一种基于深度目标检测的待采摘水果识别和定位方法与流程
本发明涉及一种待采摘水果识别和定位方法,尤其涉及一种一种基于深度目标检测的待采摘水果识别和定位方法。
背景技术:
水果采摘作业所处自然环境的复杂性导致水果采摘仍然依靠人力,水果采摘环节所需的劳动力占整个生产过程投入劳动力的一半以上。随着我国农业从业人口的不断下降和人工成本的不断上升,水果自动化采摘对于解决水果产业中劳动力不足,保证水果适时采摘,提高采摘品质等方面具有重要的意义。因此,研究水果的自动采摘技术迫在眉睫。
在水果的自然生长环境下快速而可靠的发现水果目标并确定待采摘水果的位置是实现自动采摘的关键技术。近年来,很多水果检测识别和定位算法相继提出。有基于超红图像和2r-g-b色差增强苹果特征,利用自适应阈值分割方法从图像中提取苹果区域;有研究了基于区域生长和颜色特征分割的方法,通过支持向量机识别提取的苹果颜色和形状特征,但是对于叶面遮挡引起的平均误差率较大;有应用残差变换绝对值和块匹配方法检测潜在的柑橘果实像素,构建一个支持向量机实现了较高的识别精确率,但是对于遮挡以及光照不均匀水果的识别表现不佳。
在水果的自然生长环境下,果树的枝叶与果实、果实与果实之间存在复杂的相互位置关系,导致果实被枝叶或其他果实随机遮挡。现有算法的思路主要是针对待采摘水果的纹理、颜色和形态等人工设计并抽取特征,当在自然条件下遮挡情况和光照条件随场景变化而变化,与之对应的待采摘水果的特征也随之变化,因此基于人工特征设计的水果特征提取算法鲁棒性有待提高;自然生产条件下,获取的水果图像通常都存在遮挡或者光照不均匀等复杂背景,上述的水果识别和定位算法对于自然生长条件下的水果识别率和定位精度有待提高。
发明的内容
针对以上问题,本发明提供了一种可实现复杂环境下水果特征自动提取、复杂自然环境下的水果自动识别、复杂自然环境下的水果自动定位的基于深度目标检测的待采摘水果识别和定位方法。
为了解决以上问题,本发明采用了如下技术方案:一种基于深度目标检测的待采摘水果识别和定位方法,其特征在于,包括以下步骤:
步骤1图像采集
本图像采集基于普通的rgb图像实现,图像采集目标是实际自然生长环境下的待采摘水果;图像通过普通的单反相机获取,成像时模拟人工采摘的视角,保持相机的高度和水果目标基本持平,水果目标保持在图像中心位置;
步骤2图像标注
对步骤1中采集的原始数据进行人工标注;人工的将图像中的待采摘水果通过最小外接矩形标出,记录框处目标水果的类别(如苹果),记录最小外接矩形在图片中左上角和右上角的顶点坐标;数据记录标注的格式与目前广泛使用的imagenet图像数据集的标注格式相同;
步骤3数据集准备
将步骤1的原始图像和步骤2对应的标记数据共同作为一条可训练数据,将所有的可训练数据组成原始的数据集;将原始数据按照5:3:2的比例,人为随机的切分为3个子集,分别作为后续的检测模型的训练集、验证集和测试集;训练集、验证集和测试集基于原始的数据集,且三个子集合之间在图像空间上独立分布没有重复;
步骤4网络训练
对于步骤3中划分的训练集,使用深度卷积神经网络(convolutionslneuralnetwork,cnn)首先提取图像中的水果特征;使用vgg16作为特征提取的卷积神经网络,vgg16网络包含13个卷积(conv)层、13个激活(relu)层及4个池化(pooling)层;设计扩边填充(padding)处理,在卷积计算过程中对图像边缘进行像素值的补0,保证了conv层保证输入和输出矩阵大小一致;对于输入的原始图像对于输入的原始图像通过大小为3*3的卷积核进行卷积运算提取特征图(featuremap),卷积计算公式如式(1)所示;式中
选择基于基于卷积神经网络(convolutionalneuralnetwork,cnn)的ssd(singleshotdetector)检测网络来训练最后的待采摘水果检测识别和定位模型;ssd算法构建的检测网络中使用全卷积层的vgg16作为基础网络来提取目标的特征,即步骤4可以作为步骤5的检测网络的一个部分进行融合;ssd物体检测框架在多层特征图中产生固定大小的边界框和框中类别的置信度,模型训练的总体目标损失函数如式(2)所示;
式中x表示预测框中目标的类别,c是softmax函数对每类别的置信度,n是匹配默认框的数量,权重项α通过交叉验证设置为1;位置损失lloc是预测框
训练过程中在产生的预测框和真实的标签框之间进行偏移回归,其中box={cx,cy,w,h}表示预测框中心坐标及其宽高;使用平移量
置信损失如式(5)所示;
其中
训练阶段使用式(2)作为预测框坐标偏移的回归计算,使其尽可能接近标注框;训练过程中迭代次数、学习率两个参数保持ssd网络初始的默认值。
步骤5模型测试
输入待识别和定位的水果图像,调用训练完成的水果检测模型进行测试,最终输出结果为输入图像中水果的类别信息和位置信息,并通过矩形框将水果标出。
本发明与现有技术相对,具有以下有益效果:本发明基于深度卷积神经网络实现自然场景下水果目标的特征提取,解决了目标场景变化时人为设计和提取的特征代表性不足和欠鲁棒性,能够实现自然生产场景下的待采摘水果特征有效提取和表示。本发明基于ssd深度检测框架将水果的识别和定位转化为回归问题,构建位置预测回归模型来进行水果定位,计算预测框类别置信度概率来识别水果类别,实现了自然生产场景下的待采摘水果的有效和可靠识别和定位
附图说明
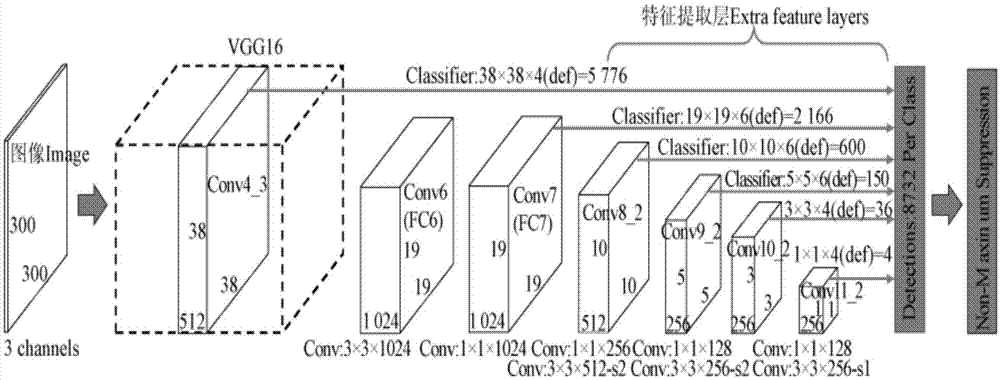
图1为ssd深度检测网络框架。
具体实施方式
以自然生产场景下的待采摘苹果自动识别和定位为例。
硬件设备:
a.数码相机(佳能eos70d)
b.处理平台为amax的psc-hb1x深度学习工作站,处理器为inter(r)e5-2600v3,主频为2.1ghz,内存为128gb,硬盘大小为1tb,显卡型号为geforcegtxtitanx。运行环境为:ubuntu16.0.4,python2.7。
具体的实施方式如下:
step1图像采集
使用佳能数码相机采集自然生长场景下的苹果图像,拍摄时相机高度与成人直立高度相近(1.8米左右),相机镜头角度随机,样本拍摄过程中保持苹果目标在采集图像的中间且清晰,保持成像焦距在整个样本拍摄过程中不变。
step2图像标注
对1000张训练集样本图片中的苹果进行人工标注,标出真实的每一个苹果的最小外接矩形框并记录矩形框左上角和右下角两个顶点的坐标信息。
step3数据集准备
针对step1中采集苹果图片2000张,人工随机选取600张作为验证集,400张作为测试集,剩余的1000张加入步骤2中的标注信息作为训练集。
step4网络训练
step4-1网络部署
在(b)中所述的深度学习工作站(或者任意性能相对高的计算机)上部署ssd检测框架的代码,ssd检测网络结构如附图1所示。ssd的结构以vgg16卷积网络结构为基础并进行了修改,训练时同样经过conv1_1,conv1_2,conv2_1,conv2_2,conv3_1,conv3_2,conv3_3,conv4_1,conv4_2,conv4_3,conv5_1,conv5_2,conv5_3;fc6经过3*3*1024的卷积(原来vgg16中的fc6是全连接层,这里变成卷积层,下面的fc7层同理),fc7经过1*1*1024的卷积,conv6_1,conv6_2(对应图中的conv8_2),conv7_1,conv7_2,conv,8_1,conv8_2,conv9_1,conv9_2,loss。然后一方面:针对conv4_3(4),fc7(6),conv6_2(6),conv7_2(6),conv8_2(4),conv9_2(4)(括号里数字表示每一层选取的默认框(defaultbox)种类数)中的每一个再分别采用两个3*3大小的卷积核进行卷积,最后对每一个类别生成8732个预测框,最有通过非极大值抑制输出最后的预测框。
在保存的ssd代码的vocdevkit目录下建立appledetection文件夹,在appledetection文件夹建立annotations、imagesets、jpegimages三个文件夹。annotations目录下存放step生成的xml格式的训练集标注文件。imageset目录下包含main文件夹,包含四个txt文件:test.txt(包含测试集中样本的图片名称)、train.txt(包含训练集中样本的图片名称)、trainval.txt(包含训练集和验证集中全部样本的图片名称)和val.txt(包含验证集中样本的图片名称)。
jpegimages目录下存放所有的数据图片。
step4-2网络参数调整
修改网络待判别的
类别信息为待识别和定位的苹果(apple),修改网络的预测框类别置信度阈值为0.4,修改预测框大小的最小值为16*16(像素),其余的网络超参数保持默认值。step4-3网络训练
下载ssddemo中预训练好的vggnetmodel并存放到caffe/models/vggnet下(如没有vggnet文件夹则新建一个)。根据step2中测试集的样本数目修改代码中的测试图片数和待识别类别数(修改为1+类别数,这里为apple+background=2);根据自身的硬件环境修改代码中gpu的个数(若只有一个gpu,gpus=”0,1,2,3”===>改为”0”,依次类推)。修改完成后运行训练代码进行网络训练。
训练的过程中,对于所有训练样本首先提取每个卷积层上的特征图(公式1),对于抽取到特征图生成预测框(预测框的生成以特征图上每一个特征点为中心,给予固定长宽比的尺度进行生成),计算预测框中目标的类别(公式5),计算预测框和真实标注框之间的距离(公式3),在训练的过程中联合类别损失和预测框偏移损失作为训练的目标损失函数(公式2)。基于上述完整的一次计算过程完成一次训练,当训练次数达到预定阈值或者损失小于预定阈值训练结束。
step5模型测试
在运行测试代码前,修改测试文件代码中的标签信息存放路径、修改训练完成的检测模型存放路径、修改测试图片的存放路径,上述路径均依据自身对应数据的存放地址来修改和确定。
ssd深度检测网络为端到端的深度网络,将特征提取和模型训练集成于一个网络中。测试时输入待测试样本图像,输出为测试图像中苹果果实的类别信息(apple)和定位结果(最小外接矩形预测框的坐标信息),并最终测试样本中可视化的展现出苹果的预测位置框。
以上所述仅为本发明的优选实施例而已,并不限制于本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!