一种基于OCR字形相近文字识别方法与流程
本发明涉及计算机
技术领域:
,特别是涉及模式识别和深度学习领域,更具体地涉及一种基于ocr字形相近文字识别方法。
背景技术:
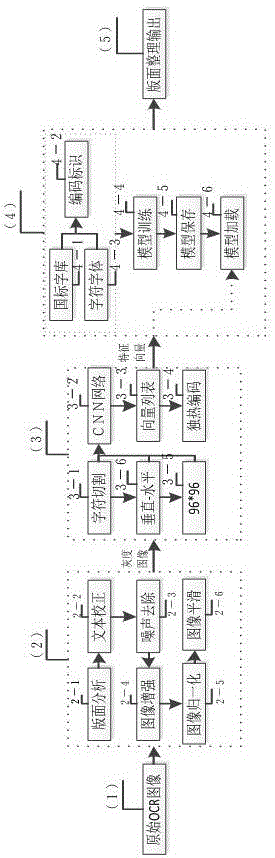
:光学字符识别(opticalcharacterrecognition,简称ocr)是结合光学技术和计算机技术将印在纸上的图像文件转化为文本文件的一种方式,ocr识别可用于银行票据、大量文献资料、档案卷宗、税务单等票据的自动扫描和长期存储。ocr识别通常以识别率、识别速度、版面理解和版面重构度作为衡量的技术标准。该技术对一般字符有比较好的识别率,但是对于结构和字形丰富的汉字领域还存在一定的技术难题,特别是对于字形相近,如:(午、干、干)、(跑、泡、炮)等字符存在识别效率低下和精度不高的问题。此外现有技术对字符的相同字形不同字体无法判断,相同字形不同字体进行识别时非常容易发生错误,多次反复识别结果不一,有时需要人工介入纠错,大幅降低识别准确性。技术实现要素:本发明提供一种识别率高、识别快捷和精度高的基于ocr字形相近文字识别方法。本发明解决其技术问题所采用的技术方案为:一种基于ocr字形相近文字识别方法,包括如下步骤:a、原始ocr图像预处理对倾斜字符进行文本校正,对图片中的噪声去除,对图像对比度和gamma校正转化为灰度图像;b、图像文字检测对预处理的灰度图像进行字符像素特征信息的提取,并采用cnn神经网络进行字符像素特征信息的提取将其转化为独热编码形式的特征向量,作为字符识别模块字符像素特征信息识别的依据;c、识别计算使用标准字库的不同字体作为训练样本n,标准字库的每种不同字体记为n1、n2、、、,计算出训练样本每种字体的欧氏距离dn1、dn2、、、,字符识别模块采用google-inception-v4构架,对待识别图像文字进行识别作为识别样本p,计算出识别样本p的欧式距离dp,使用如下公式计算出识别样本与不同字体训练样本对比阈值a,、、、、;d、字符文本字体识别选择对比阈值a1、a2、、、中0.4-0.6的一个训练样本,输出相对应的识别字符的文本和字体。所述步骤b中对预处理的灰度图像进行字符像素特征信息的提取,通过水平分割和垂直分割将每个字符切割成大小为96*96像素。所述步骤c中训练样本n用国标一级字库3755个字符的16种字体。所述步骤d中选择对比阈值a1、a2、、、中最接近0.5的一个训练样本,输出相对应的识别字符的文本和字体。所述步骤c中字符识别模块采用google-inception-v4构架,将5*5的二维卷积核拆分成1*5和5*1的一维卷积核。本发明的有益效果为:1、改变传统字形识别方式,对字符文本和字体均可进行识别,通过多样本对比并加入阈值筛选,不仅大幅提升文本识别准确性,而且有效识别字符字体。特别适合相似字形和相似字体的字符识别,实现字形和字体的双重准确识别。2、通过水平分割和垂直分割将每个字符切割成大小为96*96像素,便于像素特征信息的提取,避免相邻文字间相互干扰,有效提升识别效率,本发明设计人员将书籍、报纸、衣服和截屏等多种图片中每个字符切割成96*96像素进行字符像素特征信息的提取,提取率接近100%。3、本发明在对比阈值a1、a2、、、中选择最接近0.5的一个训练样本,输出相对应的识别字符的文本和字体,提升识别准确性,避免了人工介入纠错。4、字符识别模块采用google-inception-v4构架,将5*5的二维卷积核拆分成1*5和5*1的一维卷积核,不仅防止过拟合还增加非线性扩展能力和保留字符特征多样性。附图说明图1为本发明的识别示意图。具体实施方式一种基于ocr字形相近文字识别方法,包括如下步骤:a、原始ocr图像预处理对倾斜字符进行文本校正,对图片中的噪声去除,对图像对比度和gamma校正转化为灰度图像;b、图像文字检测对预处理的灰度图像进行字符像素特征信息的提取,并采用cnn神经网络进行字符像素特征信息的提取将其转化为独热编码形式的特征向量,作为字符识别模块字符像素特征信息识别的依据;c、识别计算使用标准字库的不同字体作为训练样本n,标准字库的每种不同字体记为n1、n2、、、,计算出训练样本每种字体的欧氏距离dn1、dn2、、、,字符识别模块采用google-inception-v4构架,对待识别图像文字进行识别作为识别样本p,计算出识别样本p的欧式距离dp,使用如下公式计算出识别样本与不同字体训练样本对比阈值a,、、、、;d、字符文本字体识别选择对比阈值a1、a2、、、中0.4-0.6的一个训练样本,输出相对应的识别字符的文本和字体。所述步骤b中对预处理的灰度图像进行字符像素特征信息的提取,通过水平分割和垂直分割将每个字符切割成大小为96*96像素。所述步骤c中训练样本n用国标一级字库3755个字符的16种字体。所述步骤d中选择对比阈值a1、a2、、、中最接近0.5的一个训练样本,输出相对应的识别字符的文本和字体。所述步骤c中字符识别模块采用google-inception-v4构架,将5*5的二维卷积核拆分成1*5和5*1的一维卷积核。对比试验1以干三字的宋体作为案例进行测试:设置字形干扰项于、午;设置字体干扰项黑体和仿宋;测试方法如下:筛选宋体干、黑体干、仿宋干;宋体于、黑体于、仿宋于;宋体午、黑体午、仿宋午等9幅图片;经人工识别为干3例、于3例和午3例;采用zol软件下载网的汉王ocr免费中文版、起点软件园网的orc软件v8.1进行多次对比测试,具体对比结果如下:本发明汉王ocrorc软件v8.1第一次干3例、于3例、午3例干4例、于2例、午3例干3例、于3例、午3例第二次干3例、于3例、午3例干5例、于3例、午1例干1例、于4例和午4例第三次干3例、于3例、午3例干3例、于3例、午3例干2例、于2例和午5例结果分析从单一图片字形识别上看,本发明、zol软件下载网的汉王ocr免费中文版、起点软件园网的orc软件v8.1均可对字形文本进行识别,但现有技术存在不稳定性,干扰项对现有识别软件会产生一定影响,识别结果不稳定,需要人工介入纠错。本发明对9幅图片的对比阈值均选自0.4-0.6中最接近0.5的一个,如果图片严重不清晰或无法有效识别,对比阈值会落入0.1-0.3或0.7-0.9之间,实现自动纠错提示。对比试验2本发明和谷歌公司申请的用于分布式光学字符识别和分布式机器语言翻译的技术(cn201580029025.7)的技术相比,本发明通过对比阈值0.5的接近度判断字体。对比文件cn201580029025.7的技术无法对字体进行判断。综上所述本案特别适合相似字形和相似字体的字符识别,实现字形和字体的双重准确识别。现有技术中均未双重准确识别的技术公开,此外本发明的方法方便与现有软件进行植入,保证识别效率的基础上大幅降低识别软件开发难度。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1