翻译语句结束判断方法与系统与流程
本申请属于机器学习领域,尤其涉及一种翻译语句结束判断方法与系统。
背景技术:
在翻译过程中,通常需要对一个较长的待译文本进行切分。切分的一个必要条件是切分后的各个子部分都应该是一个完整独立的语料,不能将一个句子的上下半句切分到不同子部分中;此外,翻译过程通常需要机器翻译的辅助,翻译人员通常需要将待译文本上传至机器翻译工具中,虽然现有的机器翻译引擎支持整段的上传翻译,但是这种方式翻译结果较差,因此,翻译人员通常是需要一句一句的将单个的完整句子上传,才能得到相对比较完成的结果;在另一种场景中,还需要校对翻译后的结果是否正确,此时也需要以完整的句子为单位上传文本进行检查。在这个过程中,面临的一个重要问题就是:如何切分得到完整的句子。
一个简单的判断方式是,以句子结束符号为判断依据,例如,通常认为如果某段连续的文本以句号、问号、感叹号结束,则认为该句子结束,可以认为该连续文本构成了一个完整的句子;基于这种思路,可以采用检测特定的符号的方式实现句子结束检测从而完成句子切分。当然,这种方式能够实现预定效果的前提是要处理的文本在形成时便严格遵守标点符号使用规则。
显然,当前的语言环境中,很少有人严格按照规定使用标点符号,大部分人除了段落末尾以及文章末尾之外,其他部分从来不使用句号,一个逗号到底或者直接不停的采用分号;更别说乱用问号、感叹号的现象在各种特殊文体中习以为常(例如咆哮体)。因此,仅仅采用前述的判断方式已经不能准确识别出文本中的具有完整意义的句子。
技术实现要素:
为解决上述问题,特别是翻译过程中需要准确切分出完整意义上的句子的问题,本申请提出了一种翻译语句结束判断方法与系统,能够从待处理的文本中准确识别出一段连续文本是否结束构成了一个句子,从而完成句子结束判断。
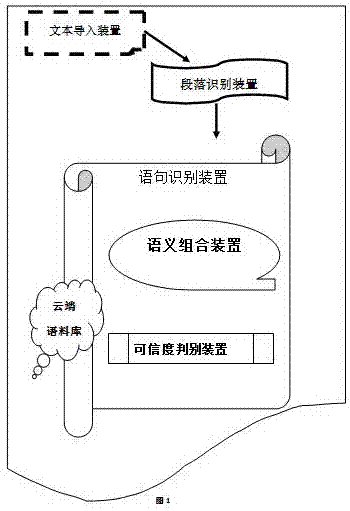
在本发明的第一个方面,提供一种翻译语句结束判断系统,该系统包括文本导入装置、段落识别装置、语句识别装置、语义组合装置以及可信度判别装置;
具体实现时,将待处理文本通过所述文本导入装置导入到所述系统;然后运行所述段落识别装置;
所述段落识别装置对导入的待处理文本进行初步处理,得到以段落为单位的段落子部分集合,例如识别出段落开头与结尾,还可以识别出待处理文本的全文结尾;然后,所述段落子部分集合逐段进入语句识别装置;
所述语句识别装置按照以段落为单位,对所述段落子部分集合进行处理,具体处理步骤包括:
(1)从当前段落的第一个未读字符开始连续读取剩余字符,直到读取到停顿符号为止;读取的连续字符构成待处理句;
(2)从所述待处理句中提取多个句子主干词;所述句子主干词是指具备动作意义的实词;
(3)将所述多个句子主干词输入所述语义组合装置,所述语义组合装置基于云端语料库输出至少一个比较句;
(4)将所述待处理句、所述至少一个比较输入所述可信度判别装置;
(5)所述可信度判别装置输出判别结果。
检测到停顿符号,意味着已经读取的连续字符有可能构成了一个完整的句子,意义独立,因此,视为潜在的候选句子;但是,潜在的候选句子还需要进一步判断才能确定是否确实为一个意义完整的独立句子;将这些潜在的候选句子作为待处理句,进入下一步处理;
下一步处理待处理句,则是本申请的技术方案的核心所在。处理构思为:
从所述待处理句中提取多个句子主干词;
将所述多个句子主干词输入所述语义组合装置,所述语义组合装置基于云端语料库输出至少一个比较句。
基于大规模的语料库的自动学习,本申请能够实现文本的自动学习与语句撰写。当然,基于云端语料库在从所述待处理句中提取多个句子主干词的基础上生成的比较句,本身是一个完整意义的独立句子。
接下来,将当前待处理句和这个生成的比较句进行比较,从而就能够判断当前待处理句是不是独立的句子,这一过程是通过本申请所述的可信度判别装置实现的。
具体包括:
将所述待处理句、所述至少一个比较输入所述可信度判别装置;
所述可信度判别装置输出判别结果。
具体判断标准可以是如下之一或者其组合,
◆比较当前待处理句和这个生成的比较句的长度,判断长度差是否在第一阈值范围内;
◆将当前待处理句和这个生成的比较句进行相似度比较,判断相似度是否在第二阈值范围之内;
其中,获取长度差的方法比较简单,易于实现;相似度比较的方法则可以采用现有技术已有的文本相似度比较方法,本发明不再赘述。
如果长度差满足第一阈值范围条件,和/或,相似度满足第二阈值范围条件,则可信度判别装置判定当前待处理句为一个完整的句子;
此时,待处理文本的当前待处理句已经处理并且识别完成,可以用于实际的操作(切分或者上传等);然后,本发明的技术方案继续读取字符,重复上述步骤(1-5),即读取下一个待处理句,判定是否构成完整句子;
如果长度差不满足第一阈值范围条件,和/或,相似度不满足第二阈值范围条件,则当前待处理句不是一个完整句子,此时,则表示当前待处理句后续还有更多的属于该句子的字符,因此,本发明的技术方案进一步包括:继续连续读取当前停顿符号之后的未读字符,直到读取到下一个停顿符号为止;读取的连续字符加入到当前待处理句中;
这样,当前待处理句的字符数量增加,可以获得更多的句子主干词,接下来重复前述步骤(2-5),即可实现待处理句是否为完整句子的判断。
可见,本发明的技术方案可以采用计算机流程化的指令语言实现,具体识别与判断为一个迭代循环的过程,其中包括单个待处理句子的内部小循环,其终止条件为当前待处理句子已经构成一个完整的句子,然后进入下一个待处理句子的识别判断;以段落为单位输入待处理文本时,则本次处理的终止条件为读取到段落结尾标记;待处理文本全文输入时,本次处理的终止条件为读取到全文结尾标记。
因此,在本发明的第二个方面,提供一种计算机实现的识别方法,用于识别当前待处理文本中意义完整独立的句子,所述方法包括如下步骤:
s1:读取当前待处理文本的当前未处理段落;
s2:从当前未处理段落的第一个未读字符开始连续读取字符;
s3:判断当前读取的字符是否为停顿符;如果是,则进入步骤s4;否则,重复步骤s2;
s4:基于读取的字符形成的当前待处理句,提取多个句子主干词;
s5:根据所述多个句子主干词,输出至少一个比较句;
s6:基于所述至少一个比较句与当前待处理句的比较,判断当前待处理句是否构成完整句;
s7:判断当前停顿符是否为全文结尾标记符,如果是,则结束处理;否则,进入步骤s8;
s8:判断当前停顿符是否为段落结尾标记符,如果是,则进入步骤s1;否则,进入s2。
其中,步骤s5具体包括:将所述多个句子主干词输入基于云端语料库的机器学习引擎,输出至少一个比较句;
其中,步骤s6包括:比较当前待处理句和至少一个比较句的长度,判断长度差是否在第三阈值范围内;和/或,将当前待处理句和至少一个比较句进行相似度比较,判断相似度是否在四阈值范围之内;
进一步的,如果所述长度差和/或相似度在相应的阈值范围之内,则判断当前待处理句构成完整句;
进一步的,所述阈值范围可以调节。可以设置一个阈值范围调节模块,用于调节所述第一至第四阈值范围的大小。
本发明的第三个方面,提供了一种计算机可读存储介质,其上存储有计算机可执行指令,通过计算机存储器和处理器,执行所述可执行指令,用于实现本发明前述的一种计算机实现的识别方法,用于识别当前待处理文本中意义完整独立的句子。
本发明的技术方案至少达到了如下突出的效果:
◆从语义上而不是以标点符号为判断标准,识别出待处理文本中具备完整意义的句子;
◆判断标准基于大规模语义学习,并且结合了机器学习的先进技术;
◆虽然基于语义机器人自动文章生成技术属于现有技术,但是本发明首次将其应用于翻译语料识别;并且,本发明的目的和现有技术不同,不是为了生成文本而生成文本,而是用作判断标准;
◆现有技术都是基于现有关键词生成整篇的文章,其要求输出的整篇文章唯一并且尽可能准确无误,而本发明关注的是基于现有的少量关键词输出结果的多样性,这样更准确的用于判断。
本发明进一步的具体实现和优点将在具体实施例部分具体说明。
附图说明
图1是本发明的翻译语句结束判断系统的框架图
图2是本发明所述方法计算机实现流程图
具体实施例
参见图1,本发明的一种翻译语句结束判断系统,该系统包括文本导入装置、段落识别装置、语句识别装置、语义组合装置以及可信度判别装置。
本实施例中,将待处理文本通过所述文本导入装置导入到所述系统;然后运行所述段落识别装置;
所述段落识别装置对导入的待处理文本进行初步处理,得到以段落为单位的段落子部分集合,例如识别出段落开头与结尾,还可以识别出待处理文本的全文结尾;然后,所述段落子部分集合逐段进入语句识别装置;
所述语句识别装置按照以段落为单位,对所述段落子部分集合进行处理,具体处理步骤包括:
(1)从当前段落的第一个未读字符开始连续读取剩余字符,直到读取到停顿符号为止;读取的连续字符构成待处理句;
(2)从所述待处理句中提取多个句子主干词;所述句子主干词是指具备动作意义的实词;
(3)将所述多个句子主干词输入所述语义组合装置,所述语义组合装置基于云端语料库输出至少一个比较句;
(4)将所述待处理句、所述至少一个比较输入所述可信度判别装置;
(5)所述可信度判别装置输出判别结果。
其中,当前段落的第一个未读字符可以是单个的字、词以及可以用在段落或者句子开头的标点符号,例如左单引号“、左双引号“等;
正常来说,如果待处理文本严格按照标点符号使用方法使用标点符号,则只需要读取到句号、问号、感叹号为止就可以构成完整句子,但是如前所述,现有技术的待处理文本并不是严格按照这个标准执行。因此,为解决这个问题,本申请抛弃了现有技术的符号判断问题,而从当前段落的第一个未读字符开始读取,直到读取到停顿符号为止,读取的连续字符构成待处理句。
这里的停顿符号,是指读取到可以表示句子停顿的标点符号,包括句号、问号、感叹号、顿号、逗号、引号(右单引号、左单引号)、分号等可以使得句子暂时停顿的符号,可以理解,破折号、书名号、括号等不会引起句子停顿不视为停顿符号;冒号虽然可以停顿,但是通常情况下冒号之后的部分还是视为前一个句子的连续;因此,冒号也不视为停顿符号;此外,本申请的技术方案包括段落识别装置,因此,停顿符号还包括段落识别装置识别出的段落结尾标记符号以及全文结尾标记符号。
上述实例仅仅是罗列而不是穷举,本领域技术人员在具体实现时,可以预先建立一个停顿符号集合,用于后续的查询判断。
检测到停顿符号,意味着已经读取的连续字符有可能构成了一个完整的句子,意义独立,因此,视为潜在的候选句子;但是,潜在的候选句子还需要进一步判断才能确定是否确实为一个意义完整的独立句子;将这些潜在的候选句子作为待处理句,进入下一步处理;
下一步处理待处理句,则是本申请的技术方案的核心所在。处理构思为:
从所述待处理句中提取多个句子主干词;
将所述多个句子主干词输入所述语义组合装置,所述语义组合装置基于云端语料库输出至少一个比较句。
具体来说,待处理句是由多个词构成,这些词有些是实词,有些是虚词。所谓实词,是指具备实际意义的词,例如“今天”、“下班”、“预估”、“submit”、“line”等;所谓虚词,则通常表示连接关系、修饰等,单个的词不能体现实际意义,例如“的”、“那么”、“与”、“所述”、“the”、“should”、“does”、“such”等;在自然语言处理中,存在相关现有技术用于切分出实词或者虚词,切分或者识别的标准可能存在不同,但是具体含义均是一致的,本申请在此不再赘述。
基于切分实词或者虚词的现有技术,本申请从所述待处理句中提取多个句子主干词,这里的句子主干词可以是当前待处理句子中的实词;
接下来,将所述多个句子主干词输入所述语义组合装置,所述语义组合装置基于云端语料库输出至少一个比较句。
基于大规模的语料库的自动学习,本申请能够实现文本的自动学习与语句撰写。当然,现有技术也存在类似的机器学习技术,例如近年来已经实现的机器人新闻撰写人、自动文章撰写机器人等,这些机器人可以通过用户输入的几个主干词(关键词、提示词)等,自动生成一篇新闻稿或者文章,效果已经完全接近专业新闻撰稿人的水平,甚至读者都无法分辨文章是由机器人完成的。
本发明人发现,这类机器学习工具都是基于大规模语料库的自动学习完成的,因此,本申请也可以提供一个基于云端的语料库用于机器学习从而建立机器学习引擎,例如本发明的语义组合装置。再将前述提取的多个句子主干词输入所述语义组合装置。这样,所述语义组合装置基于云端语料库输出至少一个比较句,类似于前述的机器人新闻撰写人、自动文章撰写机器人完成工作。
当然,本发明不需要输出整段的新闻稿或者整篇的文章,只需要输出一个完整的句子即可,因此,本发明的机器学习引擎可以更为简单快速,其输出结果可以是多个意义完整并且完全独立的句子,而不是仅一个结果,相对于现有的机器人新闻撰写人、自动文章撰写机器人的效果更佳;这是因为发明人创造性的将其用于翻译特殊的需要的体现。
基于大规模的语料库在从所述待处理句中提取多个句子主干词的基础上生成的比较句,本身必然是一个完整意义的独立句子。
接下来,将当前待处理句和这个生成的比较句进行比较,从而就能够判断当前待处理句是不是独立的句子,这一过程是通过本申请所述的可信度判别装置实现的。
具体包括:
将所述待处理句、所述至少一个比较输入所述可信度判别装置;
所述可信度判别装置输出判别结果。
具体判断标准可以是如下之一或者其组合,
◆比较当前待处理句和这个生成的比较句的长度,判断长度差是否在第一阈值范围内;
◆将当前待处理句和这个生成的比较句进行相似度比较,判断相似度是否在第二阈值范围之内;
其中,获取长度差的方法比较简单,易于实现;相似度比较的方法则可以采用现有技术已有的文本相似度比较方法,本发明不再赘述。
如果长度差满足第一阈值范围条件,和/或,相似度满足第二阈值范围条件,则可信度判别装置判定当前待处理句为一个完整的句子;
此时,待处理文本的当前待处理句已经处理并且识别完成,可以用于实际的操作(切分或者上传等);然后,本发明的技术方案继续读取字符,重复上述步骤(1-5),即读取下一个待处理句,判定是否构成完整句子;
如果长度差不满足第一阈值范围条件,和/或,相似度不满足第二阈值范围条件,则当前待处理句不是一个完整句子,此时,则表示当前待处理句后续还有更多的属于该句子的字符,因此,本发明的技术方案进一步包括:继续连续读取当前停顿符号之后的未读字符,直到读取到下一个停顿符号为止;读取的连续字符加入到当前待处理句中;
这样,当前待处理句的字符数量增加,可以获得更多的句子主干词,接下来重复前述步骤(2-5),即可实现待处理句是否为完整句子的判断。
参见图2,提供一种计算机实现的识别方法,在本实施中,该方法具体实现包括图2的步骤s1-s8。
具体而言,每个步骤执行的功能如下:
s1:读取当前待处理文本的当前未处理段落;
s2:从当前未处理段落的第一个未读字符开始连续读取字符;
s3:判断当前读取的字符是否为停顿符;如果是,则进入步骤s4;否则,重复步骤s2;
s4:基于读取的字符形成的当前待处理句,提取多个句子主干词;
s5:根据所述多个句子主干词,输出至少一个比较句;
s6:基于所述至少一个比较句与当前待处理句的比较,识别当前待处理句是否为完整句;
s7:判断当前停顿符是否为全文结尾标记符,如果是,则结束处理;否则,进入步骤s8;
s8:判断当前停顿符是否为段落结尾标记符,如果是,则进入步骤s1;否则,进入s2。
- 还没有人留言评论。精彩留言会获得点赞!