一种机器人机械臂抓取物体的抓取点自动定位方法与流程
本发明属于目标识别与机器人机械臂智能抓取领域,尤其是涉及一种机器人机械臂抓取物体的抓取点自动定位方法,是一种基于rgb-d图像的目标识别和抓取点定位技术。
背景技术:
随着工业自动化水平的提高,机器人的应用不断深入和完善。机器人协同工作越来越多地受到人们的关注,但现在的工业机器人灵活程度低,只能根据教程完成单一的抓取和安装,无法根据物体不同的位置做成相应的判断,在生产过程中,需要大量的机器人共同进行工作,实现工业生产,这样不仅提高了生产成本,而且大量的机器人共同工作,占有了大量的空间。
机器人机械臂对于物体的智能抓取具有巨大的应用需求,而机器人机械臂对物体的抓取主要涉及两个主要方面,第一个方面主要是视觉检测,包括物体id的自动识别和抓取点的自动定位,因为不同物体的形态不同抓取点也不同;第二方面是主要是抓取物体的机器人机械臂控制。而现有技术中对于第一个方面的定位还存在不够精确等不足。
现有技术中的一种方法是通过采集rgb-d图像,基于深度学习进行候选区域划分,经过白化处理后输入训练好的神经网络获取抓取位置。该方法在区域划分时每张图片要产生数千个候选区域,将每个候选区域输入卷积神经网络进行检测,计算量大,检测速度慢,不适用于实时性能要求较高的领域。且该方式仅能获取到目标物的抓取候选区域,无法确定目标的三维姿态,因此对于随意放置的目标物难以根据其不同位姿规划出最佳抓取方式。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种。
本发明的目的可以通过以下技术方案来实现:
一种机器人机械臂抓取物体的抓取点自动定位方法,包括以下步骤:
1)获取物体的rgb彩色图像和深度图像;
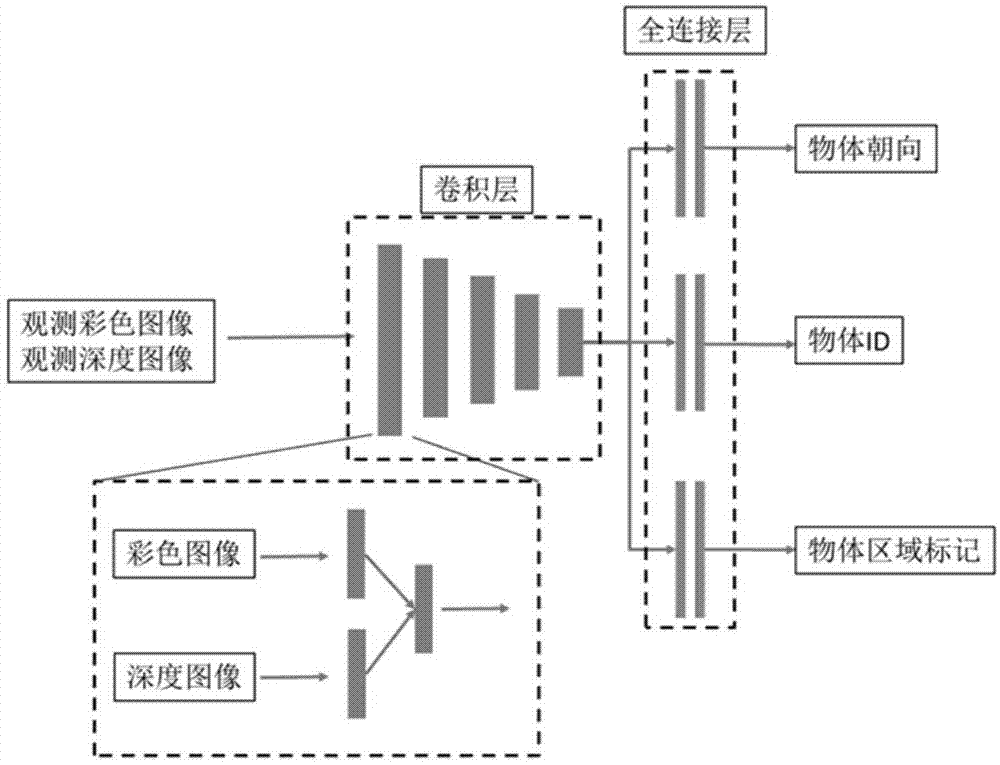
2)将所述rgb彩色图像和深度图像通过一训练好的深度卷积神经网络模型,识别获取对应的物体区域标记、物体id和物体朝向;
3)根据所述物体id选取对应物体的先验三维模型,根据所述物体区域标记和物体朝向将所述先验三维模型中最佳抓取点变换至实际观测空间,实现实际观测空间中抓取点的定位。
进一步地,所述深度卷积神经网络模型包括:
特征提取模块,包括多个卷积子模块,对输入图像进行卷积计算,提取多维特征图谱;
特征池化模块,包括多个池化层,每个池化层对应连接于一所述卷积子模块之后,对所述多维特征图谱进行去最大值下采样;
估算模块,包括多个全连接层,连接于所述特征池化模块之后,用于估算获得物体区域标记、物体id和物体朝向。
进一步地,所述特征提取模块中,第一个卷积子模块分为两个信息流,一个是对rgb彩色图像进行特征提取,一个是对深度图像进行特征提取,两个信息流合并后输入第二个卷积子模块。
进一步地,所述卷积子模块包括相连接的两层卷积层。
进一步地,所述估算模块包括分别用于估算物体区域标记、物体id和物体朝向的三个估算子模块,每个所述估算子模块由两个全连接层构成。
进一步地,所述深度卷积神经网络模型中,每个卷积层后设有非线性激活层。
进一步地,所述深度卷积神经网络模型训练时采用的样本数据库通过以下方式获得:
从在线3d模型库中获取各类物体模型,对各物体模型赋予对应物体id,并标记最佳抓取点,多视角渲染所述物体模型,生成rgb彩色图像集和深度图像集,所述rgb彩色图像集和深度图像集构成样本数据集。
进一步地,进行所述多视角渲染时,渲染背景随机设置为nyu-depthv2背景图片或者make-3d室外背景图片。
进一步地,所述根据所述物体区域标记和物体朝向将所述先验三维模型中最佳抓取点变换至实际观测空间具体为:
301)根据估算的物体朝向,对选取的先验三维模型进行渲染得到三维点云p_gt;
302)根据估算的物体区域标记,将输入的深度图像物体标记区域的像素转化为三维点云p_input;
303)将所述三维点云p_gt和p_input配准,获得最优的旋转参数r和平移参数t;
304)根据所述旋转参数r和平移参数t将先验三维模型中的最佳抓取点变换至实际观测空间。
进一步地,所述将所述三维点云p_gt和p_input配准具体为:
将三维点云p_gt和p_input的重心进行配准,采用最近点迭代的方法求解最优的旋转参数r和平移参数t。
与现有技术相比,本发明具有以如下有益效果:
1)本发明通过深度卷积神经网络模型估算物体id、物体朝向以及物体的二值标记图,根据估算的物体id标记将对应物体的三维模型配准到观测场景中,并将预先标记的最佳抓取点迁移到观测空间中,实现抓取点的自动定位,使得即使抓取点在当前观测视角下由于自遮挡不可见,也能准确定位抓取点的空间位置,抓取定位更加精确可靠。
2)本发明设计的深度卷积神经网络模型可实现特征提取、特征池化和估算,能够对物体id、物体朝向以及物体区域标记实现精确估计,进而提高定位精度。
3)本发明深度卷积神经网络模型中,在每个卷积层后加入relu非线性激活层,使得整个网络具备模拟高阶非线性函数的能力。
附图说明
图1为本发明的深度卷积神经网络结构示意图;
图2为本发明的流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图2所示,本实施例提供一种机器人机械臂抓取物体的抓取点自动定位方法,该机械臂可以立即为工业机器人机械臂,或其它类型机器人的机械臂,或类似的自动化机械机构。
包括以下步骤:
1)获取物体的rgb彩色图像和深度图像;
2)将所述rgb彩色图像和深度图像通过一训练好的深度卷积神经网络模型,识别获取对应的物体区域标记、物体id和物体朝向;
3)根据所述物体id选取对应物体的先验三维模型,根据所述物体区域标记和物体朝向将所述先验三维模型中最佳抓取点变换至实际观测空间,实现实际观测空间中抓取点的定位。
如图1所示,本实施例的深度卷积神经网络模型包括:
特征提取模块,包括多个卷积子模块,对输入图像进行卷积计算,提取多维特征图谱;
特征池化模块,包括多个池化层,每个池化层对应连接于一所述卷积子模块之后,对所述多维特征图谱进行去最大值下采样;
估算模块,包括多个全连接层,连接于所述特征池化模块之后,用于估算获得物体区域标记、物体id和物体朝向。
本实施例的特征提取模块由5个卷积子模块组成,且第一个卷积子模块分为两个信息流,一个是对rgb彩色图像进行特征提取,一个是对深度图像进行特征提取,两个信息流合并后输入第二个卷积子模块。各卷积子模块包括相连接的两层卷积层,2层卷积层的卷积核大小均为3*3,5个模块内每层包含的卷积核个数分别为64,128,256,256,512。特征池化模块对应设置有5个池化层。
估算模块包括分别用于估算物体区域标记、物体id和物体朝向的三个估算子模块,每个所述估算子模块由两个全连接层构成。
物体朝向的估算子模块输出为一个3维向量,分别为沿x,y,z轴的旋转角度;物体id的估算子模块输出为一个30维向量,向量每一位表示是该id物体的概率;物体区域标记的估算子模块输出为一个112x112的二值标记图,而后通过双线性插值恢复成224x224的标记图,用于比较图像中物体占用的像素区域。
深度卷积神经网络模型中,每个卷积层后设有relu非线性激活层,使得整个网络具备模拟高阶非线性函数的能力。
上述深度卷积神经网络模型训练时采用的样本数据库通过以下方式获得:
从在线3d模型库中获取各类物体模型,对各物体模型赋予对应物体id,并标记最佳抓取点,多视角渲染所述物体模型,生成rgb彩色图像集和深度图像集,所述rgb彩色图像集和深度图像集构成样本数据集。
本实施例中,从googlewarehous中获得共30个物体模型,包括杯子、锁具、台灯、玩具等,并进行id顺序编号(从1开始,id标号可视为类别标注);多视角渲染三维物体模型,得到rgb彩色图像和深度图像共10000张,其中包含物体区域,物体朝向和物体id三类标注;9000张作为训练样本,1000张作为测试样本。进行所述多视角渲染时,渲染背景随机设置为nyu-depthv2背景图片或者make-3d室外背景图片。将彩色图像和深度图像裁剪并缩放至224*224图像大小后输入深度卷积神经网络模型。
对深度卷积神经网络模型训练时,设置网络的学习率和动量参数,利用matconvnet训练上述卷积神经网络模型,直至网络收敛。
根据所述物体区域标记和物体朝向将所述先验三维模型中最佳抓取点变换至实际观测空间具体为:
301)根据估算的物体朝向,对选取的先验三维模型进行渲染得到三维点云p_gt;
302)根据估算的物体区域标记,将输入的深度图像物体标记区域的像素转化为三维点云p_input;
303)将所述三维点云p_gt和p_input配准,首先将三维点云p_gt和p_input的重心进行配准,然后采用最近点迭代的方法求解最优的旋转参数r和平移参数t;
304)根据所述旋转参数r和平移参数t将先验三维模型中的最佳抓取点变换至实际观测空间。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!