一种基于缺陷规则和分类反馈的缺陷发现方法与流程
本发明属于软件工程
技术领域:
,特别是涉及一种基于缺陷规则和分类反馈的缺陷发现方法。
背景技术:
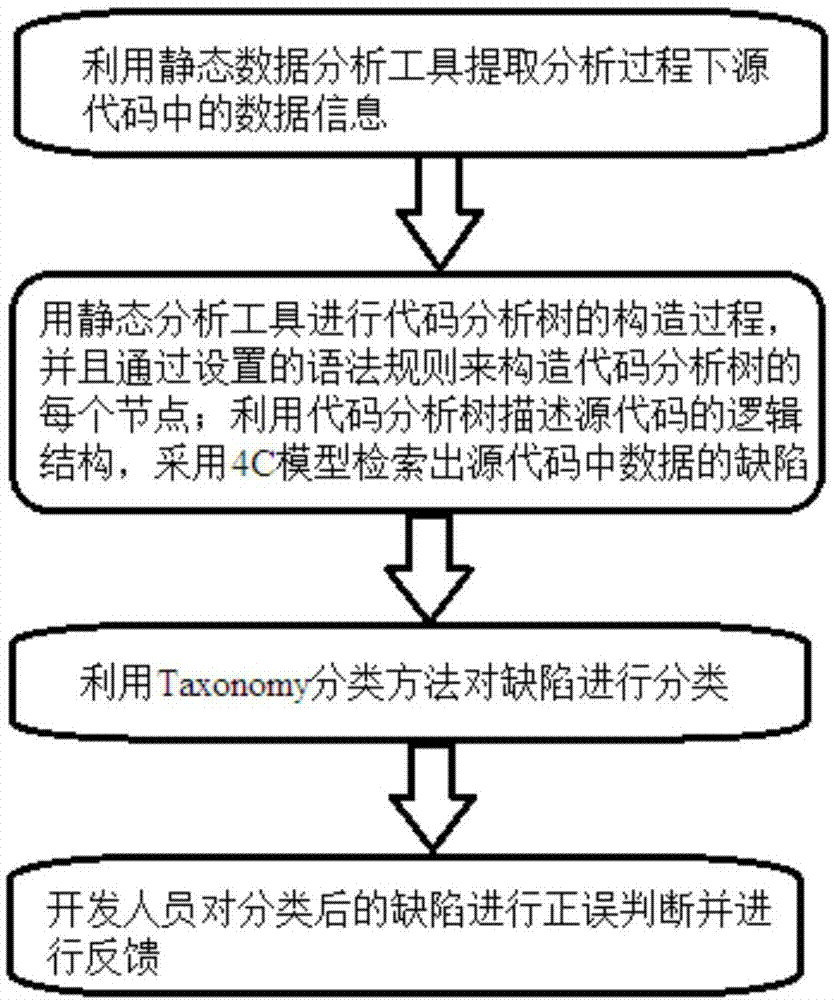
:随着软件的规模和复杂度日益增加,快速而可靠的缺陷修复成为软件工程的一个重大挑战。软件测试是软件工程中的一个重要阶段,技术人员渴望能在源代码中准确而迅速地发现缺陷。近年来,许多源代码检查技术已经研发出来。然而,缺陷检索的结果并不比预期好。缺陷分类和反馈技术的缺乏成为了主要的原因。在现实中,有必要分类这些缺陷并且在缺陷检索过程后考虑开发人员的建议。技术实现要素:本发明目的是为了解决现有技术中存在的问题,提出了一种基于缺陷规则和分类反馈的缺陷发现方法。所述方法可以提高缺陷发现的准确度,开发人员以及测试人员可以较容易地发现这些软件缺陷。本发明的目的通过以下技术方案实现:一种基于缺陷规则和分类反馈的缺陷发现方法,包括以下步骤:步骤一、利用静态数据分析工具提取分析过程下源代码中的数据信息;步骤二、用静态分析工具进行代码分析树的构造过程,并且通过设置的语法规则来构造代码分析树的每个节点;利用代码分析树描述源代码的逻辑结构,采用4c模型检索出源代码中数据的缺陷;步骤三、利用taxonomy分类方法对缺陷进行分类;步骤四、开发人员对分类后的缺陷进行正误判断并进行反馈。进一步地,所述4c模型指的是概念、内容、上下文和类别属性的模型;所述概念包括错误信息,所述错误信息为身份、级别、修复类别和确定性;所述内容展示的是关于缺陷和相关代码的细节信息,所述细节信息为语法规则、源代码和解决方案;所述上下文是说明树结构上的子节点和母节点中的缺陷;所述类别属性展示的是缺陷的等级分数。进一步地,所述步骤二具体为:步骤二一、扫描:通过扫描源代码文件,形成源代码里的数据流并且提取信息;步骤二二、建分析树:根据提取的信息,决定节点的类型,在关联关键词的子树上的所有节点都能被建立,因此分析树便可以建立了;步骤二三、遍历:通过遍历所有的节点,静态分析工具分析每一个声明并记录相关的执行结果;步骤二四、找到缺陷:通过多个源代码文件的历史记录,从而定义缺陷规则,并且依次最终找到缺陷。进一步地,当静态分析过程已经完成后,缺陷根据相关的缺陷规则进行分类,进而扫描缺陷类型的关键词,核实缺陷的等级与相关的缺陷类型,由此分类树也就建造完成,分类过程结束。进一步地,所述缺陷类型为数组的范围超出边界、变量未初始化、非可执行节点和方法不能准确使用。进一步地,在反馈环节中,开发人员通过运用经验和知识判断一个返回的缺陷是正确、接近正确、接近错误还是错误。进一步地,在代码分析树的构造过程中,需要进行句法和语法分析;句法分析中的单词符号是由从左到右扫描源代码的每个字符产生的,而语法分析中代码分析树是利用语法分析中的符号所构造的;每一个节点对应一个调用方法,该调用方法用于构造节点类的对象。进一步地,所述缺陷规则定义为:软件缺陷是计算机程序的一个缺陷,使之无法正常工作,软件缺陷是由源代码文件产生的,缺陷规则则由缺陷的源代码文件的历史所总结,缺陷规则指示如何判断源代码中的缺陷。本发明相较于其他方法的优点为:在其他方法从源代码中检索缺陷时,往往准确度不够高。而4cmodel采用了开发人员的反馈意见来提高缺陷检索的准确度。可以让新手从静态分析工具的缺陷列表中理解这些缺陷。附图说明图1是本发明所述基于缺陷规则和分类反馈的缺陷发现方法的流程图;图2是4c模型框图;图3是基于cat静态分析工具的检索结果图;图4是分类过程示意图;图5是缺陷规则示意图;图6是缺陷信息示意图;图7是缺陷评级示意图。具体实施方式下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。结合图1,本发明提出一种基于缺陷规则和分类反馈的缺陷发现方法,包括以下步骤:步骤一、利用静态数据分析工具提取分析过程下源代码中的数据信息;静态数据分析的主要特征是代码分析过程不需要依靠于程序的执行。并且该数据分析可以根据缺陷规则从而通过数据库分析实现。许多编程语言包括顺序结构,选择结构和循环结构。因此,通过检索这些结构来进行数据库分析,用于分析每个语句,根据缺陷规则检索缺陷。步骤二、用静态分析工具进行代码分析树cat的构造过程,并且通过设置的语法规则来构造代码分析树cat的每个节点;利用代码分析树cat描述源代码的逻辑结构,采用4c模型检索出源代码中数据的缺陷;所述4c模型指的是概念concept、内容contents、上下文context和类别属性category的模型;所述概念包括错误信息,所述错误信息为身份、级别(警告级别)、修复类别和确定性;所述内容展示的是关于缺陷和相关代码的细节信息,所述细节信息为语法规则、源代码和解决方案;所述上下文是说明树结构上的子节点和母节点中的缺陷;所述类别属性展示的是缺陷的等级分数。所述方法按照流程主要是通过两阶段缺陷定位算法实现最终寻找缺陷的目标。在第一阶段,4c模型model检索出源代码中的缺陷,依照缺陷规则对缺陷进行分析和分类。在第二阶段,针对分类后的缺陷,开发人员进行反馈,判断缺陷的正误。图2显示了4c模型model的构建组件。所述步骤二具体为:步骤二一、扫描:通过扫描源代码文件,形成源代码里的数据流并且提取信息;步骤二二、建分析树:根据提取的信息,决定节点的类型,在关联关键词的子树上的所有节点都能被建立,因此分析树便可以建立了;步骤二三、遍历:通过遍历所有的节点,静态分析工具分析每一个声明并记录相关的执行结果;步骤二四、找到缺陷:通过多个源代码文件的历史记录,从而定义缺陷规则,并且依次最终找到缺陷。在cat中,每个节点都表示了类的对象,其中所有基本类,如编译单位,程序包声明,输入声明和类型声明,都继承了astn节点,其中astn节点定义了类似集合母节点和增加子节点等方法。在代码分析树的构造过程中,需要进行句法和语法分析;句法分析中的单词符号是由从左到右扫描源代码的每个字符产生的,其中包括关键词,标识符,运算符等等。返回值是一个整数变量,它反映了需要构造cat的哪一个节点。而语法分析中代码分析树是利用语法分析中的符号所构造的;每一个节点对应一个调用方法,该调用方法用于构造节点类的对象。例如,节点类编译单元对应于方法编译单元,而程序包声明对应于程序包声明的方法。cat的构建过程中需注明类测试的情况,类测试用于计算两个整数之间的商和余数。首先,通过调用方法compilationunit(编译单元)来构造根节点。扫描关键程序包时,返回一个积分参数。此参数确定节点的类型。然后,通过调用相关的方法packagedeclaration(程序包声明)来构造节点packagedeclaration(程序包声明)。语法规则packagedeclaration=packagename的右边部分表示调用方法name()来构造packagedeclaration(程序包声明)的子节点。子节点由程序包的名称(test)表示。因此,与关键词程序包相对应的子树上的所有节点都被构造出来了。接下来,用自上至下的方法完成cat的建造过程,这种分析方法从最后开始研究源代码。如果方法找到对应于语法规则的语句,就会形成子树和相关的子节点。这个过程一直持续到根节点compilationunit(编译单元),此时cat构建完成。步骤三、利用taxonomy分类方法对缺陷进行分类;以java语言为例,缺陷类型主要分为四种,分别是数组的范围超出边界、变量未初始化、非可执行节点和方法不能准确使用(例如equals,hashhashcode或ctone)。根据这四种类型,taxonomy这种由超类型和图表类型构建的整体对缺陷进行分类。当静态分析过程已经完成后,缺陷根据相关的缺陷规则进行分类,进而扫描缺陷类型的关键词,核实缺陷的等级与相关的缺陷类型,由此分类树也就建造完成,分类过程结束。taxonomy是分类的实践和科学,taxonomy或taxonomy方案是一种特殊的分类,排列在一个层次结构中。通常这是由超类型子类型关系或不太正式的亲子关系组织起来的。taxonomy是分类领域的一项重要技术。从数学上讲,层次分类法是对给定的一组对象进行分类的树结构。当静态分析过程已经完成后,缺陷根据相关的缺陷规则进行分类,从而形成一个分类树。具体是通过静态分析,找出并记录cat的缺陷,根据相关的缺陷规则,这些缺陷被安排为适合的缺陷类型。进而扫描这些缺陷类型的关键词并分类,核实缺陷的等级与相关的缺陷类型,因此建造一个分类树,完成分类过程。下面给出缺陷规则的定义。缺陷规则定义:软件缺陷是计算机程序的一个缺陷,使之无法正常工作。通常,软件缺陷是由源代码文件产生的,缺陷规则则由缺陷的源代码文件的历史所总结,缺陷规则指示如何判断源代码中的缺陷。语法规则不同于缺陷规则。语法规则是通过扫描声明和相关的语法结构来执行静态分析,它来自于语法数据库并且被用作静态分析工具去寻找缺陷。缺陷规则用来对缺陷进行分类,以致于让开发人员能轻松调试相关的源代码。同时,每一个语法规则都和一些缺陷规则相关联。本发明就是用缺陷规则对历史数据库中产生的缺陷进行分类。例如,“数组变量arr[]没有被分配”是语法数据库中的语法规则,它映射一个缺陷规则,“数组变量[]没有被赋值”=变量没有被初始化90%(90%是确定性)。步骤四、开发人员对分类后的缺陷进行正误判断并进行反馈。在缺陷分类后,增加了反馈环节。在反馈环节中,开发人员通过运用经验和知识判断一个返回的缺陷是正确、接近正确、接近错误还是错误。根据记录和分析这些开发人员的建议,寻找缺陷的准确率得以提高。通过对4个寻找方法的比较,表1显示出4cmodel比其他方法多了反馈环节,并且依据该环节可以提高寻找缺陷的准确度。同时,开发人员可以估计缺陷等级,判断检索的缺陷的正误。综上,4cmodel可以更全面的完成寻找缺陷的任务。表14c模型方法和其他缺陷发现方法的性能比较criticismfindbugsdynaminehwpourworkbugretrievalyesyesyesyesclassificationyesyesnoyesrankingyesyesn/an/afeedbacknononoyes下面用一个例子来展示本发明所述方法的可行性,本案例研究由以下三个步骤组成。图3为基于cat静态分析工具的检索结果。a.缺陷检索图3左上角显示了一个c#的源代码文件,包含了循环结构和选择结构。通过静态分析,可以注意到有四个缺陷,并且给出相关的语法规则。如果用户选择一个缺陷,该工具将显示该缺陷的详细信息。图3的底部详细显示了缺陷的相关项。在这一部分中可以发现这个缺陷的一些属性,如目标,身份,位置等。对用户来说更意外的是,该工具提供了这个缺陷的解决方案,以便于调试方便用户。b.错误分类通过基于cat的静态分析,发现了一些缺陷。为了调试这些缺陷,用户需要知道缺陷属于哪个类型。因此,有必要进行分类过程。图4显示了这个过程。在图4中,注意到有一个由分类算法构成的树结构。根据缺陷规则,这些缺陷被分类。例如,缺陷“arg(字符串)”(缺陷的实名)被安排为类型二,和类型三(非可执行节点)。因为其他缺陷不符合缺陷规则,所以它们被归类为其他缺陷。开发者可以通过点击查看相关的缺陷规则(“查看规则”)按钮。图5显示缺陷规则的截图。在图5中显示了两个缺陷规则。根据语法规则和缺陷规则的映射关系,语法规则“复查未使用参数”对应缺陷规则“复查未使用参数”=“未初始化变量”,“复查未使用参数”=“非可执行节点”。这意味着语法规则“评审静态分析工具的未使用参数”发现的缺陷应该分别归类为变量未初始化或不可执行、95%和85%的确定性。当开发人员点击“检查信息”按钮时,会显示所选缺陷的详细信息。图6显示了缺陷信息,包括信息和细节。开发人员可以点击“check”(检查)按钮来检查相关的源代码。c.反馈为了提高缺陷检索的准确性,识别这些缺陷是很重要的。因此,需要邀请一些有经验的开发人员来决定这些缺陷的真相。当开发人员单击按钮(评级)时,就可以选择相关的项目来判断所选缺陷的真实性。图7给出了缺陷评级过程。在图7中,开发人员选择了“真的”。这意味着开发人员决定数组变量args[j未初始化]。利用本发明所述方法发现分类的缺陷是事实。以上对本发明所提供的一种基于缺陷规则和分类反馈的缺陷发现方法,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1