树算法gbm基于梯度下降算法得到提升数模型。回归模型使用训练器lgbmregressor,分类模型使用训练器lgbmclassifier。
在评估模型过程中使用earlystop技术和checkpoint技术;
earlystop:提前停止训练,看发现训练过程中验证集的验证误差不会再发生变化时,训练会在k轮之后自动停止,k为预设值;
checkpoint技术:该技术会自动保存训练过程中最优的训练模型。
模型调优模块中的超参数包括:
迭代轮数epochs
学习率learning_rate
设置树深度max_depth
学习器叶子最大数目max_leaves
弱学习器的数量数目n_estimators
损失函数objective
请再结合图1所示,本评估系统中基于机器学习的数据库性能负载评估方法包括:
1、获取数据集。
使用postgresql数据库存取oracle数据库的awr报告和log日志的性能负载指标,抓取数据按照平均3分钟抓取。在awr数据表中的特征数据有62维,日志表中的特征数据有200维,利用python脚本按照抓取时间的先后顺序将postgresql数据表中的数据保存在本地csv文件中。
2、数据预处理。
单一值特征删除:当某一列特征值全部相同时,对模型的拟合没有任何帮助,还增加计算量,可以直接删除。
缺失特征删除:当特征列缺失比例达到特定阈值时则删除该特征列,本系统中缺失阈值设置为60%。
高相关特征删除:通过皮尔逊相关系数计算特征变量之间的相关性,构建相关关系矩阵,当发现特征相关性高于某个阈值时将其中一个特征删除,本系统相关性阈值设置为0.9。
缺失值填充:在获取数据工程中出现缺失数据是不可避免的,我们只有尽可能去拟合缺失值。本系统中使用三种方法:
用缺失值的前一行数据去填充。
用缺失特征列的平均值去填充。
性能和负载按照等级划分为a,b,c,d,e,根据各个等级的平均值填充缺失值。
数据规范化:将原始特征数据进行归一化缩放,本系统采用两种方法:离差标准化(min-maxnormalization)和标准差标准化(zero-meannormalization)。数据规范化过程中的缩放器保存于本地,当对新采集的数据进行预测时需要利用该缩放器进行同等程度的数据规范化。
在分类模型中,需要根据性能得分和负载得分按区间来划分性能等级和负载等级,具体如下:
3、训练数据生成模型
将数据集分为训练集,验证集和测试集。其中训练集,验证集和测试集占数据集的比例分别为70%,15%,15%。
本系统采用集成算法训练模型,梯度提升树算法gbm基于梯度下降算法得到提升数模型。回归模型使用训练器lgbmregressor,分类模型使用训练器lgbmclassifier。
4、评估模型
在评估模型过程中使用earlystop技术和checkpoint技术。
earlystop:提前停止训练,看发现训练过程中验证集的验证误差不会再发生变化时,训练会在k轮之后自动停止,k可设置。这样就不会发生无效的训练过程,提升训练效率。
checkpoint技术:该技术会自动保存训练过程中最优的训练模型,即使发生异常导致训练停止也可以及时保存训练成果。
5、模型调优
模型调优功能利用hyopt调整模型的超参数,主要参数包括:
迭代轮数epochs
学习率learning_rate
设置树深度max_depth
学习器叶子最大数目max_leaves
弱学习器的数量数目n_estimators
损失函数objective
6、模型预测
离线预测:利用训练集中的数据在调优后的模型中进行预测,并
实时预测:从数据库中实时抓取数据进行预测,展示预测结果并将该新数据插入到历史数据中,以备后期更新模型时做训练集使用。
另外,本发明的具体实现方法和途径很多,以上所述仅是本发明的优选实施方式。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!