一种基于机器学习的侵权网页判断方法与流程
本发明涉及互联网应用领域,尤其涉及一种基于机器学习的侵权网页判断方法。
背景技术:
网页侵权是网络侵权的一种类型,也是现代社会知识侵权的一种形式,网页侵权的本质与知识侵权是相同的,即行为人由于过错侵害他人的财产和人身权利。目前的互联网上存在大量网页,其中有一部分包括了盗版付费资源下载、盗版付费资源宣传等侵权网页,以此向用户收费或者吸引广告主的资金投入,以此达到赢利为目的。当然,侵权人是否以赢利为目的并不影响侵权的构成。目前对于这部分侵权网页的判定主要以人工审核的方式进行,人工进行侵权网页的审核与判定存在有以下缺点:1、人力成本高:包括人工雇佣成本、培训成本等;2、侵权网页判定准确率控制困难:通过人工进行审核主要通过个人经验进行判定,对部分隐藏较深的网页难以进行判断;3、时效性差:人工审核的速度较为缓慢,在人工审核过程之中侵权网页已经对版权方造成利益损失难以挽回。
技术实现要素:
为解决现有采用人工审核网页是否侵权成本高昂、没有统一审核标准导致审核缓慢的技术问题,本发明设计了一种基于机器学习的侵权网页判断方法。
本发明采用如下技术方案:
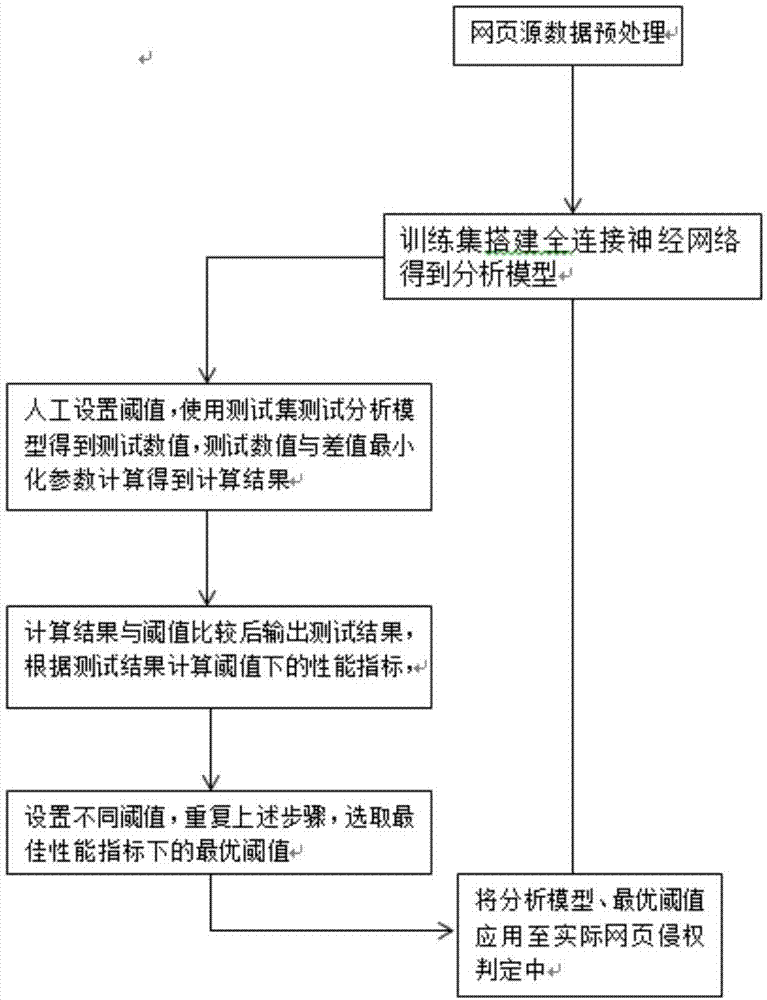
一种基于机器学习的侵权网页判断方法,包括:网页源数据预处理生成训练集和测试集;使用训练集生成分析模型、测试集测试不同阈值下分析模型的性能指标及人工选择最优阈值;使用分析模型和最优阈值对网页进行分析判断是否为侵权网页,所述网页源数据包括网页标题、网页文本和网页侵权标签,所述网页源数据生成训练数据和测试数据,所述训练数据构建形成词典,所述词典使用词袋模型将训练数据生成训练集,所述训练集包括训练特征向量和数据标签,所述词典使用词袋模型将测试数据生成测试集,所述测试集包括测试特征向量和数据标签,所述数据标签使用“0”或“1”分别表示“非侵权”和“侵权”,所述分析模型通过所述训练集搭建全连接神经网络得到,所述分析模型包括输入层、隐藏层a、隐藏层b和输出层,所述输入层内设置存储单元,所述隐藏层a、隐藏层b和输出层内均设置计算单元,所述存储单元存储输入数据,所述计算单元表示一次数学计算,所述输入层的存储单元数为5000,所述隐藏层a的计算单元数为1000,所述隐藏层b的计算单元数为300,所述输出层的计算单元数为1,所述隐藏层a设置有激活函数leakrelu,所述隐藏层b设置有激活函数tanh,所述输出层设置有激活函数sigmoid。
作为优选,所述网页源数据生成训练数据和测试数据步骤如下:(1)随机打乱网页源数据;(2)取打乱后网页源数据的80%生成训练数据,取打乱后网页源数据的20%生成测试数据。
作为优选,所述训练数据构建形成词典步骤如下:(1)所述训练数据进行中文分词处理;(2)取词语长度≥2、频率最高的5000个词语构建形成词典。
作为优选,所述分析模型输入训练集得出差值最小化参数,其步骤如下:(1)所述分析模型中输入所述训练特征向量,所述训练特征向量顺序通过输入层存储单元、隐藏层a计算单元、激活函数leakrelu、隐藏层b计算单元、激活函数tanh、输出层计算单元、激活函数sigmoid输出0-1之间的计算数值;(2)通过比较计算数值与数据标签的差值,反向调节所述计算单元的参数,得出基于训练集的差值最小化参数。
作为优选,所述测试集测试分析模型、人工选择阈值的步骤如下:(1)人工设置阈值;(2)将测试特征向量输入所述分析模型中得到测试数值,测试数值与所述差值最小化参数进行差值计算得到计算结果;(3)在所述阈值下,计算结果与所述阈值比较后输出测试结果;(4)根据测试结果计算阈值下的性能指标,根据性能指标人工选择最优阈值。
作为优选,所述测试结果为:计算结果大于阈值输出为侵权,计算结果小于等于阈值输出为非侵权。
作为优选,所述性能指标包括准确率、查准率和召回率,所述性能指标的计算方法为:准确率=(正确判断为侵权数+正确判断为非侵权数)/测试样本数;查准率=正确判断为侵权数/(正确判断为侵权数+错误判断为侵权数);召回率=正确判断为侵权数/侵权样本数。
作为优选,所述使用分析模型和阈值对网页进行分析判断是否为侵权网页的步骤如下:(1)网页数据根据词典生成使用词袋模型表示的特征向量;(2)所述特征向量输入分析模型中判断网页是否侵权;(3)在最优阈值下,计算结果大于最优阈值则判定为网页侵权,计算结果小于等于最优阈值则判定为非侵权。
本发明的有益效果是:本发明建立了网页侵权的分析模型并设置最优阈值,将网络上的网页数据生成特征向量输入分析模型中进行计算,所得的计算结果与最优阈值进行比较,计算结果大于最优阈值判定为网页侵权,计算结果小于等于最优阈值则判定为非侵权即可。通过本发明可以将大量的网页采用分析模型进行侵权判断,从而降低了人工成本,并且通过建立分析模型、设置最优阈值的方式统一了侵权网页的审核标准极快地提升了审核的速度,保证了在短时间内审核完毕大量网页从而保障了版权方的利益。
附图说明
图1是本发明网页源数据预处理的流程图;
图2是本发明测试集测试分析模型、人工选择最优阈值的流程图;
图3是本发明实际应用中网页侵权判定的流程图;
图4是本发明分析模型的结构图;
图1-4中:1、网页源数据,101、网页标题,102、网页文本,103、网页侵权标签,2、分析模型,201、输入层,202、隐藏层1,203、隐藏层2,204、输出层。
具体实施方式
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体描述:
实施例:结合附图1-4所示,一种基于机器学习的侵权网页判断方法,包括:
网页源数据1预处理生成训练集和测试集;
使用训练集生成分析模型2、测试集测试不同阈值下分析模型的性能指标及人工选择最优阈值;
使用分析模型2和最优阈值对网页进行分析判断是否为侵权网页。
所述网页源数据包括网页标题101、网页文本102和网页侵权标签103,网页源数据1中包含有许多网页样本,网页侵权标签103为“0”或“1”代表着一个网页样本是“非侵权”或“侵权”,网页源数据1生成训练数据和测试数据,所述训练数据构建形成词典,所述词典使用词袋模型将训练数据生成训练集,所述训练集内包括训练特征向量和数据标签,所述词典使用词袋模型将测试数据生成测试集,所述测试集内包括测试特征向量和数据标签,所述数据标签使用“0”或“1”分别表示“非侵权”和“侵权”,训练集和测试集内的网页源数据1内的网页样本均包含特征向量和数据标签,每个数据标签的值为“0”或“1”代表着样本是“非侵权”或“侵权”。
所述分析模型2通过所述训练集搭建全连接神经网络得到,所述分析模型2通过所述训练集搭建全连接神经网络得到,所述分析模型2包括输入层201、隐藏层a202、隐藏层b203和输出层204,所述输入层201内设置存储单元,所述隐藏层a202、隐藏层b203和输出层204内均设置计算单元,所述存储单元存储输入数据,所述计算单元表示一次数学计算,所述输入层201的存储单元数为5000,所述隐藏层a202的计算单元数为1000,所述隐藏层b203的计算单元数为300,所述输出层204的计算单元数为1,所述隐藏层a202设置有激活函数leakrelu,所述隐藏层b203设置有激活函数tanh,所述输出层204设置有激活函数sigmoid,存储单元用于保存原始数据的输入,计算单元用于对输入数据做线性变化的基础运算得到线性函数,激活函数用于将线性函数生成非线性映射,即通过隐藏层a、隐藏层b和输出层内的激活函数得到表示输入与输出之间非线性的复杂的任意函数映射,从而使得分析模型2对复杂的网页数据进行分析和计算。
所述网页源数据1生成训练数据和测试数据步骤如下:(1)随机打乱网页源数据1;(2)取打乱后网页源数据1的80%生成训练数据,取打乱后网页源数据1的20%生成测试数据。
所述训练数据构建形成词典步骤如下:(1)所述训练数据进行中文分词处理;(2)取词语长度≥2、频率最高的5000个词语构建形成词典。
所述分析模型2输入训练集得出差值最小化参数,其步骤如下:(1)所述分析模型2中输入所述训练特征向量,所述训练特征向量顺序通过输入层201计算单元、隐藏层a202计算单元、激活函数leakrelu、隐藏层b203计算单元、激活函数tanh、输出层204计算单元、激活函数sigmoid输出0-1之间的计算数值;(2)通过比较计算数值与训练数据标签的差值,反向调节所述计算单元的参数,得出基于训练集的差值最小化参数。
所述测试集测试分析模型2、人工选择阈值的步骤如下:(1)人工设置阈值;(2)测试特征向量输入所述分析模型2中得到测试数值,测试数值与所述差值最小化参数进行差值计算得到计算结果;(3)在所述阈值下,计算结果与所述阈值比较后输出测试结果;(4)根据测试结果计算阈值下的性能指标,根据性能指标人工选择最优阈值。
所述测试结果为:计算结果大于阈值输出为侵权,计算结果小于等于阈值输出为非侵权。测试特征向量输入分析模型2,得出测试结果,每个测试结果表示每个测试网页样本是侵权网页的可能性,输出测试结果为0.1表示侵权可能性是10%,选定不同的阈值,将测试结果区分为侵权和非侵权,假设阈值设定为0.2,则测试结果0.1被分类为非侵权,0.3被分类为侵权,将分类之后的结果与样本的数据标签一一比较,得出每个样本的测试结论:
(1)分类为侵权,数据标签为侵权:正确判断为侵权;
(2)分类为侵权,数据标签为非侵权:错误判断为侵权;
(3)分类为非侵权,数据标签为侵权:错误判断为非侵权;
(4)分类为非侵权,数据标签为非侵权:正确判断为非侵权。
所述性能指标包括准确率、查准率和召回率,所述性能指标的计算方法为:准确率=(正确判断为侵权数+正确判断为非侵权数)/测试样本数;查准率=正确判断为侵权数/(正确判断为侵权数+错误判断为侵权数);召回率=正确判断为侵权数/侵权样本数,将召回率保持99%以上,通过输入不同数值的阈值重复测算不同阈值下测试样本的性能指标,比较此性能指标取准确率、查准率均为最大值时的阈值即为最优阈值。
所述使用分析模型2和阈值对网页进行分析判断是否为侵权网页的步骤如下:(1)网页数据根据词典生成使用词袋模型表示的特征向量;(2)所述特征向量输入分析模型2中判断网页是否侵权;(3)在最优阈值下,计算结果大于最优阈值则判定为网页侵权,计算结果小于等于最优阈值则判定为非侵权,通过分析模型2将网页数据生成的特征向量输入其中进行计算,所得的计算结果与差值最小化参数进行差值计算得到计算结果,计算结果与最优阈值进行比较判定是否为侵权。
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
- 还没有人留言评论。精彩留言会获得点赞!