一种基于专家领域相似度与关联关系的协同推荐方法与流程
本发明涉协同推荐技术领域,特别是一种基于专家领域相似度与关联关系的协同推荐方法。
背景技术:
竞争与合作是二十一世纪的主题,科研领域中存在着许多跨领域的合作,合作往往以论文的形式体现。专家在寻找合作的过程中往往希望找到特定领域,且与自己关系密切的专家学者进行合作,这样既可以达到合作的目的,也更加的便捷。如何快速的找到与自身存在潜在合作价值的期望领域的专家,是进行良好合作的基础。因此,专家推荐得到了各领域专家的广泛关注。
目前关于专家推荐的研究主要分为两类,一类是基于内容的推荐,该方法主要借助向量空间模型、语言模型和主题模型等自然语言处理技术计算专家研究主题与当前需求的匹配度。另一类是基于链接关系的推荐方法,此方法主要利用学术网络的连接结构来推断专家的学术影响力。传统专家推荐方法虽然结合了研究内容相关性与专家影响力这两个方面,却没有考虑到专家之间存在的潜在的关联关系,因此难以快速、全面、准确地推荐与该专家紧密关联的指定领域专家。
技术实现要素:
本发明的目的在于提供一种基于专家领域相似度与关联关系的协同推荐方法,能够依据用户给定领域关键词与专家姓名,推荐与该专家关联度最紧密的指定领域专家。
实现本发明目的的技术解决方案为:一种基于专家领域相似度与关联关系的协同推荐方法,包括以下步骤:
步骤1,将批量论文数据作为训练集进行输入;
步骤2,对论文数据进行预处理,包括提取专家合作信息、专家论文关键词、专家论文摘要;对同一篇论文下的合作者建立专家合作信息;
步骤3,将目标专家姓名、目标领域作为输入,获取领域词向量;
步骤4,利用专家合作信息构造合作关系网络,利用dijkstra算法计算作者之间的最短路径,作为专家关联度cor;
步骤5,利用word2vec训练专家论文中的关键词和摘要,构建专家关键词向量模型;
步骤6,计算关联专家词向量与领域词向量的余弦相似度,作为专家领域相似度sim;
步骤7,筛选专家领域相似度sim与专家关联度cor,满足阈值的专家即为推荐专家。
进一步地,步骤4所述的利用专家合作信息构造合作关系网络,利用dijkstra算法计算作者之间的最短路径,作为专家关联度cor,具体如下:
步骤4.1、根据论文作者列表信息,以作者作为节点,将共同撰写论文的作者用边连接起来,共同撰写论文数的倒数作为边的权重,构造专家合作信息无向加权图g=(v,e);
步骤4.2、利用dijkstra算法计算作者之间的最短路径,作为专家关联度cor,具体步骤如下:
步骤4.2.1、输入专家合作信息无向加权图g=(v,e),输入目标专家姓名作为源点v0;
步骤4.2.2、用邻接矩阵arcs表示无向加权图,arcs[m][n]表示边<vm,vn>的权值,若不存在边<vm,vn>,则arcs[m][n]=∞,其中m,n∈{m|vm∈v};
步骤4.2.3、设置集合s记录已求得最短路径的顶点,令集合s初始为{v0};
步骤4.2.4、设置数组dist[]记录从源点v0到其他各个顶点vi的当前最短路径长度,dist[i]初始值为arcs[0][i],其中i∈{i|vi∈v};
步骤4.2.5、从顶点集合v-s中选出vj,满足dist[j]=min{dist[i]|vi∈v-s},vj就是当前求得的一条从v0出发的最短路径的终点;令集合s=s∪{vj};
步骤4.2.6、修改从源点v0到集合v-s中各个顶点vk的最短路径长度:如果dist[j]+arcs[j][k]<dist[k],则令dist[k]=dist[j]+arcs[j][k];
步骤4.2.7、重复步骤4.2.5和步骤4.2.6至集合v-s为空集;
步骤4.2.8、输出数组dist[],其中专家vi与目标专家v0的关联度cor(i)=dist[i]。
进一步地,步骤6所述的计算关联专家词向量与领域词向量的余弦相似度,作为专家领域相似度sim,具体如下:
步骤6.1、输入由步骤5生成的专家关键词向量模型;
步骤6.2、输入专家关键词集x={x1,x2,...,xm},以及关键词权重集w={w1,w2,...,wm};
步骤6.3、利用专家关键词向量模型计算专家关键词向量集合
步骤6.4、计算专家向量
步骤6.5、输入目标领域关键词,计算目标领域词向量
步骤6.6、计算领域相似度
进一步地,步骤7所述的筛选专家领域相似度sim与专家关联度cor,满足阈值的专家即为推荐专家,具体如下:
依据用户给定的专家关联度阈值c与领域相似度阈值s,输出满足sim>s且cor<c的专家信息。
本发明与现有技术相比,其显著优点在于:(1)能够依据用户给定领域关键词与专家姓名,推荐与该专家关联度最紧密的指定领域专家;(2)考虑到专家之间存在的潜在的关联关系,从而快速、全面、准确地找到与自身存在潜在合作价值的期望领域的专家。
附图说明
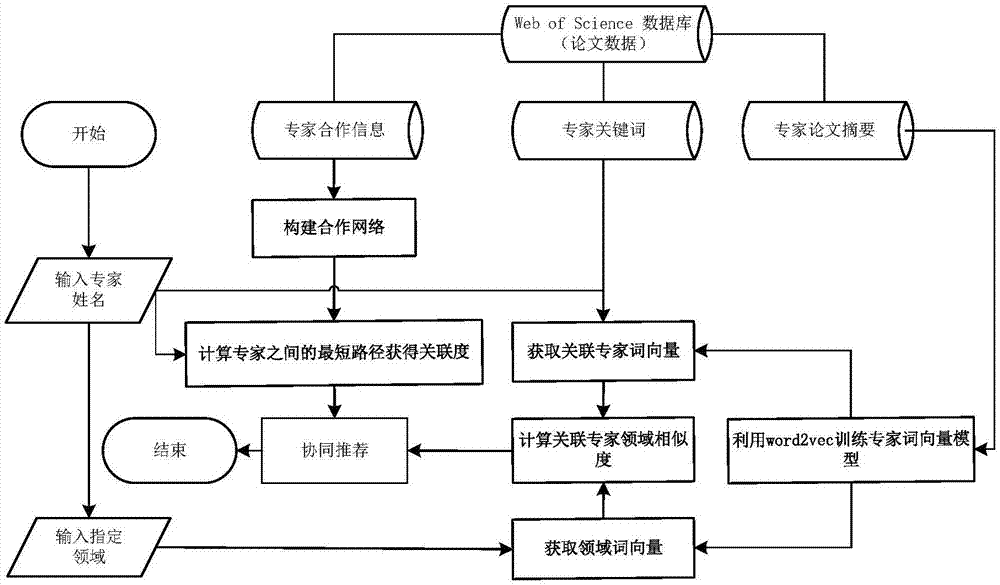
图1是本发明基于专家领域相似度与关联关系的协同推荐方法的流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的说明。
结合图1,本发明基于专家领域相似度与关联关系的协同推荐方法,包括以下步骤:
步骤1,将批量论文数据作为训练集进行输入;
步骤2,对论文数据进行预处理,包括提取专家合作信息、专家论文关键词、专家论文摘要;对同一篇论文下的合作者建立专家合作信息;
步骤3,将目标专家姓名、目标领域作为输入,获取领域词向量;
步骤4,利用专家合作信息构造合作关系网络,利用diikstra算法计算作者之间的最短路径,作为专家关联度cor,具体如下:
步骤4.1、根据论文作者列表信息,以作者作为节点,将共同撰写论文的作者用边连接起来,共同撰写论文数的倒数作为边的权重,构造专家合作信息无向加权图g=(v,e);
步骤4.2、利用diikstra算法计算作者之间的最短路径,作为专家关联度cor,具体步骤如下:
步骤4.2.1、输入专家合作信息无向加权图g=(v,e),输入目标专家姓名作为源点v0;
步骤4.2.2、用邻接矩阵arcs表示无向加权图,arcs[m][n]表示边<vm,vn>的权值,若不存在边<vm,vn>,则arcs[m][n]=∞。其中m,n∈{m|vm∈v};
步骤4.2.3、设置集合s记录已求得最短路径的顶点,令集合s初始为{v0};
步骤4.2.4、设置数组dist[]记录从源点v0到其他各个顶点vi的当前最短路径长度,dist[i]初始值为arcs[0][i],其中i∈{i|vi∈v};
步骤4.2.5、从顶点集合v-s中选出vj,满足dist[j]=min{dist[i]|vi∈v-s},vj就是当前求得的一条从v0出发的最短路径的终点。令集合s=s∪{vj};
步骤4.2.6、修改从源点v0到集合v-s中各个顶点vk的最短路径长度:如果dist[j]+arcs[j][k]<dist[k],则令dist[k]=dist[j]+arcs[j][k];
步骤4.2.7、重复步骤4.2.5和步骤4.2.6至集合v-s为空集;
步骤4.2.8、输出数组dist[],其中专家vi与目标专家v0的关联度cor(i)=dist[i]。
步骤5,利用word2vec训练专家论文中的关键词和摘要,构建专家关键词向量模型;
步骤6,计算关联专家词向量与领域词向量的余弦相似度,作为专家领域相似度sim,具体如下:
步骤6.1、输入由步骤5生成的专家关键词向量模型;
步骤6.2、输入专家关键词集x={x1,x2,...,xm},以及关键词权重集w={w1,w2,...,wm};
步骤6.3、利用专家关键词向量模型计算专家关键词向量集合
步骤6.4、计算专家向量
步骤6.5、输入目标领域关键词,计算目标领域词向量
步骤6.6、计算领域相似度
步骤7,筛选专家领域相似度sim与专家关联度cor,满足阈值的专家即为推荐专家,具体如下:
依据用户给定的专家关联度阈值c与领域相似度阈值s,输出满足sim>s且cor<c的专家信息。
综上所述,本发明能够依据用户给定领域关键词与专家姓名,推荐与该专家关联度最紧密的指定领域专家,从而快速、全面、准确地找到与自身存在潜在合作价值的期望领域的专家。
- 还没有人留言评论。精彩留言会获得点赞!