针对大规模计算机集群异常程度的评估与分析系统的制作方法
本发明涉及大规模计算机集群,尤其是一种针对大规模计算机集群异常程度的评估与分析系统。
背景技术:
随着大数据、云计算技术的飞速发展,越来越多的企业和个人选择云平台提供的服务,因此对于大规模计算机集群性能可靠性的要求也越来越高。一旦集群的性能出现了问题,将产生极大的损失。这就要求运维人员能够时刻掌握集群的性能运行状态。
计算机集群的运行状态可以通过集群中服务器节点的性能指标来刻画,这些性能指标可大致分为cpu(处理器)、mem(内存)、diskio(磁盘输入输出)、net(网络)四种类型。在集群出现宕机等故障之前,其性能指标会出现异常变化,可以通过实时分析群中每个节点的性能指标评估其异常程度,从而可以及时发现集群出现的性能异常。同时还可以通过对异常发生时刻的性能指标的分析,定位引发异常的性能指标所属类型,辅助运维人员寻找性能异常的原因,提前避免由宕机等可能发生的故障造成的损失。
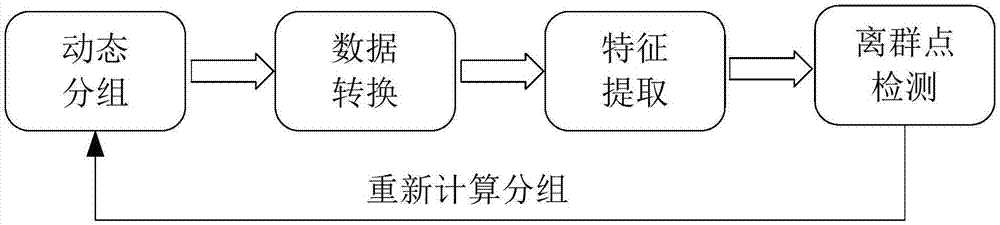
现有的针对大规模集群的异常分析检测方案,将集群中的服务器节点作为基本分析单位。首先将集群中的节点按照运行状态的相似性划分为不同的检测组,在每个检测组中,认为某一时刻大多数节点的运行状态是正常的,个别性能状态特殊的节点被认为是异常节点。如图1所示,这种方案主要分为四步:
首先是动态分组,即按照运行状态的相似性分为不同的检测组。例如运行相似任务的节点被认为具有相似的性能状态,会被分到一组。
然后是数据转换,即收集代表每个节点运行状态的性能数据,并预处理数据为统一格式方便后续分析。
接着是特征提取,即通过主成分分析等降维手段提取最能表现节点运行状态的性能指标维度,降低时间复杂度。
最后是离群点检测,即利用特征提取后的集群中各个节点的性能数据,通过欧式距离等的偏离程度描述手段,计算各个节点的运行状态的差异,选取跟大多数节点最不一致的那部分节点判定为异常节点。按照此步骤不断循环迭代,定期检测集群的运行状态。
现有的集群异常检测方法,在进行检测前需要冗长的预处理流程,无法满足让运维人员时刻掌握集群运行状况的实时性要求。并且检测结果只有异常与否两种状态,不能定量衡量异常程度的大小,对运维人员的提示功能有限。最重要的是不具备异常定位功能,不能分析出异常原因;对运维人员的指导性有限。
技术实现要素:
本发明的目的在于克服现有技术中存在的不足,提供一种针对大规模计算机集群异常程度的评估与分析系统,能够为计算机集群中的各节点实时定量评估异常程度,当异常程度超过阈值时自动报警,还可以自动分析导致异常产生的性能指标,协助运维人员进一步分析造成异常的原因。本发明采用的技术方案是:
一种针对大规模计算机集群异常程度的评估与分析系统,采用主从模式的插件式分层架构,包括主插件和从插件;
所述从插件主要负责异常程度评估与异常原因分析任务,部署在计算机集群中需要检测的节点上;计算机集群中的节点包括服务器节点、终端节点;终端节点位于最上层;
所述主插件用于汇总检测结果与展示;能够部署在计算机集群中任何节点上。
终端节点上的主插件用于汇总检测结果与展示;服务器节点上的主插件用于汇总从插件所在节点的检测结果并向上层的主插件所在节点发送。
进一步地,
所述从插件包括信息采集模块、异常程度评估模块、异常原因分析模块;
所述信息采集模块用于计算机集群中节点性能指标信息的采集与预处理;预处理将每个节点的各种性能指标转换成一条多维的时间序列;
所述异常程度评估模块通过设定的滑动窗口大小,利用lof算法计算信息采集模块输出的多维时间序列来实时分析该节点在时间点p的异常程度;
所述异常原因分析模块用于进一步确定导致产生异常的性能指标维度。
进一步地,所述异常程度评估模块的分析处理过程包括:
s1,根据设定好的滑动窗口大小确定时间点p的第k邻域nk(p);nk(p)表示时间点p的第k距离邻域,时间点p的第k距离dk(p,o)表示距离时间点p第k远的时间点o到时间点p的距离;
s2,计算当前时刻即时间点p第k可达距离r-dist(p,o);
其中r-dist(p,o)=max{dk(p,o),d(p,o)},d(p,o)表示时间点p到时间点o的实际距离;
s3,计算当前时刻即时间点p的局部可达密度lrdk(p);
其中
s4,计算局部异常因子
s5,设定异常阈值,局部异常因子的值若大于等于异常阈值则判定该节点异常。
5.如权利要求4所述的针对大规模计算机集群异常程度的评估与分析系统,其特征在于,
异常原因分析模块的分析处理步骤如下:
b1,去除第i维度的性能指标重新计算局部异常因子得到值lofk-i(p);
b2,重复执行步骤b1,直到所有维度的性能指标都被单独剔除过一遍;
b3,找到lofk-i(p)的最小值,该最小值相对应所去掉的性能指标所在维度即为导致产生异常的性能指标维度。
本发明的优点在于:
1、该系统能够根据当前运行状态实时判断计算机集群运行的健康状况,为运维人员时刻掌握集群的运行状态提供了有益帮助。
2、该系统可以定量衡量集群的异常程度,对比仅仅异常与否的检测结果能让运维人员更加了解集群性能状态。
3、能够分析得出导致异常产生的性能指标类型,辅助运维人员进行故障排查,提高了运维人员的工作效率。
附图说明
图1为现有集群异常检测方法的流程图。
图2为本发明的架构示意图。
图3为本发明的从插件结构示意图。
具体实施方式
下面结合具体附图和实施例对本发明作进一步说明。
本发明提供一种针对大规模计算机集群异常程度的评估与分析系统,是一种基于lof(localoutlierfactor局部异常因子算法)算法的集群运行性能异常程度实时评估与异常定位系统;
本系统采用主从模式的插件式分层架构,包括主插件master和从插件slave;
所述从插件主要负责异常程度评估与异常原因分析任务,部署在计算机集群中需要检测的节点上;计算机集群中的节点包括服务器节点、终端节点;终端节点位于最上层;
所述主插件用于汇总检测结果与展示;能够部署在计算机集群中任何节点上;即一个节点上可以同时部署从插件和主插件,如图2所示;
终端节点上的主插件用于汇总检测结果与展示;服务器节点上的主插件用于汇总从插件所在节点的检测结果(可能包括该服务器节点上从插件的检测结果和其下层的从插件所在节点的检测结果,或仅包含其下层的从插件所在节点的检测结果)并向上层的主插件所在节点发送;
其中从插件包括信息采集模块、异常程度评估模块、异常原因分析模块;每个从插件负责本节点的信息采集和分析工作;如图3所示;
所述信息采集模块用于计算机集群中节点性能指标信息的采集与预处理;刻画计算机集群的运行状态,必须采集计算机集群的各种性能指标;预处理将每个节点的各种性能指标转换成一条多维的时间序列,便于异常程度评估模块进行分析处理;一种性能指标对应于时间序列的一个维度;
所述异常程度评估模块通过设定一定宽度的滑动窗口大小,利用lof算法计算信息采集模块输出的多维时间序列来实时分析该节点在时间点p即p时刻的异常程度;主要步骤如下:
s1,根据设定好的滑动窗口大小确定时间点p的第k邻域nk(p);nk(p)表示时间点p的第k距离邻域,时间点p的第k距离dk(p,o)表示距离时间点p第k远的时间点o到时间点p的距离;
s2,计算当前时刻即时间点p第k可达距离r-dist(p,o);“-”这里不是表示减号,是一条横杠;
其中r-dist(p,o)=max{dk(p,o),d(p,o)},d(p,o)表示时间点p到时间点o的实际距离;
s3,计算当前时刻即时间点p的局部可达密度lrdk(p);
其中
s4,计算局部异常因子
s5,设定异常阈值,比如1,局部异常因子的值若大于等于异常阈值则判定该节点异常;降低误报率;
异常原因分析模块通过改进lof算法,确定异常发生的性能指标维度,只有当上一模块认定此刻该节点出现异常时,才需要进行异常原因分析,否则显示集群运行状态为正常。异常原因分析模块的分析处理步骤如下:
b1,去除第i维度的性能指标重新计算局部异常因子得到值lofk-i(p);
b2,重复执行步骤b1,直到所有维度的性能指标都被单独剔除过一遍;
b3,找到lofk-i(p)的最小值,由于lofk-i(p)最小说明去除的那个维度的性能指标对异常的贡献程度最大,所以该最小值相对应所去掉的性能指标所在维度即为导致产生异常的性能指标维度。例如去掉cpu用户态时间这个性能指标后,lofk-i(p)值最小,那么说明此时产生的异常是由cpu的性能异常导致的。
主插件用于汇总检测结果与展示;只有终端节点上的主插件才有展示功能,其余服务器节点上的主插件汇总下层的从插件所在节点的检测结果,或者汇总该服务器节点(若其上设有从插件)从插件检测结果和下层的从插件所在节点的检测结果,向上层的主插件所在节点发送。
- 还没有人留言评论。精彩留言会获得点赞!