一种基于深度学习的发票批量自动识别系统的制作方法
本发明涉及信息技术领域,具体涉及一种基于深度学习的发票批量自动识别系统。
背景技术:
发票是日常生活中经常使用的一种凭据,如商业机构、政府机构、医疗机构、公安机构等都需要开具大量的发票。如今互联网技术发展迅猛,线上支付大量普及,随即也出现了相对应的电子发票,但电子发票还是有些弊端,如由于消费者自行打印的电子发票纸质以及打印效果都有差异,容易导致防伪性能消失,或者由于电子发票可以重复打印导致重复报销的风险增大,所以目前传统纸质发票还是广为使用。
发票主要是公司做账的依据,同时也是缴税的费用凭证,因此通常需要财务部门进行发票的管理工作。然而发票管理工作繁琐且乏味,其工作量大、需记录数据多,人为记录需要消耗大量的人力物力。随着技术的发展,现采用图像识别技术,可以快速,准确地提取发票的信息。从而大大减少发票处理时间,节省人力物力,且提高发票信息记录的准确率。
技术实现要素:
本发明的目的是提供一种基于深度学习的发票批量自动识别系统,用以解决传统人工对发票管理记录存在的速度慢、效率低、出错率高的问题。
为了实现上述任务,本发明采用以下技术方案:
一种基于深度学习的发票批量自动识别系统,包括:
发票图像获取模块,用于获取发票的扫描图并进行格式转换,得到发票图像进行保存;然后对发票图像进行摆正处理和归一化处理;
预处理与定位模块,用于对归一化后的发票图像进行倾斜校正和数字区域定位;
字符切割模块,用于对所述的数字区域中的字符进行切割,得到切割后的字符图像;
字符识别模块,用于通过cnn卷积神经网络对切割后的字符图像进行字符识别;
输出模块,用于将识别出的字符记录到excel表格的对应位置,并对字符进行准确性判定与人工更正。
进一步地,所述的对发票图像进行摆正处理和归一化处理,包括:
利用opencv的最小轮廓定位与仿射变换方法,得到摆正后的发票图像;
所述的归一化处理为:
检测发票图像的长度l、宽度r,计算长宽比例k=l/r;
若比例k<1.75,表示发票图像所对应的发票正常,将发票图像归一化至1200×700像素;
若比例k>1.75,表示发票图像所对应的发票不正常,即发票两侧带圆孔的纸条被撕掉;此时在发票图像左右两端分别填充长度为(1.714*r-l)/2、宽度为r的白色纸条图像,再将所述的发票图像与白色纸条图像共同归一化至1200×700像素;
将发票图像转换至r通道,若在发票图像的表头位置检测不到像素点,表示发票图像中发票进行了倒置,此时将发票图像旋转180°。
进一步地,所述的发票图像进行倾斜校正,包括:
读取归一化后的发票图像并进行灰度转换;
利用sobel算子在y方向上的差分阶数,去掉发票图像中的竖线,只检测横线;
利用opencv提供的houghlinesp()函数,检测所述的横线中长度大于550像素的直线;
计算所述直线的平均斜率,根据平均斜率对所述的发票图像进行旋转校正。
进一步地,所述的数字区域定位,包括:
数字区域定位包括两个步骤:首先设定初始范围以进行粗定位,然后采用模板匹配法进行细定位,具体过程如下:
粗定位:对于发票图像上的每一个主要信息,设定一个包含该主要信息所在位置的初始范围,以对每一个主要信息进行粗定位;
细定位:建立每一个主要信息中特定标记的图像模块,利用图像模块在该主要信息的初始范围内采用标准平方差匹配法进行匹配,以匹配度最高的位置右侧的数字区域作为主要信息的图像。
进一步地,对所述的数字区域中的字符进行切割,得到切割后的字符图像,包括:
对于每个细定位得到的主要信息的图像,进行竖直方向的投影,即计算每列存在的像素点数v(x);
从左向右开始对一行字符进行水平扫描,一开始投影v(x)为0,直到v(x)不为0时,即为一个字符的起点,继续向右扫描至v(x)再次为0时,即为字符的终点;向右继续扫描,可扫描出每一个字符;对水平扫描到的每个字符进行标记,将每个字符起点、终点作为竖直切割点;根据每个字符的竖直切割点,对每个字符进行竖直切割;
对于每个经过竖直切割后的字符,再进行水平方向的投影,然后由上向下进行竖直扫描,以获得每个字符的水平切割点;然后根据水平切割点再对字符进行水平切割,由此得到切割后的字符图像。
进一步地,所述的cnn卷积神经网络采用alexnet卷积神经网络,alexnet的参数设置为:batch大小为256,迭代1000次,learningrate初始化为0.001,采用step算法,每500次迭代衰减一次;momentum值为0.9,weightdecay为0.0005,每500个迭代输出一个snapshot。
进一步地,所述的对字符进行准确性判定与人工更正,包括:
若在excel表格中识别出的一张发票图像的所有字符信息中:
发票金额+发票税额≠价税合计,则说明发票金额、发票税额、价税合计三个信息至少一个识别错误,则输出错误信息;
将购买方纳税人识别号、销售方纳税人识别号分别在纳税人信息表格中进行匹配,匹配度高于89%时,认为匹配成功,此时记录购买方纳税人识别号、销售方纳税人识别号在纳税人信息表格中对应的购买方纳税人名称、销售方纳税人名称;如匹配不成功,则输出错误信息;
对于所述的错误信息,在输出模块的显示界面进行人工检查和更正。
进一步地,所述的对字符进行准确性判定与人工更正,还包括:
识别出的两个发票号码相同,若不同,则至少一个识别错误,输出错误信息,进行人工检查和更正;
计算开票日期与当前日期的差值,大于设定的日期时,进行记录。
本发明具有以下技术特点:
1.本发明提出了一种自动识别发票上主要信息的系统,能快速、高效地完成发票上主要信息的识别,克服了以往只能靠人工对发票进行管理而存在的速度慢、效率低、出错率高的问题。
2.本发明系统将发票识别的主要信息录入到excel表中,方便人工校正和后期使用。
附图说明
图1为本发明系统的结构示意图;
图2为增值税发票图像的版面图;
图3为发票的扫描图;
图4为发票两侧附带有可撕掉的白色带圆孔纸条的示意图;
图5为发票图像中各主要信息的特定标记示意图;
图6为发票图像采集至字符切割过程的流程示意图;
图7为边缘检测过程中检测横线的效果图;
图8为alexnet网络模型图。
具体实施方式
本发明的总体设计思想是:采用扫描仪批量扫描发票获得发票图像并输入,对发票进行归一化处理,基于模板匹配算法的信息定位,投影算法的字符切割,再用cnn卷积神经网络进行字符识别,并加入判断与人工修改模块,可根据信息间的相互联系,自动判断信息识别是否有误,并可进行人工修改,提高系统的容错性。最后,将识别正确的信息自动记录到excel相应的位置。
一种基于深度学习的发票批量自动识别系统,如图1所示,包括以下依次连接的模块:
1.发票图像获取模块
发票图像获取模块用于获取发票的扫描图,如图3所示,并将扫描图进行格式转换,转换为jpg格式的发票图像,保存在文件库中;利用opencv的最小轮廓定位与仿射变换方法,得到摆正后的发票图像,以完成发票图像的获取,然后对获取的发票图像进行归一化处理。
本实施例中,发票图像获取模块采用具有自动识别功能(ocr)和滤红功能(r通道)的扫描仪对发票进行扫描,得到pdf格式的发票扫描图,然后利用mupdf库将pdf格式的发票扫描图转换为jpg格式的发票图像。
获取到的发票图像中,普遍存在以下两种情况:第一种情况:对于增值税发票,其左右两侧附带有可撕掉的白色带圆孔纸条,如图4所示;一些情况下带圆孔纸条会被撕掉,使得撕掉后的发票尺寸与未撕时有差异;如直接将这种发票图像进行同样大小的归一化处理,发票图像会在水平方向上进行拉伸,字符宽度发生变化,不利于后续处理过程;第二种情况:发票在扫描时倒置,使得获取的发票图像中发票处于倒置状态,即旋转了180°。
从图3可以看到,获取发票图像后,为了避免上述两情况,以更好地进行发票图像的信息定位,需要对获取的发票图像进行归一化处理。
所述的发票图像获取模块还用于实现以下归一化功能:
(1)检测发票图像的长度l、宽度r,计算长宽比例k=l/r;
(2)若比例k<1.75,表示发票图像所对应的发票正常,将发票图像归一化至1200×700像素;
(3)若比例k>1.75,表示发票图像所对应的发票不正常,即发票两侧带圆孔的纸条被撕掉;此时:
在发票图像左右两端分别填充长度为(1.714*r-l)/2、宽度为r的白色纸条图像,再将所述的发票图像与白色纸条图像共同归一化至1200×700像素;
(4)由于发票表头盖有红色印章,因此将发票图像转换至r通道,若在发票图像的表头位置检测不到像素点,表示发票图像中发票进行了倒置,此时将发票图像旋转180°。
上述过程将发票图像归一化至同样的尺寸;具体地,由于目前发票的标准尺寸为长24cm,宽14cm,因此为减少发票图像处理时的计算量,同时能切割出清晰的字符,发明人经过大量的实验,设定归一化后发票图像的尺寸为1200×700像素。
2.预处理与定位模块
预处理与定位模块用于对归一化后的发票图像进行倾斜校正和数字区域定位;
2.1倾斜校正
尽管在发票图像获取模块中对图像进行了仿射变换,但发票图像还可能存在轻微倾斜。倾斜的发票图像会给数字分割和识别带来较大的干扰,识别率大幅降低。因此需要对发票图像进行倾斜校正。由于发票具有固定数目的等长的横线、竖线,因此可以通过计算发票中横线的角度来确定发票倾斜的角度。本方案利用hough变换的方法检测发票图像中满足预设条件的直线,然后计算满足条件的直线的平均斜率,用求得的平均斜率作为图像倾斜校正的旋转角度,达到预期目标。具体步骤如下:
2.1.1读取归一化后的发票图像并进行灰度转换;
2.1.2边缘检测:利用sobel算子在y方向上的差分阶数,去掉发票图像中的竖线,只检测横线,如图7所示;
2.1.3hough直线检测:利用opencv提供的houghlinesp()函数,检测所述的横线中长度大于550像素的直线;
2.1.4计算所述直线的平均斜率,根据平均斜率对所述的发票图像进行旋转校正。
当发票图像倾斜角较小或者出现皱褶的情况,求最长直线的斜率可能会出现误检的情况,这时再旋转校正就达不到预期的效果。本方案选取多条满足给定长度的直线求斜率,再求均值,可以有效地避免直线误检的情况,从而准确的校正图像的倾斜。
2.2数字区域定位
数字区域定位包括两个步骤:首先设定初始范围以进行粗定位,然后采用模板匹配法进行细定位,具体过程如下:
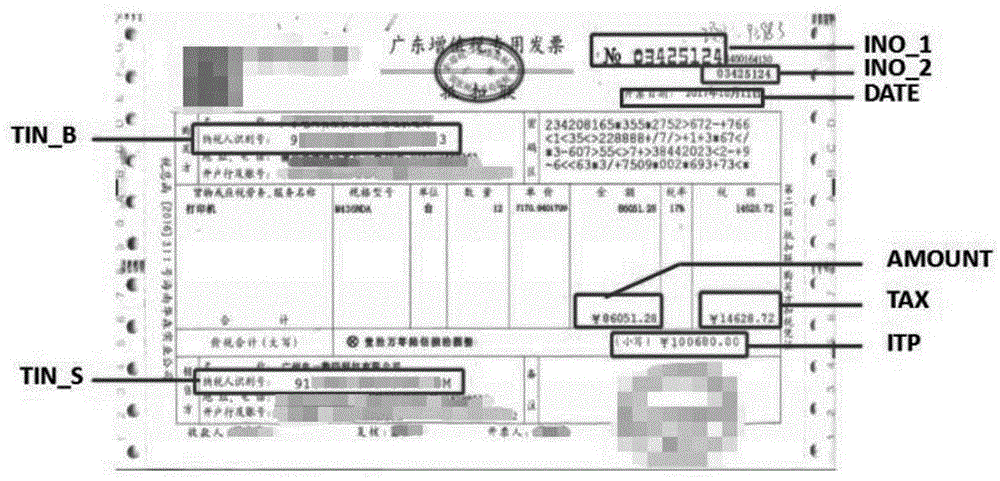
如图2、图5所示,在发票上的各类信息众多,而财务人员只需要记录其中的几个主要信息(包含文字及数字),即购买方纳税人识别号、销售方纳税人识别号、发票号码(2个,其中一个为发票右上角“no”之后的一串数字,另一个为该串数字右下方的一串数字,如图2中的ino_1和ino_2)、开票日期、发票金额、发票税额以及价税合计。由于在前面的归一化和倾斜校正处理后,发票图像上各主要信息之间的相对位置几乎已经绝对固定,因此进行采用以下的方法进行粗定位和细定位:
2.2.1粗定位:对于发票图像上的每一个主要信息,设定一个包含该主要信息所在位置的初始范围,以对每一个主要信息进行粗定位。
例如对于销售方纳税人识别号(包含“纳税人识别号”这几个文字以及这几个文字之后的数字)这条主要信息,其在发票上的位置为左下角,经过前面的处理过程后,每个发票图像中该主要信息的位置基本上是固定的。因此对于该主要信息,可在发票图像的左下角画定一块包含该主要信息的矩形初始范围(矩形框),作为对该主要信息的粗定位。其他的主要信息也按相同的方法进行粗定位。
2.2.2细定位:建立每一个主要信息中特定标记的图像模块,利用图像模块在该主要信息的初始范围内采用标准平方差匹配法进行匹配,以匹配度最高的位置右侧的数字区域作为主要信息的图像;并且可确认几个主要信息之间的相互位置通过图像模块进行验证。
细定位所采用的方法是模板匹配法,例如对于“开票日期:2018年1月5日”这条主要信息,将这条主要信息中的文字“开票日期”作为该条主要信息的特定标记进行图像模块的建立。例如可选取“开票日期”这几个文字最小外接矩形框范围内的图像块作为特定标记的图像模块。
对于其他的主要信息,一般选取主要信息中数字前方或斜前方的文字或符号作为该主要信息的特定标记,如图5所示,例如“开票日期”、“¥”、“no”等。
由于每张发票图像中都包含“开票日期”,因此在前面的粗定位过程中,设定了每个主要信息的初始范围,细定位时在每个主要信息的初始范围内采用标准平方差匹配法进行匹配,匹配度最高的位置即特定标记的所在位置,特定标记右侧的数字区域的图像即为主要信息的图像,即要进行识别的具体数字信息。例如采用“开票日期”作为特定标记进行匹配时,发票图像上该主要信息的初始范围内进行匹配后,找到匹配度最高的位置即发票图像上“开票日期”这几个字所在的位置,则这几个字右侧的数字区域即为“2018年1月5日”这条数字信息。
所述的特定标记右侧的数字区域的大小根据不同的数字信息设定不同的大小,例如纳税人识别号较长,则右侧数字区域设定大一些,以包含所有数字信息;而发票税额的特定标记右侧区域可以设定小一些,每一种特定标记右侧数字区域的大小以能完全包含该区域的最大数字长度为准。
3.字符切割模块
字符切割模块用于对所述的主要信息的图像中的字符进行切割,得到切割后的字符图像,具体的切割步骤如下:
3.1对于每个细定位得到的主要信息的图像,进行竖直方向的投影,即计算每列存在的像素点数v(x);
3.2从左向右开始对一行字符进行水平扫描,一开始投影v(x)为0,直到v(x)不为0时,即为一个字符(汉字或数字)的起点x1,继续向右扫描至v(x)再次为0时,即为字符的终点x2;按照同样的方法向右继续扫描,可扫描出每一个字符;对水平扫描到的每个字符进行标记,将每个字符起点、终点作为竖直切割点;
同理,逐行对字符进行扫描,可得到每个字符的竖直切割点;
3.3根据每个字符的竖直切割点,对每个字符进行竖直切割;
3.4对于每个经过竖直切割后的字符,再进行水平方向的投影,然后由上向下进行竖直扫描,以获得每个字符的水平切割点;然后根据水平切割点再对字符进行水平切割,由此得到切割后的字符图像。
步骤3.4中进行竖直扫描时,采用和步骤3.1—3.3相同的方法,不同之处在于扫描方向不同,即将3.1-3.3中的“竖直”改为“水平”,在此不赘述。
4.字符识别模块
用于通过cnn卷积神经网络对切割后的字符图像进行字符识别。
caffe是一个清晰且高效的深度学习框架,字符识别模块在进行字符识别时采用caffe框架进行训练后的alexnet模型,如图8所示。alexnet是一个卷积神经网络,其结构包括:
卷积层,一个卷积层包含多个卷积面,每个卷积面又关联一个卷积核。由上一层级的map经过卷积核处理,再通过激励函数就可以得到新一层的特征map,计算公式如下:
其中,mj为输入特征图,
下采样层,也称为池化层,该层是对上一层的特征图做压缩处理,因此输出特征图的个数与上层特征图个数一致。计算公式为:
其中,
全连接层,其向前传递与bp神经网络算法类似,计算前需要将输入的二维特征图展开成一维,再进行全连接计算,计算公式为:
其中,
输出层,采用softmax分类器,以对本方案中的字符图像进行识别。
alexnet训练采用随机梯度下降算法,使得互熵损失函数达到最小。本方案的训练过程为:建立不同主要信息所对应字符的文件夹,将切割后得到的字符图像进行人工分类,再在其中选出训练样本、测试样本。本方案的alexnet共有8层,前五层为卷积层,后三层是全连接层,最后一个全连接层的输出具有10个输出,分别为0-9。其中卷积层用于特征提取,其中卷积是进行特征提取,池化作用是降维,全连接层用于图像分类。
alexnet模型的参数设置为:batch大小为256,迭代1000次。learningrate初始化为0.001,采用step算法,每500次迭代衰减一次。momentum值为0.9,weightdecay为0.0005,每500个迭代输出一个snapshot。
本实施例中,alexnet模型的输入图片大小为224×224×3;
第一层卷积层,采用96个11×11的卷积核,滑动步长为4个像素,即输出96个特征图,作为比像素更为高级的特征;再进行最大值池化降维,得到大小55×55的特征图。
第二层,采用256个5×5的卷积核,产生256个特征图,再进行最大值池化降维,得到大小27×27的特征组;
第三、四层,采用384个3×3的卷积核,得到384个特征图;
第五层,采用256个3×3的卷积核,再进行最大值池化降维。得到256个大小为6×6的特征图;
第六、七层为全连接层,各有4096个节点;
第八层为最终分类结果层。
本实施例中,对数字字符进行0-9的分组,并各选取180张字符图片作为训练样本,60张作为测试样本,并归一化大小为28×28分别绑定标签为0,1,2,…,9。
5.输出模块
输出模块用于将识别出的字符记录到excel表格的对应位置,并对字符进行准确性判定和人工更正;输出模块具有显示界面,例如显示屏,以便于人工核查修改。具体可借助libxl库,将识别出的字符自动记录到excel中对应位置。所述的对应位置是指,在excel表格中,例如以第一列作为“购买方纳税人识别号”的记录列,第二列作为“销售方纳税人识别号”的记录列,则对第一张发票图像识别后,将“购买方纳税人识别号”该主要信息识别出的数字字符填写到第一列的第一行,对第二张发票图像识别后将“购买方纳税人识别号”该主要信息识别出的数字字符填写到第一列的第二行,以此类推。excel表格中每一行记录的信息即为一张发票图像识别出的所有信息。
所述的准确性判定和人工更正包括:
若在excel表格中识别出的一张发票图像的所有字符信息中:
5.1发票金额+发票税额≠价税合计,则说明发票金额、发票税额、价税合计三个信息至少一个识别错误,则输出错误信息,然后在输出模块的显示界面进行人工检查和更正。
5.2将购买方纳税人识别号、销售方纳税人识别号分别在纳税人信息表格中进行匹配,匹配度高于89%时,认为匹配成功,此时记录购买方纳税人识别号、销售方纳税人识别号在纳税人信息表格中对应的购买方纳税人名称、销售方纳税人名称;如匹配不成功,则输出错误信息,然后在输出模块的显示界面进行人工检查和更正。
由于纳税人识别号和纳税人名称存在一一对应关系,而财务人员处会有记录该信息的纳税人信息表格。该步骤的思路是,对于识别出的纳税人识别号(购买方、销售方),在纳税人信息表格进行匹配,纳税人识别号18位,允许2位识别错误,即识别率89%以上时,认为该纳税人识别号存在于纳税人信息表格中,将纳税人信息表格中该纳税人识别号对应的纳税人名称记录到所述的excel表格中,并与excel表格中的纳税人识别号进行对应关联。
5.3识别出的两个发票号码相同,若不同,则至少一个识别错误,输出错误信息,进行人工检查和更正;
所述的两个发票号码是指发票右上角“no”之后的一串数字,以及该串数字右下方的一串数字,两个都是发票号码,数字是相同的,如图2所示。
5.4计算开票日期与当前日期的差值,大于设定的日期时,进行记录。
有部分规定发票超过一定日期,例如180天时不能报销,则记录该发票,以便于后期查找。
- 还没有人留言评论。精彩留言会获得点赞!