基于知识的故障诊断方法与流程
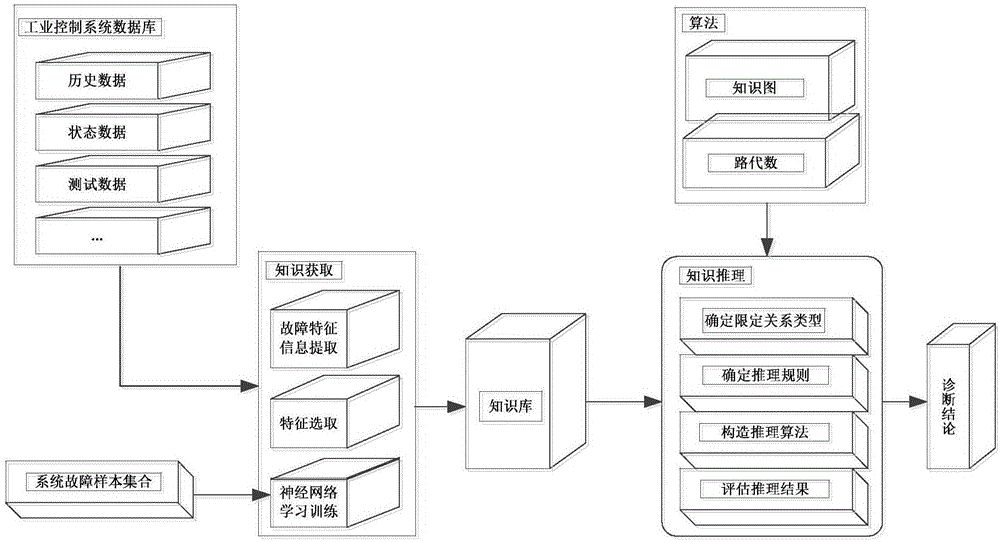
本发明涉及一种工业控制系统故障诊断方法,尤其涉及一种基于知识的故障诊断方法。
背景技术:
随着两化融合、工业4.0、中国制造2025概念的落地,传统的工厂和工业控制系统必然走向互联、融合,随之而来的是设备的维修费用越来越高,如何提高设备的可靠性,保障设备安全、稳定、长周期的运行已成为智能生产设备故障诊断领域亟待解决的问题。故障诊断技术贯穿于工业设备的设计、研制、生产制造、试验和使用维护的全寿命过程,故障诊断软件已成为工业设备设计与研制的重要手段、产品制造的质量保证工具、工业设备维修体系主要的要素,其水平已成为衡量一个国家现代工业发展能力和生产制造水平的重要标志之一。
国外方面,美国是世界上研究故障诊断技术最早的国家,1967年,机械故障预防小组(mfpg)在美国成立,开始对故障诊断技术的各个专题分别进行研究。muhammetunal等人采用遗传算法优化了神经网络的拓扑结构,以滚动轴承的故障诊断为例,验证了故障诊断方案的可行性。angeli等人提出了基于多模型结合分布式实时诊断的专家系统,以实现工业过程中的故障诊断。bagheri等人基于参数估计的方法,根据系统模型中的各参数变化的统计学特征来对系统进行故障诊断。
国内方面,我国的故障诊断技术发展较晚,大致开始于上世纪80年代初期,至今也取得了不少突出的成果。潘翀,陈伟根等人将遗传算法与小波神经网络相结合,利用遗传算法优化神经网络的结构和权值,使得网络的训练过程加快,令网络获得了较好的泛华能力,并将该算法应用于变压器的故障诊断中,验证了其可行性。张华强、赵剡等人利用高斯函数替换神经网络的激励函数,提出了一种基于自适应概率神经网络的故障诊断方案,该方案使网络具有较好的泛化能力。此外,徐敏等主编了专著《设备故障诊断手册》,黄文虎等主编了《设备故障诊断原理、技术及应用》,提出了用模糊诊断模型,可信度因子模型,产生式规则等建立故障诊断专家系统的方法。
现代的大多数故障诊断与预测系统虽然能以很快的速度对被测对象自动地进行故障诊断,但是随着设备智能化、网络化以及复杂程度的提高,现有系统容易造成故障诊断的模糊性和不确定性,且对故障知识获取的自动性较差。因此,需要基于历史案例及领域专家知识,充分利用数据分析及人工智能技术,有效解决故障知识获取及故障定位需求,提高故障诊断的效率和可靠性,从而有力保障工业控制系统稳定运行。
技术实现要素:
本发明的目的在于提供一种基于知识的故障诊断方法,通过充分考虑工业控制系统的故障特点,完成故障特征信息的提取,利用神经网络算法实现故障知识的获取,然后利用知识推理完成故障精确定位。
实现本发明目的的技术解决方案为:一种基于知识的故障诊断方法,包括以下步骤:
第一步,典型故障数据库建立:针对工业控制系统,建立典型故障案例数据库;
第二步,故障特征信息提取:基于建立的典型故障数据库,利用信号处理技术,提取得到时域特征参数、时-频域特征参数;
第三步,特征选取:根据特征参数组成的数据集,采取主要成分分析方法,将数据集的主要数据属性变量提取出来;
第四步,神经网络算法训练学习:利用神经网络算法,对系统故障样本集合进行学习训练,完成故障知识的获取;
第五步,面向系统故障诊断的知识表示:针对获取的故障知识,采用框架与产生式规则相结合的方式,用故障树框架法来表示具体的故障模块,用产生式规则来表示故障的前提和结果,得到故障诊断知识的规则表示;
第六步,系统故障传播模型构建:首先,构建系统任务到完成任务的能力映射关系模型;然后,构建能力到系统组成模块的映射关系模型;最后,构建基于模块依存关系的故障传播模型;
第七步,基于知识推理的故障定位:分析系统故障知识中的元素及关系类型,确定限定关系类型,确定推理规则,构建知识图,引入路代数对推理关系进行表述和运算,对推理结果可信度进行计算,给出可信度依据,实现系统故障的定位。
本发明与现有技术相比,其显著优点为:(1)基于改进的bp神经网络算法实现故障诊断知识的获取,克服了其它算法“组合爆炸”、“无穷递推”等问题,也克服了传统神经网络算法“局部最优”、“收敛速度下降”等缺陷;(2)采用框架与产生式规则相结合的方法来表示诊断知识,用故障树框架法来表示具体的故障模块,用产生式规则来表示故障的前提和结果,简化复杂知识表示步骤,明确关联故障关系,提高知识表示效率;(3)构建系统故障传播模型,得到故障征兆与故障原因的映射关系,通过测试设备的状态参数、采集和分析故障征兆数据,就能在故障发生前,对可能发生故障的原因和部位进行预测;(4)采用知识图的方法对知识进行描述并引用路代数的理论实现推理,在融合故障案例、专家诊断经验和故障传播模型三种知识的基础上,允许推理出基础知识库中没有提到的新关系,从而有效改善工业控制系统故障定位的局限性。
附图说明
图1是本发明故障诊断流程图。
图2主要成分分析方法图。
图3神经网络训练学习流程图。
图4框架与产生式规则相结合的诊断知识表示图。
图5基于依存关系的故障传播模型示意图。
图6基于知识推理的故障定位技术方案示意图。
具体实施方式
如图1所示,本发明的一种基于知识的故障诊断方法,包括以下步骤:
第一步,典型故障数据库建立:针对工业控制系统,根据相关资料、历史案例数据及专家经验,建立典型故障案例数据库,包括故障现象及故障原因。
第二步,故障特征信息提取:基于建立的典型故障数据库,利用信号处理技术,提取得到时域、时-频域特征参数数据。
第三步,特征选取:根据第二步特征参数组成的数据集,采取主要成分分析方法,将数据集的主要数据属性变量提取出来。
第四步,神经网络算法训练学习:利用神经网络算法,对系统故障样本集合进行学习训练,完成故障知识的获取。
第五步,面向系统故障诊断的知识表示:针对获取的故障知识,采用框架与产生式规则相结合的方式,用故障树框架法来表示具体的故障模块,用产生式规则来表示故障的前提和结果,得到故障诊断知识的规则表示。
第六步,系统故障传播模型构建:首先,构建系统任务到完成任务的能力映射关系模型;然后,构建能力到系统组成模块的映射关系模型;最后,构建基于模块依存关系的故障传播模型。
第七步,基于知识推理的故障定位:分析系统故障知识中的元素及关系类型,确定限定关系类型,确定推理规则,构建知识图,引入路代数对推理关系进行表述和运算,最后对推理结果可信度进行计算,给出可信度依据。
进一步的,时域特征参数包括均方根、歪度因子、峭度因子、波峰因子、裕度因子、波形因子和脉冲因子,时-频域特征参数为信号经过经验模态分解得出的本征模函数值。
时-频域特征参数提取方法为:
确定原始信号所处时间内数据集x(t)局部极大值与极小值;
根据极大值与极小值作三次样条插值以确定x(t)在上下包络线之间;
根据上下包络线求出x(t)的局部均值mn(t),除去该包络线所代表的低频成分hn(t)=x(t)-mn(t);
以hn(t)作为原始信号重复上述步骤,直到满足imf的2个标准,记作c1(t)作为第一个imf;
用原始信号减去c1(t)作为新信号r(t)=x(t)-c1(t),重复之前的所有步骤直到所有的imf找出即:
其中,imf的2个标准:
(1)整个信号中过零点的数目与极值数相同或最多相差为1。
(2)在任何时间点上,由极大值包络线和极小值包络线所定义的均值包络线必须为0。
进一步的,第三步特征选取的过程为:
①计算数据矩阵x各列的平均值,数据矩阵x中的每个数值减去该数所在列的列平均值;
②计算该数据矩阵x的特征协方差矩阵c,采用公式:c=x*x′;
③对上一步得到的协方差矩阵c进行奇异值分解,公式如下:c=u*d0*u′,其中u为酉矩阵,d0为特征值对角矩阵;
④计算白化矩阵m,采用公式:
⑤计算该数据矩阵z的特征协方差矩阵c,并求出特征协方差的特征值d与特征向量v;
⑥将特征值的对角矩阵d转换为列向量dn,并将其进行降序排列;
⑦计算列向量特征值总和,并计算累加每次列向量总和与列向量特征值总和的比值,进而与设置的信息贡献度比较大小;若第k次累加列向量总和与列向量特征值总和大于设置信息贡献度h,则将其所对应的k个特征向量作为新的特征向量;反之,继续增加累加次数,直到累加列向量总和与列向量特征值总和的比值大于设置信息贡献度h;
⑧最后,将输入数据矩阵z投影到新的特征向量上,产生降低维数后的新数据矩阵xnew。
进一步的,第四步神经网络算法训练学习的过程为:
通过对输入和输出模型的计算,得到神经元输出;
从输出层开始向下计算,修改各层连接的权值,直至得到期望误差精度和分类可信度。
进一步的,第六步具体为:
步骤6-1,构建系统任务到完成任务的能力映射关系模型;依据工业控制系统各种任务的各项活动提出完成任务的能力需求,构建系统任务到能力映射关系模型,提取能力特性和要素,建立能力数据库;
步骤6-2,构建能力到系统组成模块的映射关系模型;
(1)按照最小可更换单元的粒度将工业控制系统划分为若干个模块,建立系统的体系结构模型;
将系统划分为若干个模块之后,各个模块之间形成逻辑连接,这种模块以及模块之间的连接关系,形成工业控制系统的体系结构;
(2)依据能力到模块功能的映射关系,建立工业控制系统体系结构的依存模型;
对于工业控制系统体系结构中的模块,以节点来表示,模块之间的逻辑连接以子任务或状态的变迁来表示,并通过状态变迁来描述系统中组成模块之间的依存关系;
步骤6-3,构建基于模块依存关系的故障传播模型;
确定依存模型的节点中包含的影响因子;
确定各影响因子的故障模式以及各故障模式对系统运行状态的影响;
构建基于系统依存关系的故障传播模型。
下面结合附图和实施例对本发明作进一步详细描述。
实施例
结合图1,本发明一种基于知识的故障诊断方法包含下列步骤:
第一步,典型故障数据库建立:针对工业控制系统,分析相关资料、历史案例数据、维护数据及专家经验,建立典型故障案例数据库,包括故障现象及故障原因。
第二步,故障特征信息提取:数据集合经过信号处理后的特征提取得到时域,时-频域特征参数数据。其中时域特征参数包括:均方根、歪度因子、峭度因子、波峰因子、裕度因子、波形因子、脉冲因子。时-频域特征参数为:信号经过经验模态分解得出的imf(本征模函数值)。
时域特征参数提取原理如下:
均方根误差:
歪度因子:
峭度因子:
波峰因子:
裕度因子:
波形因子:
脉冲因子:
其中,n为信号观测次数,σ为标准差。
时-频域特征参数提取原理如下:
经验模态分解:
首先,确定原始信号所处时间内数据集x(t)局部极大值与极小值;然后,根据极大值与极小值作三次样条插值以确定x(t)在上下包络线之间;下一步,根据上下包络线求出x(t)的局部均值mn(t),除去该包络线所代表的低频成分hn(t)=x(t)-mn(t);下一步,以hn(t)作为原始信号重复之前三步,直到满足imf的2个标准,记作c1(t)作为第一个imf;下一步,用原始信号减去c1(t)作为新信号r(t)=x(t)-c1(t),重复之前的所有步骤直到所有的imf找出即:
imf的2个标准:
第三步,特征选取:根据第二步特征参数组成的数据集,采取主要成分分析方法,将数据集的主要数据属性变量提取出来。主要成分分析方法如图2所示,计算过程为:
①计算数据x各列的平均值,矩阵x中的每个数值减去该数所在列的列平均值。
②计算计算该数据矩阵x的特征协方差矩阵c,采用公式:c=x*x′。
③对上一步得到的协方差矩阵c进行奇异值分解,公式如下:c=u*d0*u′,其中u为酉矩阵,d0为特征值对角矩阵。
④计算白化矩阵m,采用公式:
⑤计算该数据矩阵z的特征协方差矩阵c,并求出特征协方差的特征值d与特征向量v。
⑥将特征值的对角矩阵d转换为列向量dn,并将其进行降序排列。
⑦计算列向量特征值总和,并计算累加每次列向量总和与列向量特征值总和的比值,进而与设置的信息贡献度比较大小。若第k次累加列向量总和与列向量特征值总和大于设置信息贡献度h,则将其所对应的k个特征向量作为新的特征向量。反之,继续增加累加次数,直到累加列向量总和与列向量特征值总和的比值大于设置信息贡献度h。
⑧最后,将输入数据矩阵z投影到新的特征向量上,产生降低维数后的新数据矩阵xnew。
第四步,神经网络算法训练学习:该算法步骤主要分为两个阶段,计算实际输出和修改权值和阈值。计算实际输出是通过对输入和输出模型的计算,而得到神经元输出;修改权值和阈值,是从输出层开始向下计算,修改各层连接的权值,直至得到期望误差精度和分类可信度。学习训练流程如图3所示。算法改进方式为:
①训练过程改进
在一般算法中,学习率η是由搜索求得的。在标准的bp算法中常被定义为常数,然而在实践中一个一成不变的最佳学习率是不存在的。学习率对bp神经网络的学习或收敛速度影响很大。学习率η取值越大,权值的变化范围就越大,当训练过程中bp网络的权值分布w趋于稳定的时候,学习率η的过大会导致权值分布w产生振荡过程,系统不能收敛。
当学习率η过小,权值的修改量将会减小,迭代过程减慢将会导致收敛过程变慢,根据学习率与训练迭代次数存在的一定数学关系,假设据学习率与训练迭代次数存在线性函数关系。在训练过程中,假设最大迭代次数为tmax,初始学习率为η(1),第tmax次迭代后学习率为η(tmax),每一次迭代完成后,可以得到学习率的表达式为
根据收敛过程中收敛特征,设计合适的学习率函数可以加快学习率,也不会引发学习过程中振荡。改变学习率是可以有效的改进迭代次数,是改进bp学习算法的主要方法和提高训练收敛速度的重要手段。
②加入动量项
bp神经网络的反向传播阶段加入附加动量项,对本次学习的理论权值调整量与之前的调整量相加,作为下一次学习过程的权值调整量。如下式:
其中,n为训练次数,mc为动量系数,当mc取值为0时,权重按照梯度下降调整。当mc取值为1时,新的权重调整量与之前权值变化量大小相同,梯度下降调整量可以忽略不计。加入动量项之后,误差曲面底部对应的网络权值较小,
③引入陡度因子
因为神经元输出进入传输函数的饱和区,所以在误差二维平面上存在平坦区。如果出现这种情况,需要压缩神经元净输入,使其跳出传输函数的饱和区。具体思路是,在原传输函数中引入一个陡度因子λ,使输出为
其中dk为输出期望值,netk为神经网络传递函数参数值,当e接近于零时,dk-yk仍较大,说明系统处于平坦区。当取λ>1,netk坐标压缩了λ倍,从而可以使绝对值较大的net退出饱和值。当取λ=1时,传输函数恢复原状,对于较小的net来说具有较高灵敏度。引入陡度因子对于提高bp算法的收敛速度非常有效。
第五步,面向系统故障诊断的知识表示:考虑工业控制系统组成和结构复杂,故障之间彼此关联,知识量大等特点,采用框架与产生式规则相结合的方法来表示诊断知识,用故障树框架法来表示具体的故障模块,用产生式规则来表示故障的前提和结果,简化复杂知识表示步骤,明确关联故障关系,提高知识表示效率。具体流程如图4所示。首先根据故障的描述进入工业控制故障诊断系统,按照系统的匹配规则和相关的推理机制,将输入的数据与系统数据库的诊断知识进行匹配和对比,进而判断出具体故障的属性,在此过程中如果有相关的子框架,按照规则启动需要的子框架进一步进行诊断推理,最后把故障定位在最基本的元器件单元。
第六步,系统故障传播模型构建:首先,构建系统任务到完成任务的能力映射关系模型。通过对工业控制系统的任务进行分析,依据各种任务的各项活动提出完成任务的能力需求,构建系统任务到能力映射关系模型,提取能力特性和要素,建立能力数据库。
然后,构建能力到系统组成模块的映射关系模型。
步骤一:按照最小可更换单元的粒度将工业控制系统划分为若干个模块,建立系统的体系结构模型。
将系统划分为若干个模块之后,各个模块之间在系统中以一定的形式形成逻辑连接,这种模块以及模块之间的连接关系,就形成了工业控制系统的体系结构。
步骤二:依据能力到模块功能的映射关系,建立工业控制系统体系结构的依存模型。
对于工业控制系统体系结构中的模块,以节点来表示,模块之间的逻辑连接以子任务或状态的变迁来表示,并通过状态变迁来描述系统中组成模块之间的依存关系。
最后,构建基于模块依存关系的故障传播模型。
步骤一:根据工业控制系统健康影响因素分析,确定依存模型的节点中包含的影响因子;
步骤二:分析各影响因子的故障模式以及各故障模式对系统运行状态的影响;
步骤三:构建基于系统依存关系的故障传播模型如图5所示。
第七步,基于知识推理的故障定位:核心思想是在知识图中引入路代数的概念,将知识推理的过程转化成路代数的运算过程,主要过程如图6所示。
步骤7-1:分析归纳工业控制系统故障诊断知识中包含的元素和关系类型,确定限定关系类型,并对关系进行形式化表示;
步骤7-2:根据工业控制系统故障诊断知识的描述逻辑,确定推理规则;
常用于专家系统的限定关系类型包括:
①acaub:a的发生或变化引起b的发生或变化;
②aparb:a是b的一部分
③aakob:a是b的一种
④上述三个关系的逆关系:ahapb、ahakb、acbyb
基本的推理有以下两种情况:一是如果在点a和b之间存在关系,同时在点b和c之间存在关系,则有理由认为在点a和c之间也存在关系,由这些串行组合所得到的关系类型成为串行推理;二是如果在点a和b之间存在两种以上关系,确定这种并行组合所得到的关系类型称为并行推理。
步骤7-3:对已有知识进行元素分解,构建知识图,引入路代数对推理关系进行表述和运算;
在知识图k(c,r)中,令π=(c0,c1,...,ck)是一条长度为k的路,其中,ci∈c,ri=(ci,ci+1)∈r。一条路实际上是一个关系序列,每个关系或者是弧(ci,ci+1),或者是边(ci,ci+1)。如果假定对所有长度为2的子路允许作乘法运算,则r=(c0,ck)关于路π的类型(type)可以定义为
令
步骤7-4:对推理结果可信度进行计算,给出可信度依据。
引入权值的概念用以表示推理的可信度,给每个关系附加一个式样的权值ω(0≤ω≤1)来表示该关系成立的可能性,并且在推理时应用平方和开方与归一化处理来表示推理后得到的关系的可能性。
①并行推理
如果ar1b(ω1),ar1b(ω2),那么a与b之间仍然存在关系r1,但是a和b之间的权值
这个推理规则说明,并行推理会提高推理关系的可信度。
②串行推理
如果ar1b(ω1),br2c(ω2),则a与c之间存在的关系
ω=ω1*ω2
上述推理规则说明,串行推理会降低推理关系的可信度。
利用上述推理规则,我们既得到了推理的关系,也同时得到了推理结果可信度。
- 还没有人留言评论。精彩留言会获得点赞!