一种基于协同过滤的智慧选课推荐方法与流程
本发明涉及课程推荐方法领域,尤其涉及了一种基于协同过滤的智慧选课推荐方法。
背景技术:
智慧校园是国家教育信息化的顶层设计。随着大数据、云计算和物联网、移动互联等先进信息技术的飞速发展和进一步应用,传统校园由电子、数字化校园阶段逐步迈向智慧校园阶段。智慧校园的概念是将校园中多方面的应用,包括人、财、物等实现快速的信息交换、管理,提高校园日常教、学、研、管等业务活动的高效有序开展。智慧校园的核心是数据高度集中的大数据中心,将校园各类应用服务系统产生的业务数据高效集成和融合,采用大数据分析和挖掘方法,建立校园日常应用知识库,使得校园资源、教学、管理、科研等应用系统被高度整合,提高各应用交互的响应速度、灵活性以及准确性,使校园师生及管理人员能快速、准确地获取所需信息,从而实现智慧化服务和管理的校园新模式。
协同过滤推荐技术是个性化推荐技术中应用最为广泛的技术。协同过滤的主要思想是给兴趣爱好相似的目标群体或用户推荐用户可能产生兴趣的项目,利用集体智慧做推荐。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法和基于物品的协同过滤算法。协同过滤技术在商品、音乐、书籍推荐,互联网新闻过滤等大量商业领域有着广泛的应用。
现在,全国高校已普遍实行选课制,学生可以通过选课系统选择适合自己的学习规划和学习进程的课程。但是,目前的选课系统仍存在诸多问题:(1)学生难以获得有效的选课指导以应对种类、数量繁多的可选课程,出现盲目选课现象,导致课程资源浪费和选课质量下降。(2)选课系统只包含显示课程基本信息和选课功能,无法为学生提供个性化推荐课程以满足学生的兴趣和个性需求,不利于学生的个性化发展和全面发展。(3)传统的排课方式会使课程在上课时间或地点上出现冲突,限制了学生选课的选课,实现既定的选课计划。
技术实现要素:
本发明针对现有技术中课程资源浪费、选课质量下降的缺点,提供了一种基于协同过滤的智慧选课推荐方法。
为了解决上述技术问题,本发明通过下述技术方案得以解决。
一种基于协同过滤的智慧选课推荐方法,包括以下步骤:
步骤1,获取学生信息数据,经数据处理后得到学生特征数据集;
步骤2,根据学生特征数据集计算得到待推荐学生的相似学生集合;
步骤3,将所有课程集合中的课程划分为热门课程和冷门课程;
步骤4,通过学生对已选课程在学习结束后进行评价,得到课程评价特征数据集;
步骤5,根据步骤4中的课程评价特征数据集分别计算热门课程和冷门课程的推荐度评分,对待推荐学生进行课程推荐。
作为优选,步骤1中,学生信息数据包括往届学生信息和待推荐学生信息,往届学生信息和待推荐学生信息均包括个人基本信息和特征信息,个人基本信息包括学院、性别、专业,特征信息包括兴趣课程大类、兴趣课程小类、爱好、课程关注重点。
作为优选,课程关注重点包括课程内容丰富度、实用性、考评内容、主讲教师评价,学生根据特征信息按照个人需求对选择关注点进行排序选择。
作为优选,步骤1中,数据处理方法为根据每个特征信息进行编号,并根据编号对每个学生对应的特征信息进行录入,建立学生特征数据集。
作为优选,步骤2中,计算得到待推荐学生的相似学生集合的过程包括:
获取学生特征数据集中的特征信息,pearson系数计算待推荐学生e和往届学生,计算公式如下:
其中,sim(e,xi)表示待推荐学生e和xi的相似度,
将相似度最高的m名学生构成集合d={y1,y2,y3,...,ym},获取集合中学生的所有选课记录构成不重复的课程集合,去除其中待推荐学生不可选课程,获取可选择课程集合f={s1,s2,s3,...,su}。
作为优选,步骤3中,将所有课程集合中的课程划分为热门课程和冷门课程的过程包括:将所有课程划分为热门课程f1、冷门课程f2两个子集,两个子集中均包括累计选课人数、网上选课行为中的课程点击率、课程人数饱和度3个选课特征,根据3个选课特征对所有课程进行聚类,用k-means算法进行计算:
se表示所有数据样本的均方差之和;k为聚类的个数,ci表示第i个聚类,q为样本数据,mi为聚类ci的平均值。
作为优选,步骤4中,课程评价特征数据集包括课程内容丰富度、实用性、考评内容、主讲教师评价和课程综合评分。
作为优选,步骤5中获取推荐课程集合的方法为,采用加权平均法,对于每门课程,计算推荐度评分p:
其中,pi为课程si的推荐度评分,sij为课程si第j个特征的值,wj为特征权重,n为特征的个数;
每一项特征值的权重根据学生对于课程关注重点的排序,采用分层分析法进行设置,同时课程综合评分这一特征占最大权重,课程关注点排序确定了各特征两两之间的相对重要性,建立显示各特征重要性比例的判断矩阵g,计算判断矩阵g最大特征根λmax和其对应的经归一化后的特征向量w,则该特征向量即为描述各特征权重的权重向量;
根据具体推荐系统设定评分基准阈值,在热门课程集合f1中得到推荐度评分最高的k门课程构成集合h1,在冷门课程集合f2中得到推荐度评分最高的k门课程构成集合h2,将显示h1集合和h2集合给待选学生。
作为优选,如可推荐课程与已选课程之间存在时间、地点的冲突,或者待选学生将可推荐课程标注为不感兴趣,则按照推荐度评分排序依次替换课程,更新集合h1和h2。
本发明由于采用了以上技术方案,具有显著的技术效果:本发明通过智慧校园大数据中心建设,获取学生对于选课的兴趣、个性需求和对于课程的关注点,对学生进行个性化课程推荐,避免选课的盲目性,提高了选课质量,提高了学生的学习兴趣和积极性,有助于学生的个性化发展和全面发展,进一步的提升了选课制用以培养高素质创新人才的教育理念,同时对于智慧校园的发展有重要实践意义。
附图说明
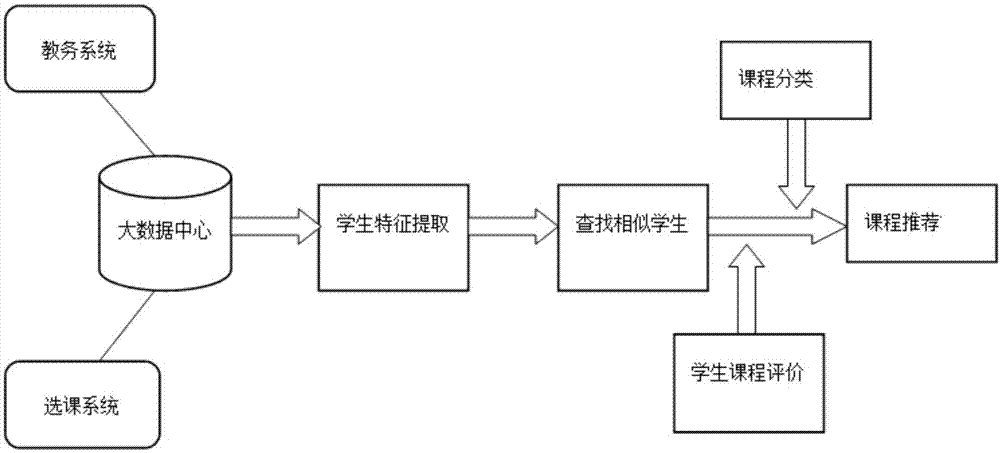
图1是本发明一种基于协同过滤的智慧选课推荐方法的运行流程示意图。
具体实施方式
下面结合附图与实施例对本发明作进一步详细描述。
如图1所示,一种基于协同过滤的智慧选课推荐方法,包括以下步骤:
步骤1,获取学生信息数据,经数据处理后得到学生特征数据集;
步骤2,根据学生特征数据集计算得到待推荐学生的相似学生集合;
步骤3,将所有课程集合中的课程划分为热门课程和冷门课程;
步骤4,通过学生对已选课程在学习结束后进行评价,得到课程评价特征数据集;
步骤5,根据步骤4中的课程评价特征数据集分别计算热门课程和冷门课程的推荐度评分,对待推荐学生进行课程推荐。
步骤1中,学生信息数据包括往届学生信息和待推荐学生信息,往届学生信息和待推荐学生信息均包括个人基本信息和特征信息,个人基本信息包括学院、性别、专业,特征信息包括兴趣课程大类、兴趣课程小类、爱好、课程关注重点。
课程关注重点包括课程内容丰富度、实用性、考评内容、主讲教师评价,学生根据特征信息按照个人需求对选择关注点进行排序选择。
步骤1中,数据处理方法为根据每个特征信息进行编号,并根据编号对每个学生对应的特征信息进行录入,建立学生特征数据集。
步骤2中,计算得到待推荐学生的相似学生集合的过程包括:
获取学生特征数据集中的特征信息,pearson系数计算待推荐学生e和往届学生,计算公式如下:
其中,sim(e,xi)表示待推荐学生e和xi的相似度,
将相似度最高的m名学生构成集合d={y1,y2,y3,...,ym},获取集合中学生的所有选课记录构成不重复的课程集合,去除其中待推荐学生不可选课程,获取可选择课程集合f={s1,s2,s3,...,su}。
步骤3中,将所有课程集合中的课程划分为热门课程和冷门课程的过程包括:将所有课程划分为热门课程f1、冷门课程f2两个子集,两个子集中均包括累计选课人数、网上选课行为中的课程点击率、课程人数饱和度3个选课特征,根据3个选课特征对所有课程进行聚类,用k-means算法进行计算:
se表示所有数据样本的均方差之和;k为聚类的个数,ci表示第i个聚类,q为样本数据,mi为聚类ci的平均值。
步骤4中,课程评价特征数据集包括课程内容丰富度、实用性、考评内容、主讲教师评价和课程综合评分。
步骤5中获取推荐课程集合的方法为,采用加权平均法,对于每门课程,计算推荐度评分p:
其中,pi为课程si的推荐度评分,sij为课程si第j个特征的值,wj为特征权重,n为特征的个数;
每一项特征值的权重根据学生对于课程关注重点的排序,采用分层分析法进行设置,同时课程综合评分这一特征占最大权重,课程关注点排序确定了各特征两两之间的相对重要性,建立显示各特征重要性比例的判断矩阵g,计算判断矩阵g最大特征根λmax和其对应的经归一化后的特征向量w,则该特征向量即为描述各特征权重的权重向量;
根据具体推荐系统设定评分基准阈值,在热门课程集合f1中得到推荐度评分最高的k门课程构成集合h1,在冷门课程集合f2中得到推荐度评分最高的k门课程构成集合h2,将显示h1集合和h2集合给待选学生。
如可推荐课程与已选课程之间存在时间、地点的冲突,或者待选学生将可推荐课程标注为不感兴趣,则按照推荐度评分排序依次替换课程,更新集合h1和h2。
本发明通过智慧校园大数据中心建设,获取学生对于选课的兴趣、个性需求和对于课程的关注点,对学生进行个性化课程推荐,避免选课的盲目性,提高了选课质量,提高了学生的学习兴趣和积极性,有助于学生的个性化发展和全面发展,进一步的提升了选课制用以培养高素质创新人才的教育理念,同时对于智慧校园的发展有重要实践意义。
实施例1
学校首先根据自己的实际情况,在数据治理之后,建立云校园大数据中心,来存储学生信息数据。
在数据中心基础之上,令学生每学期首次登录选课系统进行选课时填写信息,通过教务系统获取学生信息数据,经数据处理后提取学生特征数据集x,计算得到待推荐学生的相似学生集合d。
样本数据集由待推荐学生e=(e1,e2,...,e6,e7)和往届学生集合c={x1,x2,x3,...,xn}组成。
所选特征包括:
获取学生在教务系统中个人基本信息,提取学院、性别、专业3个特征,以及待推荐学生e和往届学生在首次登录选课系统时填写的兴趣课程大类、兴趣课程小类、爱好、课程关注重点4个特征,共计7个特征。其中课程关注重点包含课程内容丰富度、实用性、考评内容、主讲教师评价4个方面,学生需按照个人需求对选课关注点进行排序,将最为关注的那一项填入课程关注重点所在维度。
对各年级学生做课程推荐,均采用每学期首次登录选课系统进行选课时填写的信息构建特征数据集。
特征数据集x的构成如下:
其中e1、xi1为学院,e2、xi2为性别,e3、xi3为专业,e4、xi4为兴趣课程大类,e5、xi5为兴趣课程小类,e6、xi6为爱好,e7、xi7为课程关注重点。
表1学生特征数据样表
为详细说明本发明的步骤,以上述表1数据为例,以期获得1门热门课程和1门冷门课程进行推荐。
表1数据样表中将分类特征转化为数值特征,待推荐学生e和往届学生集合x1,x2,x3可构成如下特征数据集x:
利用pearson系数计算待推荐学生e和往届学生{x1,x2,x3,...,xn}的相似度:
其中sim(e,xi)表示待推荐学生e和xi的相似度,
将相似度最高的m名学生构成集合d={y1,y2,y3,...,ym}。
在上述数据样例中,计算所得sim(e,x1)=0.949,sim(e,x2)=0.355,sim(e,x3)=0.465。设k为2,即选择相似度最高的两名学生x1,x3构成集合d={x1,x3}。
步骤3,将所有课程集合中的课程划分为热门课程和冷门课程。
采用课程的近四年累计选课人数、网上选课行为中的课程点击率、课程人数饱和度3个特征,对课程集合f进行k-means聚类,划分为热门课程集合f1和冷门课程集合f2。
k-means算法需要事先输入聚类的个数k和样本总数n,在所有样本中任意随机选取k个起始聚类中心,并计算其余点到各聚类中心的距离,将其分配到与其距离最近的聚类中心所代表的类中。然后重新计算该类中每个点的均值,作为新的聚类中心。不断地迭代此过程,直到标准测度函数收敛或各聚类的中心不再随迭代改变为止。其中标准测度函数一般选取均方差函数,如公式(2)所示:
se表示所有数据样本的均方差之和。k为聚类的个数,ci表示第i个聚类,q为样本数据,mi为聚类ci的平均值。
在本例中,若相似性学生集合d有6门可推荐课程构成集合f={s1,s2,s3,s4,s5,s6},取k为2,迭代10次,得到热门课程集合f1={s1,s2,s3}和冷门课程集合f2={s4,s5,s6}。
步骤4,通过学生对已选课程在学习结束后进行评价,得到课程评价特征数据集s。
课程s的特征包括:课程内容丰富度、实用性、考评内容、主讲教师评价(对应上述学生特征中课程关注重点的4个方面)、课程综合评分,共计5个特征,体现学生对该已修课程的评价结果。由所有特征数据构成课程评价特征数据集s。
在学期结束时,令学生对自己本学期所选课程按照上述特征,评分等级设置为1-5分,每项特征评价高则对应评分高。
课程评价特征数据集s的构成如下:
其中si1为课程内容丰富度,si2为实用性,si3为考评内容,si4为主讲教师评价,si5为课程综合评分。
表2课程特征数据样表
以上述表2数据为例,则步骤3中所得热门课程集合f1={s1,s2,s3}和冷门课程集合f2={s4,s5,s6}可构成如下课程评价特征数据集s:
步骤5,根据步骤4中的课程评价特征数据集分别计算热门课程和冷门课程的推荐度评分,对待推荐学生a进行课程推荐。
采用加权平均法,对于每门课程,计算推荐度评分p:
其中pi为课程si的推荐度评分,sij为课程si第j个特征的值,wj为特征权重,n为特征的个数。
每一项特征值的权重根据步骤2中学生对于课程关注重点的排序,采用分层分析法进行设置,同时课程综合评分这一特征占最大权重。课程关注点排序确定了各特征两两之间的相对重要性,建立显示各特征重要性比例的判断矩阵g:
其中aij表示i特征和j特征之间的两两比较的定量值。
aij有如下定义:
两个特征相比较重要性相同,则aij=1;i比j稍微重要,则aij=3;i比j明显重要,则aij=5;i比j强烈重要,则aij=7;i比j极端重要,则aij=9;
计算判断矩阵g的最大特征根λmax和其对应的经归一化后的特征向量w=[w1,w2,w3,w4,w5]t,则该特征向量即为描述各特征权重的权重向量。
如待推荐学生a对课程关注重点依次顺序排序为:主讲教师评价,考评内容,实用性,课程内容丰富度。课程综合评分占最大权重,则判断矩阵g如下表示:
采用方根法计算判断矩阵g最大特征根λmax的特征向量:
对矩阵每一行求乘积得:
v5=9×7×5×3×1=945
计算vi的5次方根得:
归一化得各特征权重为:
即得到的特征向量为w=[0.033,0.064,0.13,0.264,0.51]t。
确定各特征权重后,计算热门课程集合f1和冷门课程集合f2中每门课程的推荐度评分。
f1中:
p2=0.972
p3=0.885
f2中:
p4=0.847
p5=0.66
p6=0.42
在f1和f2中均选择推荐度评分最高的1门构成集合h1={s2}和h2={s4}。
最后将可推荐课程集合h1和h2合并为集合h={s2,s4}作为最终的推荐结果。
总之,以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所作的均等变化与修饰,皆应属本发明专利的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!