一种超大容量分布式数据库主键的生成算法的制作方法
本发明涉及一种超大容量分布式数据库主键的生成算法,属于软件开发技术领域。
背景技术:
目前互联网应用中数据存储量是海量的,为了提升数据访问效率及安全性的考虑,数据库基本都是分多地多机房部署,这对数据库表的主键设计提出了很高的要求,不但要求数据库主键能适应大并发的性能要求,而且需要考虑数据库迁移、合并变更以及查询效率等诸多需求。
目前一般采用的主键技术有2种,一种是利用数据库自增技术,优点是技术简单,主键自增,具有趋势性,查询时作为索引效率高。缺点是每秒的最大并发数有限制,并且迁移合并会遇到主键重复的问题。
第二种方式是采用uuid的方式。这种方式的优点是主键不会重复,基本没有性能问题,数据库的合并、迁移也没有问题,但由于产生的主键是字符串,没有排序,无法保证趋势递增,所有在查询时效率很低。
应此一个能综合自增主键和uuid主键方式优点,并避免以上两种产生主键方式缺点的数据库主键的算法,具有极大经济效益和社会效益。
技术实现要素:
本发明的目的在于:针对以上现有技术存在的不足,提出超大容量分布式数据库主键的生成算法,从技术原理上解决这一问题。
为了解决上述技术问题,本发明提供了如下的技术方案:
本发明提供一种超大容量分布式数据库主键的生成算法,合成主键的步骤如下所示;
s1:通过全球授时服务获得当前时间自时间基线运行的毫秒数;确定数据产生的时间段;
s2:确定当前时间前提下,通过配置获得当前机器所在机房号;确定数据产生的地址;
s3:通过配置获得当前机器的机器号;确定数据产生的具体用户端;
s4:经过s1-s3的操作步骤,通过流水服务获得当前流水;可确定当前数据的目的,可对其进行分类处理;
s5:合成1-4步获得数据,合成主键。
作为本发明的一种优选技术方案,主键生成算法的返回值采用long类型。
作为本发明的一种优选技术方案,所述主键由41位毫秒数、n位机房数、m位机器数和i位流水构成;其中41位毫秒数是受操作系统指定的,而对应的机房数、机器数和流水的位数可根据实际操作进行取值。
作为本发明的一种优选技术方案,n=4,m=4,i=4。
本发明所达到的有益效果是:本发明操作方法简单,生成支持高并发超大容量分布式数据库的主键。可广泛应用于目前大型互联网中,本发明能在全局管理数据库主键生成的方法,可以很好的实现在多地多机房多主机的分布式数据库中采用一种高性能算法,实现高性能的,大并发的数据库主键生成,满足现在数据库多地多机房多主机分布式的部署方式。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
在附图中:
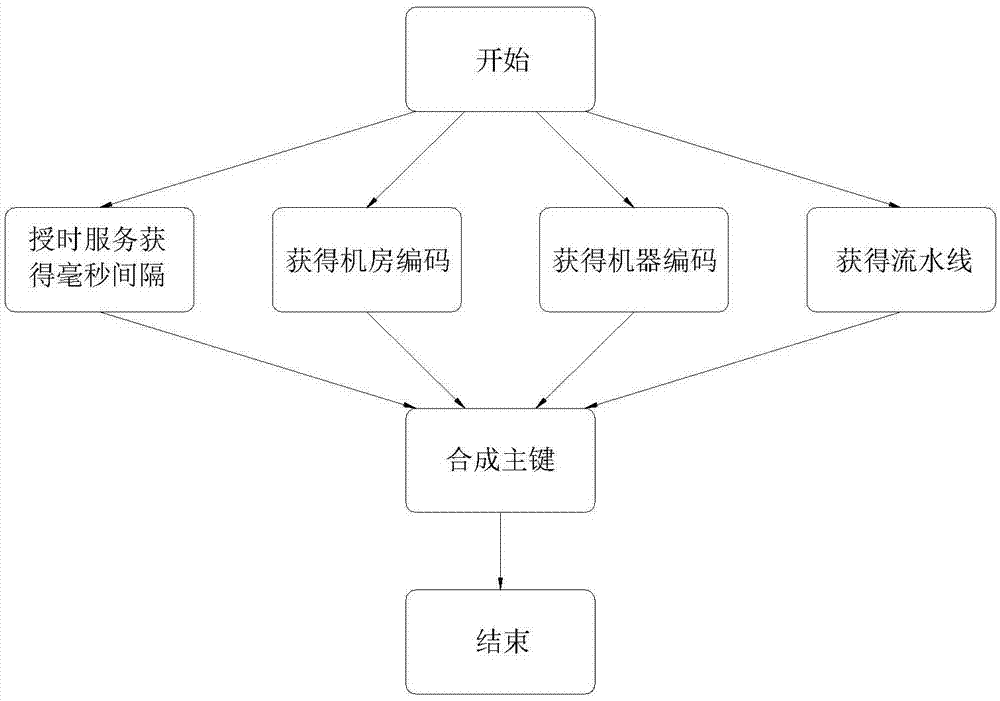
图1为本发明主键的生成流程图。
具体实施方式
以下对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:如图1所示,本发明提供一种超大容量分布式数据库主键的生成算法,合成主键的步骤如下所示;
s1:通过全球授时服务获得当前时间自时间基线运行的毫秒数;确定数据产生的时间段;
s2:确定当前时间前提下,通过配置获得当前机器所在机房号;确定数据产生的地址;
s3:通过配置获得当前机器的机器号;确定数据产生的具体用户端;
s4:经过s1-s3的操作步骤,通过流水服务获得当前流水;可确定当前数据的目的,可对其进行分类处理;
s5:合成1-4步获得数据,合成主键。
主键生成算法的返回值采用long类型,主要考虑到数据库的合并、迁移及查询效率等诸多因素,可获得大数据大并发分布式部署环境下的唯一主键,long类型长度是2^63-1,可以满足数据长度要求。
所述主键由41位毫秒数、n位机房数、m位机器数和i位流水构成;其中41位毫秒数是受操作系统指定的,而对应的机房数、机器数和流水的位数可根据实际操作进行取值,n=4,m=4,i=4。
考虑到查询前端查询效率问题,因此主键需要在查询时能确定该主键对应数据存储的物理位置,因此主键中应该包含机房号及机器号等信息,便于查询服务快速定位数据存储位置,避免分库扫描。为使主键产生具有趋势性及一致性,需要有统一服务调用,返回基于共同遵守某一规则的前缀。在本发明中,该服务由全球统一授时系统返回基于固定时间基线的运行毫秒数保证一致性和趋势性,因此本发明采用的毫秒数为41位。而对应的4位机房数、4位机器数和4位流水主要是考虑现有数据流量考虑,才设置的数值;为考虑到后期硬件性能的提升或运行的操作系统换到其他,而不需要更改程序,相关数据是可以更改的。
流水是指在当前41位毫秒下的流水,目前工程实践中的理论值是4096,在设置过程中设置4位流水,一旦数据量达到10000,就会清0,但是考虑到以后硬件性能提升,或者运行的操作系统换到其他,而不需要更改程序。在毫秒这个度量维度下,4位流水已经能满足现在计算机性能需求了。而单机每秒并发数为4096×1000,每秒400万的单机并发足以满足任何系统的运行。
为了达到以上目的,本发明含有如下部分:
不同地方数据中心,同一秒
1、通过全球授时服务获得当前时间自时间基线运行的毫秒数;
2、通过配置获得当前机器所在机房号
3、通过配置获得当前机器的机器号;
4、通过流水服务获得当前流水;
5、合成1-4步获得数据,合成主键。
这样从时间、地址、用户端和流水号可保证主键的唯一性,因为数据是分布在不同数据中心的,那他产生的机房号就不是一样的,不会出现a,b用户同时新增数据,生成的数据号是一样的情况;而且按这种方式生成主键才能保证数据存储时是按照流水顺序保存,查询时可以充分利用数据库索引,提高效率。而利用主键中的机房号和机器号,更可以快速定位数据存储的物理位置,精确定位物理数据库,提高数据操作效率。
最后应说明的是:以上仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
技术特征:
技术总结
本发明公开了一种超大容量分布式数据库主键的生成算法,合成主键的步骤如下所示;S1:通过全球授时服务获得当前时间自时间基线运行的毫秒数;S2:确定当前时间前提下,通过配置获得当前机器所在机房号;S3:通过配置获得当前机器的机器号;S4:经过S1‑S3的操作步骤,通过流水服务获得当前流水;S5:合成1‑4步获得数据,合成主键。本发明操作方法简单,生成支持高并发超大容量分布式数据库的主键。可广泛应用于目前大型互联网中,本发明能在全局管理数据库主键生成的方法,可以很好的实现在多地多机房多主机的分布式数据库中采用一种高性能算法,实现高性能的,大并发的数据库主键生成,满足现在数据库多地多机房多主机分布式的部署方式。
技术研发人员:俞禄;龚如伟
受保护的技术使用者:上海萃颠信息科技有限公司
技术研发日:2018.10.31
技术公布日:2019.02.01
- 还没有人留言评论。精彩留言会获得点赞!