一种面向主成分分析的差分隐私保护方法与流程
本发明涉及一种面向主成分分析的差分隐私保护方法,属于信息安全技术领域。
背景技术:
随着大数据技术的不断发展,各种信息系统存储的数据越来越丰富,增加了数据分析处理的复杂性。作为数据分析的重要方法之一,主成分分析可以将多变量转换为几个主要变量,这些主要变量能够表示原始数据的绝大部分信息,揭示数据本质。主成分分析实现了数据的简化,使得数据更易使用的同时降低了算法的计算开销。数据集里通常包含着许多隐私信息,如果直接使用机器学习或数据挖掘算法分析数据,将会带来隐私泄露问题。差分隐私保护方法是目前一种热门的隐私保护技术,通过噪声机制实现,即向输出结果中添加随机噪声来保护数据安全,添加的噪声越大,数据越安全,然而,数据的可用性越低,反之亦然。
对于多属性数据,传统拉普拉斯机制对所有属性分配相同大小的隐私预算,这一方案简单易操作,但是会导致添加的噪声太大,数据可用性急剧降低,同时给“不重要”的数据分配隐私预算,浪费了一部分隐私预算,因此效果并不理想。
技术实现要素:
本发明所要解决的问题就是针对背景技术中的缺陷,提供了一种面向主成分分析的差分隐私保护方法,本发明既可以有效地对数据集降维,实现数据的简化,又可以避免对“不重要”的数据添加噪声,减少隐私预算的浪费,从而提高数据的可用性,使发布的数据尽可能反映真实数据,同时保护了数据的隐私。
为了解决上述问题,采用如下技术方案:
本发明的一种面向主成分分析的差分隐私保护方法,基于预设的样本数据集x,样本个数n,样本空间维度d;主成分分析方法包括以下步骤:
步骤1:数据矩阵中心化,即每一维度数据减去本维度的均值;
步骤2:用步骤1得到的数据矩阵计算协方差矩阵
步骤3:计算步骤2中所述协方差矩阵a的特征值λ及特征向量v,满足av=λv;将特征值降序排列有:λ1>λ2…>λd,其对应的特征向量为v1,v2…vd;
步骤4:计算保留的主成分个数k;
步骤5:将原始数据映射到主成分空间得到投影矩阵z;
步骤6:给所述投影矩阵z每列元素分配隐私预算εj,计算添加的随机噪声;
步骤7:给所述投影矩阵z添加噪声,得到加噪后的投影矩阵z′;
步骤8:计算原始数据和低秩近似数据间的误差。
步骤1中,为方便求解协方差矩阵,中心化后各维度均值为0,对每个属性去均值,如式(1)所示:
xj是所有样本第j个属性的数据,x′j是中心化后所有样本第j个属性的数据,xij是数据集x中第i个样本第j个属性的数据,
步骤4中,对设定的一个特征值贡献值α,其中,0≤α≤1,计算要保留的主成分个数k,使其满足实际保留的主成分特征值贡献值per≥α,其中:
步骤5中,所述投影矩阵z=xvk是原始数据在主成分空间上的映射,其中vk=v1,v2…vk是保留的k个主成分对应的特征向量。
步骤6中,所述随机噪声为laplace噪声,即噪声服从laplace分布lap(b),b为尺度参数,b=δf/ε,δf为全局敏感度,ε为隐私预算;
服从尺度参数为b的laplace分布概率密度函数如下:
其中,x表示所有可能的取值,p(x)为所有取值的概率
投影矩阵z=xvk的第j列表示原始数据在第j个主成分上的映射,每一列表示不同的含义,可分配相等或不等的隐私预算εj,其中,1≤j≤k。
分配相等的隐私预算εj:即均分:
分配不等的隐私预算εj:即按权重分配:
步骤7中,加噪后的投影矩阵为z′=(z′1,z′2…z′j…z′k),其中z′j′的表达式如下:
zj是投影矩阵的第j列,
步骤8中,低秩近似矩阵
近似数据误差使用公式(5)计算;
mse-f=||y-x||f(5)
||·||f是矩阵的f范数;矩阵的f范数是指矩阵元素的平方和再开方;
设c是一个m×n的矩阵,则c的f范数为:
本发明采用上述技术方案,与现有技术相比,具有以下技术效果:
本发明针对传统拉普拉斯机制添加噪声太大的缺陷,提出一种更为理想的加噪方式,使得还原得到的低秩近似数据在一定程度上失真,达到隐私保护的目的,同时保证了数据的可用性。本发明方法简单、易操作且不限制数据集大小和属性,特点如下:
(1)为保证主成分分析算法的安全性,通过在投影矩阵中添加适当的噪声,设计了面向差分隐私保护的主成分分析算法,并证明算法满足差分隐私条件;
(2)与传统拉普拉斯机制相比,该方案只对“重要”的数据加噪,避免了隐私预算的浪费。在相同隐私保护程度下,对数据添加噪声更小,从而提高数据的可用性,使发布的数据尽可能反映真实数据,同时保护了数据的隐私。
附图说明
图1是本发明提供的实验中使用的用于测试差分隐私主成分分析算法性能的数据示意图;
图2是本发明提供的面向主成分分析的差分隐私保护方法的工作流程图。
具体实施方式
下面结合附图对本发明的技术方案的实施作进一步的详细描述,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明先计算保留主成分个数,再将原始数据映射到主成分空间得到投影矩阵,为投影矩阵每列元素分配隐私预算,计算添加在数据中的laplace噪声,既可以有效地对数据集降维,实现数据的简化,又可以避免对“不重要”的数据添加噪声,减少隐私预算的浪费,从而提高数据的可用性。本发明所采用的差分隐私保护技术定义了一个及其严格的攻击模型,并对隐私风险进行了严格的数学证明和定量表示,同时差分隐私机制也能在主成分分析结果可用性和安全性两方面取得很好的平衡。
参见图2,具体实施方式如下所示:
步骤1:收集得到样本数据集secom.txt,存放的是半导体制作过程中各属性的数据,样本数为1567,属性个数为591,数据集x={x1,x2…x591},xi是所有样本第i个属性的数据。用公式(1)对每一维数据中心化。取中心化后数据集10个属性数据,如下所示:
x1=[16.47710442,81.32710442,-81.84289558…-35.64289558,-119.53289558,-69.53289558]t
x50=[-7.93969674,-0.99239674,5.01130326…-4.19689674,7.65940326,7.02220326]t
x100=[-0.0266401,-0.0173401,0.1202599…-0.0192401,0.1435599,-0.0647401]t
x150=[-2.54326790,-0.529267903,-1.99526790…-2.84217094e-14,1.43873210,-2.84217094e-14]t
x200=[-0.91205637,0.11794363,-1.82205637…-7.61205637,-2.47205637,-2.84205637]t
x250=[110.29433331,83.37773331,-5.24676669…7.68593331,-10.22116669,12.12073331]t
x300=[-0.04006684,-0.00416684,-0.00196684…-0.02826684,0.02093316,-0.03726684]t
x350=[2.14776410e-03,-2.25223590e-03,-4.45223590e-03…-3.46944695e-17,-3.46944695e-17,-3.46944695e-17]t
x400=[-0.9083303,-1.9865303,-0.2702303…0.3510697,-1.0224303,2.3229697]t
x450=[0.59278442,-0.23961558,-0.46731558…0.38228442,1.83908442,1.08908442]t
步骤2:用步骤1得到的数据矩阵计算协方差矩阵a。
步骤3:计算步骤2协方差矩阵a的特征值λ及特征向量v。将特征值降序排列,前5个特征值及特征向量如下所示:
λ1=53415197.85687523v1=[-6.39070760e-04,2.35722934e-05,2.36801459e-04,…,2.61329351e-08,5.62597732e-09,3.89298443e-04]t
λ2=21746671.90465921v2=[-1.20314234e-04,-6.60163227e-04,1.58026311e-04,…,-6.06233975e-09,5.96647587e-09,-2.32070657e-04]t
λ3=8248376.61529074v3=[1.22460363e-04,1.71369126e-03,3.28185512e-04,…,1.09328336e-09,8.83024927e-09,7.13534990e-04]t
λ4=2073880.85929397v4=[-2.72221201e-03,2.04941860e-04,4.20363040e-04,…,2.66843972e-07,5.91392106e-08,-1.42694472e-03]t
λ5=1315404.38775829v5=[-1.19198101e-05,-3.62618336e-03,-2.27104930e-04,…,-3.24788891e-07,-9.39871716e-08,-3.98748600e-03]t
步骤4:根据公式(2)确定保留主成分个数。取特征值贡献值α=95%,则要求per≥95%,计算得k=5。
步骤5:计算投影矩阵z=xv5。v5=(v1,v2…v5)是保留的5个主成分对应的特征向量。投影矩阵z如下所示:
步骤6:设置添加的随机噪声。设隐私预算ε∈[0.1,1],按均分分配投影矩阵每列分得的隐私预算为
步骤7:根据公式(5)输出低秩近似矩阵。
步骤8:评估算法性能。使用mse-f评估差分隐私主成分分析效果,mse-f是低秩近似数据和原始数据之间的误差,mse-f越小,算法可用性越高。
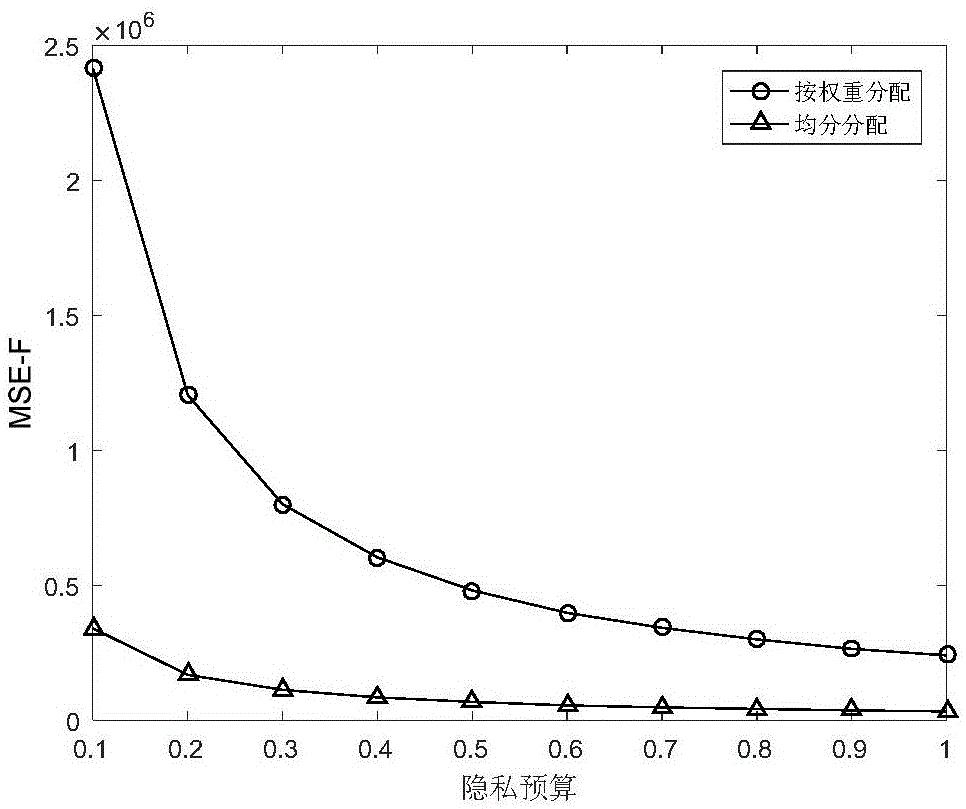
此处是将本发明采用的均分分配隐私预算和按权重分配隐私预算进行比较,比较在相同隐私预算水平下,哪种加噪方式带来的误差更小。由于laplace噪声是随机噪声,所以对应每个ε值,每组实验均进行100次,记录mse-f平均值,如附图1所示。
由图1可知,在相同隐私预算水平下,本发明采用的均分分配比按权重分配带来的误差更小,这说明本发明在相同隐私保护级别下数据可用性更高,并且隐私预算越大,误差越小。
综上所述,本发明提出了一种面向主成分分析的差分隐私保护方法,通过为原始数据投影矩阵每列元素分配隐私预算,在提供隐私保护的同时减少了加入的噪声。本发明可以有效避免对“不重要”的数据添加噪声,减少隐私预算的浪费,从而提高数据的可用性,使发布的数据尽可能反映真实数据,可适用于不同规模和不同维度的数据发布和隐私保护。
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!