一种基于三角架构的蒙汉神经机器翻译方法与流程
本发明属于机器翻译技术领域,特别涉及一种基于三角架构的蒙汉神经机器翻译方法。
背景技术:
机器翻译能够利用计算机将一种语言自动翻译成为另外一种语言,是解决语言障碍问题的最有力手段之一。近年来,许多大型搜索企业和服务中心例如谷歌、百度等针对机器翻译都进行了大规模的研究,为获取机器翻译的高质量译文做出了重要贡献,因此大语种之间的翻译已经接近人类翻译水平,数百万人使用在线翻译系统和移动应用实现了跨越语言障碍的交流。在近几年深度学习的浪潮中,机器翻译已成为重中之重,已经成为促进全球交流的重要组成部分。
作为一种数据驱动方法,神经机器翻译的性能高度依赖平行语料库的规模、质量和领域覆盖面。然而,除了中文、英文等资源丰富的语言,世界上绝大多数语言都缺乏大规模、高质量、广覆盖率的平行语料库,蒙古语就是一个典型的代表。因此,如何充分利用现有数据来缓解资源匮乏问题,成为神经机器翻译的一个重要研究方向。
目前,端到端神经机器翻译获得了迅速发展,相对于传统的机器翻译方法在翻译质量上获得显著提升,已经成为商用在线机器翻译系统的核心技术。但是对于平行语料库匮乏的低资源语言的翻译相比大语种之间的翻译仍然存在不小的劣势。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于三角架构的蒙汉神经机器翻译方法,该方法主要针对小语种中平行语料库有限的问题特别是蒙汉平行语料库稀缺问题,将蒙古语(z)作为中间隐变量,引入到英语(x)和汉语(y)之间的翻译中,将英汉之间的翻译分解为经由蒙古语的两个步骤。
为了实现上述目的,本发明采用的技术方案是:
一种基于三角架构的蒙汉神经机器翻译方法,其特征在于,将蒙古语作为中间隐变量,引入到大语种x(如英语、法语、日语等)和汉语之间的翻译中,将大语种x和汉语之间的翻译分解为经由蒙古语的两个步骤,在最大化翻译大语种x和汉语的可能性的目标下,用统一的双向em算法联合优化蒙古语的翻译模型,提升蒙汉翻译质量,其中任意两个组合之间的翻译仍然使用端到端的编码器-解码器结构。
以z表示蒙古语,以y表示汉语,所述统一的双向em算法过程如下:
x→y方向
e:优化θz|x
其中:θz|x表示从大语种x翻译到蒙古语z时使翻译准确率达到设定值之上时的参数值,p(z|x)表示从大语种x翻译到蒙古语z的准确率,是真实分布,p(z|y)表示从汉语y翻译到蒙古语z的准确率,是p(z|x)的拟合分布,kl(.)是kullbackleibler散度;kl(p(z|x)||p(z|y))表示当用p(z|y)来拟合真实分布p(z|x)时,产生的信息损耗;
m:优化θy|z
其中:θy|z表示从蒙古语z翻译到汉语y时使翻译准确率达到设定值之上时的参数值,ez~p(z|x)表示从大语种x翻译到蒙古语z时z的数学期望,p(y|z)表示从蒙古语z翻译到汉语y的准确率,d表示整个训练集;
y→x方向
e:优化θz|y
其中:θz|y表示从汉语y翻译到蒙古语z时使翻译准确率达到设定值之上时的参数值;
m:优化θx|z
其中:θx|z表示从蒙古语z翻译到大语种x时使翻译准确率达到设定值之上时的参数值,ez~p(z|y)表示从汉语y翻译到蒙古语z时z的数学期望,p(x|z)表示从蒙古语z翻译到大语种x的准确率。
p(z|x)和p(y|z)在p(z|y)的帮助下联合训练,p(z|y)和p(x|z)在p(z|x)的帮助下联合训练。
p(z|x)、p(z|y)、p(y|z)和p(x|z)均由其本身产生的样本来训练。
所述x→y方向翻译的训练分解为两个阶段,训练两个翻译模型,第一种模型x→z从大语种x的输入句子生成蒙古语z的潜在翻译,第二种模型z→y根据该潜在翻译生成汉语y的最终翻译,遵循标准em算法的步骤和延森不等式,整个训练数据d上的p(y|x)的下界如下:
其中:l(q)为l(θ;d)的下界,l(θ;d)为似然函数,θ是p(z|x)和p(y|z)的模型参数集中使翻译准确率达到设定值之上时的参数值,p(y|x)表示从大语种x翻译到汉语y的准确率,q(z)是z的任意后验分布,q(z)=p(z|x)。
用ibm模型对生成的译文进行加权考核,根据给定的双语数据计算翻译概率,所述双语数据指低资源对(x;z)或(y;z)。
将由模型p(z|x)或p(z|y)生成的伪样本与真正的双语样本以1:1的比例混合在同一小批量中,以稳定训练过程。
本发明整个训练过程算法如下所示:
输入:丰富的资源双语数据(x;y),低资源双语数据(x;z)和(y;z)
输出:参数θz|x,θy|z,θz|y和θx|z
1:预训练p(z|x),p(z|y),p(x|z),p(y|z)
2:while不收敛do
3:大语种x和汉语y之间的平行语料(x,y)∈d,大语种x和蒙古语z之间的平行语料(x*,z*)∈d,汉语y和蒙古语z之间的平行语料(y*,z*)∈d
4:x→y方向:优化θz|x,θy|z
5:从p(z′|x)生成z′并且建立训练批b1=(x,z′)∪(x*,z*),b1表示样本(x;z)添加了训练出来的伪平行语料库后的(x;z)平行语料,z′表示新生成的蒙古语z的语料,b2=(y,z′)∪(y*,z*),b2表示样本(y;z)添加了训练出来的伪平行语料库后的(y;z)平行语料
6:e步:用b1更新θz|x
7:m步:用b2更新θy|z
8:y→x方向:优化θz|y,θx|z
9:从p(z′|y)生成z′并且建立训练批b3=(y,z′)∪(y*,z*),b4=(x,z′)∪(x*,z*)
10:e步:用b3更新θz|y
11:m步:用b4更新θx|z
12:endwhile
13:返回:θz|x,θy|z,θz|y,θx|z
与现有的端到端神经机器翻译方法相比,本发明充分考虑了小语种中平行语料库有限的问题特别是蒙汉平行语料库稀缺问题,在平行语料库匮乏的前提下提高蒙汉翻译的质量;其次,利用统一的双向em算法联合优化蒙古语的翻译模型;最后,由模型x→z或z→y生成的伪样本与真正的双语样本以1:1的比例混合在同一小批量中来稳定训练过程。
附图说明
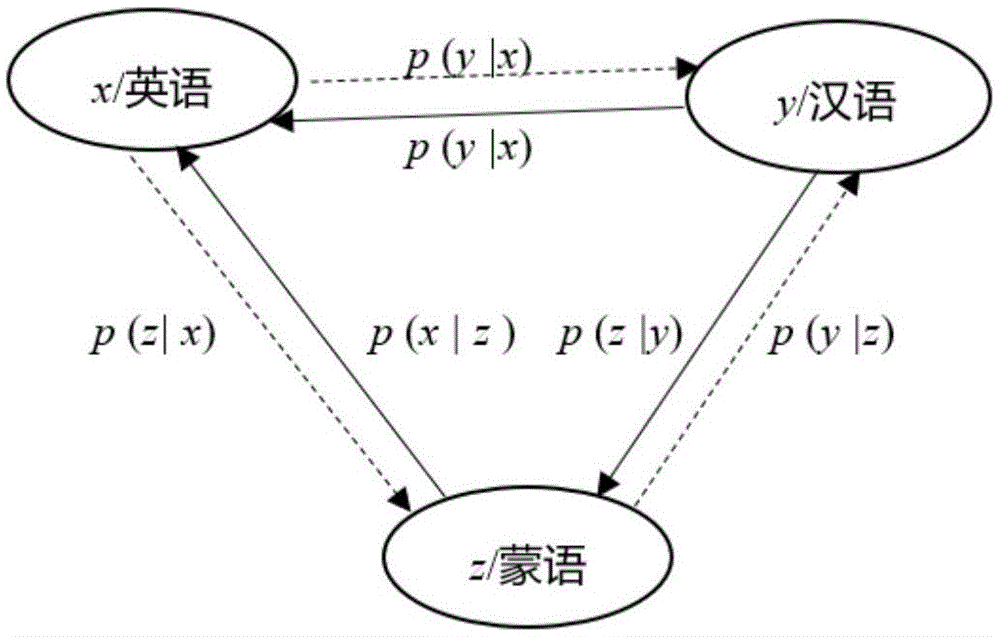
图1为低资源nmt的三角学习架构图。
图2为端到端编码器-解码器结构。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
问题描述:基于三角架构的蒙汉神经机器翻译方法,用统一的双向em算法联合优化蒙古语的翻译模型。
以z表示蒙古语,以y表示汉语,以x表示英语,统一的双向广义em过程如下:
x→y的翻译的训练分解为两个阶段来训练两个翻译模型,第一种模型x→z从x的输入句子生成z的潜在翻译,第二种模型z→y根据该潜在翻译生成y语言的最终翻译,这两个过程均使用端到端的编码器-解码器结构;另外,遵循标准em算法的步骤和延森不等式,得到整个训练数据d上的p(y|x)的下界如下:
其中:l(q)为l(θ;d)的下界,l(θ;d)为似然函数,θ是p(z|x)和p(y|z)的模型参数集中使翻译准确率达到设定值之上时的参数值,p(z|x)表示从语言x翻译到语言z的准确率,p(y|z)表示从语言z翻译到语言y的准确率,p(y|x)表示从语言x翻译到语言y的准确率,d表示整个训练集,q(z)是z的任意后验分布,q(z)=p(z|x)。
x→y方向
e:优化.θz|x
为了使l(q)和l(θ;d)之间误差达到最小,使用下面公式:
其中:θz|x表示从大语种x翻译到蒙古语z时使翻译准确率达到设定值之上时的参数值,p(z|x)表示从大语种x翻译到蒙古语z的准确率,是真实分布,p(z|y)表示从汉语y翻译到蒙古语z的准确率,是p(z|x)的拟合分布,kl(.)是kullbackleibler散度;kl(p(z|x)||p(z|y))表示当用p(z|y)来拟合真实分布p(z|x)时,产生的信息损耗;
m:优化θy|z
其中:θy|z表示从语言z翻译到语言y时使翻译准确率达到设定值之上时的参数值,ez~p(z|x)表示从x翻译到z时z的数学期望;
y→x方向
e:优化θz|y
其中:θz|y表示从语言y翻译到语言z时使翻译准确率达到设定值之上时的参数值,p(z|y)表示从语言y翻译到语言z的准确率;
m:优化θx|z
其中:θx|z表示从语言z翻译到语言x时使翻译准确率达到设定值之上时的参数值,ez~p(z|y)表示从y翻译到z时z的数学期望,p(x|z)表示从语言z翻译到语言x的准确率,p(x|y)表示从语言y翻译到语言x的准确率;
在上述推导的基础上,对整个体系结构进行分析,如图1所示:虚线箭头表示p(y|x)的方向,其中p(z|x)和p(y|z)在p(z|y)的帮助下联合训练,而实线箭头表示p(x|y)的方向,其中p(z|y)和p(x|z)在p(z|x)的帮助下联合训练。类似于强化学习,模型p(z|x)、p(z|y)、p(y|z)和p(x|z)均由其本身产生的样本来训练。
上述双向的训练过程中,e步均执行梯度下降训练,x→y方向上的梯度下降计算公式如下:
训练过程算法如下:
输入:丰富的资源双语数据(x;y),低资源双语数据(x;z)和(y;z)
输出:参数θz|x,θy|z,θz|y和θx|z
1:预训练p(z|x),p(z|y),p(x|z),p(y|z)
2:while不收敛do
3:语言x和语言y之间的平行语料(x,y)∈d,语言x和语言z之间的平行语料(x*,z*)∈d,语言y和语言z之间的平行语料(y*,z*)∈d
4:x→y方向:优化θz|x,θy|z
5:从p(z′|x)生成z′并且建立训练批b1=(x,z′)∪(x*,z*),b1表示样本(x;z)添加了训练出来的伪平行语料库后的(x;z)平行语料,z′表示新生成的语言z的语料,b2=(y,z′)∪(y*,z*),b2表示样本(y;z)添加了训练出来的伪平行语料库后的(y;z)平行语料,z′表示新生成的语言z的语料
6:e步:用b1更新θz|x
7:m步:用b2更新θy|z
8:y→x方向:优化θz|y,θx|z
9:从p(z′|y)生成z′并且建立训练批b3=(y,z′)∪(y*,z*),b4=(x,z′)∪(x*,z*)
10:e步:用b3更新θz|y
11:m步:用b4更新θx|z
12:endwhile
13:返回:θz|x,θy|z,θz|y,θx|z
训练过程稳定性的保证:
为了保证训练过程的稳定性,将由模型x→z或z→y生成的伪样本与真正的双语样本以1:1的比例混合在同一小批量中。
以下是英蒙、蒙英、蒙汉、汉蒙任意两种语言之间利用端到端的编码器-解码器结构翻译的过程:
参照图2,首先,图2的上半部分,编码器对源语言句子进行编码,生成上下文语义向量组,然后,这些上下文语义向量作为用户意图的编码。生成的过程中(图2的下部),解码器结合注意力机制生成目标语言中的每一个字,在生成每一个字的同时,考虑输入该句所对应的上下文语义向量,使得该句生成的内容与原语言的意思相符合。
具体的翻译步骤如下:
1.编码器读取输入的源语言句子;
2.编码器采用循环神经网络将读到的句子编码为隐层状态,形成一个上下文语义向量组;
3.解码器结合注意力机制依次生成目标语言的每个字。
- 还没有人留言评论。精彩留言会获得点赞!