一种基于CRBM和SNN进行鲁棒性语音性别分类的方法与流程
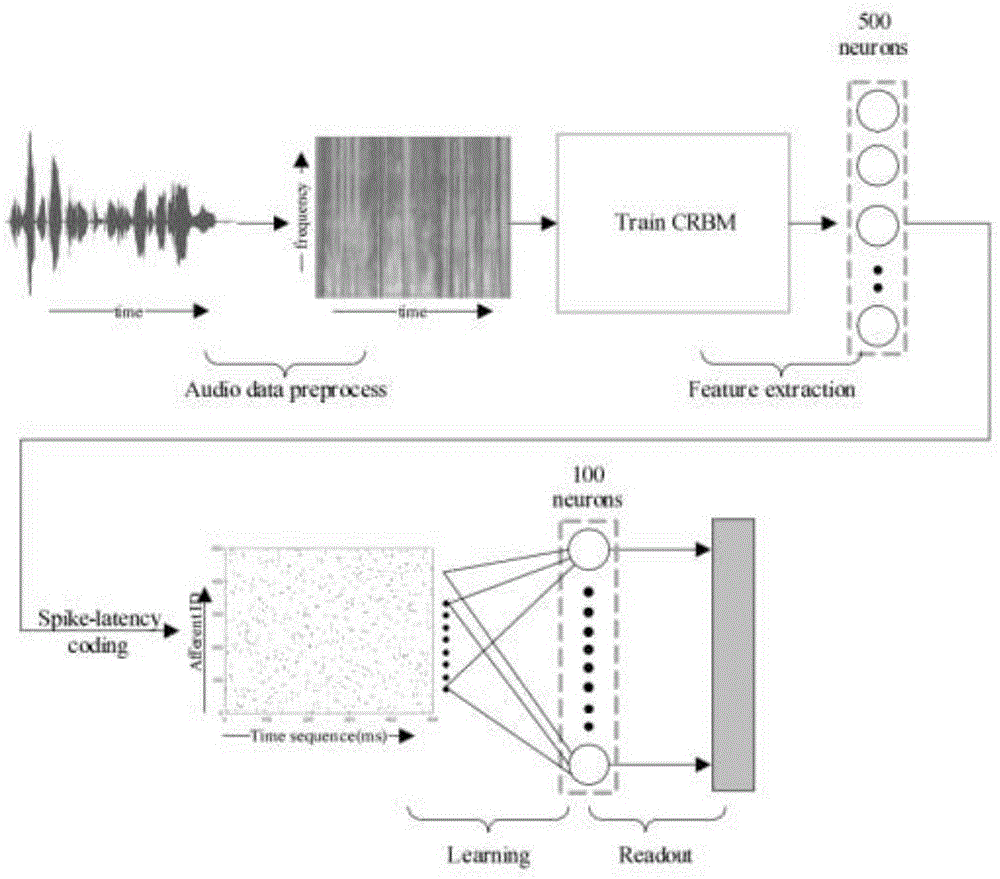
本发明属于类脑计算领域,具体涉及一种基于crbm和snn进行鲁棒性语音性别分类的方法。
背景技术:
:脉冲神经网络由于更加具有生物可塑性而受到越来越多的关注。传统的人工神经网络和脉冲神经网络的主要不同点在于编码方式和处理方式的不同,传统的人工神经网络通过脉冲触发的平均速率来编码,而脉冲神经网络采用脉冲触发的时序进行编码。脉冲神经网络能够处理带有时间序列信息的能力,使得它比传统的人工神经网络更能处理带有时间结构的数据。应用脉冲神经网络处理分类的任务,有两个主要的挑战:信息编码和脉冲学习。信息编码指如何将外界刺激(如声音)转换成脉冲序列。不同的编码方式对学习性能有不同的影响,因此需要一个有效的编码方式来加速学习,提高神经网络的性能。有研究表明,卷积受限玻尔兹曼机(crbm)能够有效地提取声音特征,在性别分类上优于传统的mfcc方法。因此,crbm作为特征提取器来提取特征,然后又采用了脉冲时滞编码将提取到的特征转换成带有时间结构的脉冲序列。技术实现要素:针对以上技术问题,本发明提出了一种基于crbm和snn的系统方法来进行性别分类的任务,将脉冲神经网络应用在语音处理领域,丰富了脉冲神经网络的应用研究。本发明的技术方案为:一种基于crbm和snn进行鲁棒性语音性别分类的方法,包括以下步骤:步骤一,语音数据集预处理:从语音数据库中选择若干句不同信噪比的语音数据并随机分为训练集和测试集两组;将所述语音数据通过快速傅里叶变换转换为语谱图,再经过pca操作对语谱图进行预处理降维操作;步骤二,数据特征编码:1)特征提取:运用无监督方法crbm进行特征提取,选择500组滤波器进行训练,crbm训练得到的特征值进行从大到小排序,特征值的大小代表了脉冲传播的顺序;2)脉冲序列生成:根据所提取特征值的大小和产生脉冲的时间成反比的原则生成脉冲图,每个神经元在编码时间窗内只产生一个脉冲;步骤三,tempotron神经元的训练:通过脉冲神经网络结合tempotron学习算法处理脉冲序列,计算神经元后突触膜电位,膜电位的计算如公式(1)-(2):其中,k(t-ti)代表在t时间下ti时间点传入的脉冲的贡献,当膜电位v(t)超过一个固定的阈值时,神经元就会发放一个脉冲,并很快地降至复位点位并维持一小段时间,然后接受前段突触的输入脉冲重新升高膜电位;步骤四,读出部分:采用分组设计,根据学习神经元的响应对刺激信号进行分类,具体为将tempotron神经元分为激活或者不激活两种状态,使所有状态下的tempotron神经元都响应它们对应的目标类别,同时对不属于目标类别的神经元保持不变,最终根据投票法来对分类结果进行判定。进一步地,所述步骤一中预处理降维操作的具体方法为:对每句话提取语谱图时,窗长设置为16ms,窗移设置为8ms,窗函数使用的是汉明窗,pca组分设置为80。进一步地,所述步骤一中训练集和测试集的语句一半来自于男性,一半来自于女性,并且训练集和测试集来自于不同的说话人。进一步地,步骤二中crbm训练时主要包括前向计算和反向计算过程,概率分布的定义如公式(3)-(4):p(vi|h)=normal(∑k(wk*hk)i+c,1)(4)进一步地,步骤三中所述tempotron是一个梯度下降学习算法,在处理性别分类问题时,每一个输入模式属于男女两类当中的一类,分别通过p+和p-表示,神经元通过激活或者不激活来做决策,当p+模式出现时神经元应该激活,p-模式出现时不应该激活,如果出现其他情况,tempotron规则将调整突触权重以得到更合适的值;tempotron学习规则如公式(5):其中,tmax表示在一个时间窗内该输出层神经元达到电压最大值的时刻,λ代表学习率;如果在p+模式神经元没有发放脉冲,则增加突触权重,相反,如果在p-模式神经元错误发放脉冲,则减少突触权重。进一步地,所述步骤四中每一类采用分组设计,使得在一定时间窗内获得更多的特征信息,其中每50个神经元组成一组代表一类,以提高性别分类的性能。与现有技术相比,本发明的有益效果为:与传统的人工神经网络相比,脉冲神经网络具有时间信息处理特性,更加适合处理带有时间结构的语音信号。本发明利用crbm来作为特征提取器提取特征,再利用脉冲迟滞编码层将特征转化为脉冲图,然后通过tempotron学习规则来学习,最后读出分类。结果表明本发明提出的方法在噪声环境下可以有效的对性别进行分类。附图说明图1是本发明提出的基于crbm和snn进行鲁棒性语音性别分类的方法架构图;图2是本发明实施例中显示了一个编码的脉冲图。具体实施方式为了更好地理解本发明的技术方案,现结合附图及具体实施方式来对本发明进行更进一步详细的描述。图1是本发明的基于crbm和snn进行鲁棒性语音性别分类的方法架构图,主要包含以下步骤:步骤一,语音数据集预处理:从timit数据库中选择训练集700句话,测试集100句话,其中一半来自于男性,一半来自于女性,并且训练集和测试集来自于不同的说话人。如表2所示,为了证明本发明的鲁棒性,分别采用了干净以及20db、10db、0db的信噪比的语音数据,将这些语音数据首先通过快速傅里叶变换转换为语谱图,再经过pca操作对语谱图进行预处理降维操作。其中,对于每个句子,音频的采样率是16000hz,对每句话提取语谱图时,窗长设置为16ms,窗移设置为8ms,窗函数使用的是汉明窗,pca组分设置为80。步骤二,数据特征编码:特征提取采用的是crbm方法,crbm是一种无监督学习方法,由可见层和隐藏层两部分组成,crbm训练时主要包括前向计算和反向计算过程,概率分布的定义如公式(3)-(4):p(vi|h)=normal(∑k(wk*hk)i+c,1)(4)crbm训练完之后,将提取到的特征通过脉冲时滞编码转换为带有时序的脉冲图,即将crbm训练得到的特征值进行从大到小排序,值的大小代表了脉冲传播的顺序,根据值的大小和产生脉冲的时间成反比的原则生成脉冲图,每个神经元在编码时间窗内只产生一个脉冲,一个编码的脉冲图如图2所示。步骤三,tempotron神经元的训练:通过脉冲神经网络结合tempotron学习算法处理脉冲序列,计算神经元后突触膜电位,膜电位的计算如公式(1)-(2):其中,k(t-ti)代表在t时间下ti时间点传入的脉冲的贡献,当膜电位v(t)超过一个固定的阈值时,神经元就会发放一个脉冲,并很快地降至复位点位并维持一小段时间,然后接受前段突触的输入脉冲重新升高膜电位。tempotron是一个梯度下降学习算法,在处理性别分类问题时,每一个输入模式属于男女两类当中的一类(p+和p-)。神经元通过激活或者不激活来做决策。当p+模式出现时神经元应该激活,p-模式出现时不应该激活,如果出现其他情况,tempotron规则将调整突触权重以得到更合适的值。tempotron学习规则如公式(5):其中,tmax表示在一个时间窗内该输出层神经元达到电压最大值的时刻,λ代表学习率;如果在p+模式神经元没有发放脉冲,则增加突触权重,相反,如果在p-模式神经元错误发放脉冲,则减少突触权重。步骤四,读出部分:根据学习神经元的响应对刺激信号进行分类,对每一类采用分组设计,使得在一定时间窗内获得更多的特征信息。每50个神经元组成一组代表一类,以提高性别分类的性能。具体为将tempotron神经元分为激活或者不激活两种状态,使所有状态下的tempotron神经元都响应它们对应的目标类别,同时对不属于目标类别的神经元保持不变,最终根据投票法来对分类结果进行判定。如表1所示,使用snn模型对性别进行分类相对于使用svm准确率有了一定的提高。表1在干净环境下不同方法性别分类的准确率methodsaccuracycrbm+svm96.7%crbm+snn98.0%表2展示了不同信噪比下snn和dnn对于性别分类的不同结果。表2在不同信噪比下分类准确率methodscrbm+snncrbm+dnnclean98%99%20db98%99%10db97%93%0db83%73%average94%91%通过表2可以看出,随着噪声的增加,使用crbm+snn方法得到的性别分类的准确率要优于使用crbm+dnn,说明了使用基于crbm和snn的方法对于性别分类任务具有更好的鲁棒性。上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1