一种基于深度学习图像识别的餐厅自动结算方法及系统与流程
本发明涉及餐饮结算技术领域,尤其涉及一种基于深度学习图像识别的餐厅自动结算方法及系统。
背景技术:
餐饮是人们生活中必不可少的环节,随着城市生活节奏的不断加快,越来越多的人通过餐厅解决饮食问题。目前餐厅的主流做法是自主选择然后统一结账计费。总体而言,目前的餐厅结算方式主要有:
(1)传统人工结算方法:
传统人工结算由人工辨别菜品类别、费用并作总计,就餐高峰期时就餐人员较多,人工结算行区分计算效率低下且容易导致错误。
(2)基于条码识别的结算方法:
在餐盘上贴有条码标签与对应的菜价关联,在计费终端用红外或激光条码扫描枪进行读取得到相应价格,再以人工或自动的方式计算总金额实行结算。相较于传统的人工结算,结果更精确可靠,但是由于需要对餐盘逐个扫描,结算效率提升有限,且条码标签易损坏,实际使用时效果并不理想。
(3)基于rfid识别的结算方法:
事先在餐盘内嵌rfid芯片,将菜品价格与相应芯片关联,在计费终端对芯片内容进行读取得到相应菜肴价格。此方法的缺点是必须使用专门的餐具,结算系统成本高,部署复杂,内嵌芯片易损坏。
(4)基于图像识别的结算方法:
现有的基于图像识别的结算方法,将菜品的像素特征或餐盘的颜色、形状、花纹特征与菜价进行关联,在计费终端通过图像识别方法得到相应菜品价格。其中:菜品识别模型复杂,识别率低、易出错,且推出新菜需要重新更新复杂模型;基于餐盘颜色、形状识别的结算系统,识别特征单一,易受光线、角度、餐盘遮挡因素的影响,面对识别环境较差的场景鲁棒性很差;对于在餐盘上印刷特殊图案的识别结算方法,需要使用专门的特殊餐具,后期增添新餐具将不通用。
技术实现要素:
针对目前基于图像识别的结算方法模型复杂,识别率低,在某些使用场景下鲁棒性差,实际使用成本高的缺陷,本发明提出一种基于深度学习图像识别的餐厅自动结算方法及系统。
为实现上述目的,本发明所采取的技术方案是:
一种基于深度学习图像识别的餐厅自动结算方法,其特征在于,包括以下步骤:
(1)通过单目摄像头采集餐盘识别区的完整图像;
(2)将获取的完整图像输入到enetobjectdetection模型系统,首先经过骨干网络enet提取基本特征,再经过ffwa过滤筛选出便于定位和识别的优质特征,然后输出可信度(conf)和初步的定位框、类别标签;
(3)通过自适应的nms算法进行后处理,筛选掉可信度(conf)较低的定位框;
(4)输出最终的定位框及类别标签数据;
(5)将最终的定位框及类别标签数据传输至计价程序;
(6)计价程序将最终的定位框及类别标签数据转换成菜品种类及数量,根据预先录入的菜价计算并显示菜品总价格;
(7)客户通过支付系统完成付款,回到步骤(1)。
所述的“定位框”及“类别标签”的生成方法及作用分别是:输入餐盘识别区图像后,算法模型从整个图像中识别出餐盘并用框图标记出来,便于记录餐盘数量,此即生成“定位框”;与此同时,算法识别出不同种类的餐盘,为便于区分不同种类而对餐盘施加标签,此即生成“类别标签”。
所述的定位框及类别标签数据属于一种特征数据,把这些特征数据与具体的菜品种类、数量进行对应,当生成具体的“定位框”及“类别标签”数据时,就会生成对应的菜品种类及数量数据。
一种实施所述方法的系统,其特征在于,包括:
(1)用于采集餐盘识别区的完整图像的单目摄像头;
(2)图像处理模块,用于将单目摄像头采集的完整图像进行图像处理,输出定位框及类别标签数据;
(3)计价程序模块,用于将最终的定位框及类别标签数据转换成菜品种类及数量,根据预先录入的菜价计算并显示菜品总价格;
(4)支付系统,用于客户根据计价程序模块提供的菜品总价格完成付款。
所述的图像处理模块为enetobjectdetection模型。
所述的enetobjectdetection模型包括:
(a)用于提取完整图像基本特征的骨干网络enet模块;
(b)用于过滤筛选出便于定位和识别的优质特征的ffwa模块;
该完整图像经过enet模块和ffwa模块的处理后输出可信度(conf)和初步的定位框、类别标签;
(c)自适应的nms算法模块,用于对经过enet模块和ffwa模块输出的数据进行后处理,筛选掉可信度(conf)较低的定位框,并输出最终的定位框及类别标签数据。
所述的图像处理模块、计价程序模块和支付系统安装在计算机系统中运行。
本发明的有益效果是:采用基于深度学习的视觉技术结算系统,在具有使用视觉技术相较于其它结算方式的成本低、部署灵活、鲁棒性强等优势的同时,利用特定的深度学习技术使餐盘生成更加具有表达力和泛化力的特征,在识别环境较差的场景也具有很好的鲁棒性,餐盘识别准确度更高,可识别的餐盘种类也更多。另外,通过特定的自适应nms算法提高了检测遮挡物体的召回率,可以有效解决餐盘遮挡问题。再者,针对本发明的算法系统,设计了特定的损失函数,可以训练模型解决困难案例、物体间遮挡等问题。
附图说明
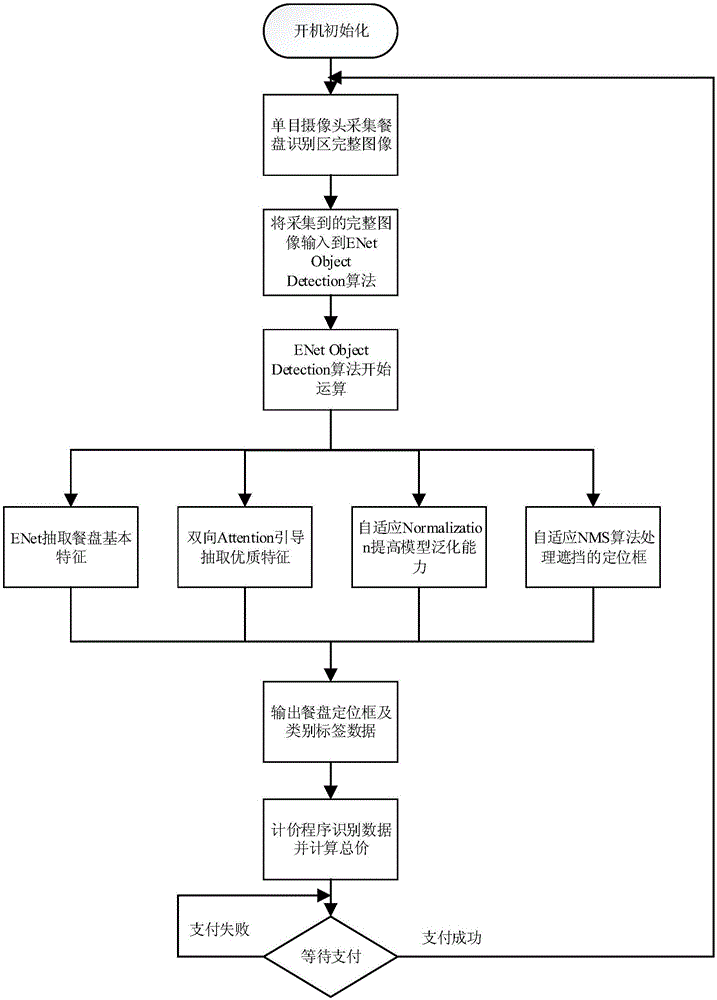
图1为本发明的餐厅结算系统使用时的运行流程图
图2为本发明的餐厅结算系统中的enetobjectdetection算法模型运行流程图;
图3是两次shuffle(doublechannelshuffle)的原理说明图;
图4是channelattention机制的原理说明图;
图5是ffwa(fastfpnwithattention)的原理说明图。
具体实施方式
参见图1-图5,本发明一种基于深度学习图像识别的餐厅自动结算方法,基本思路是:采用单目摄像头获取餐盘图像,输入到enetobjectdetection算法模型(系统),在经过已训练好的(让系统做识别餐盘的重复训练,为深度学习的通用训练过程)enetobjectdetection模型运算后,输出餐盘的“定位框”及“类别标签”数据,计价程序处理这些数据得到餐盘数量及类别,根据预先录入的菜价计算并显示菜品总价格,方便客户付款。所述的“定位框”及“类别标签”分别是:输入餐盘识别区图像后,算法模型可从整个图像中识别出餐盘并用框图标记出来,便于记录餐盘数量,此即生成“定位框”;与此同时,算法识别出不同种类的餐盘,为便于区分不同种类而对餐盘施加标签,此即生成“类别标签”。
本发明的具体方法包括以下步骤:
(1)通过单目摄像头采集餐盘识别区的完整图像;餐盘识别区指单目摄像头能拍摄到的区域,在这个区域能够拍摄到完整的餐盘图像。
(2)将获取的完整图像输入到enetobjectdetection模型系统,首先经过骨干网络enet提取基本特征,再经过ffwa过滤筛选出便于定位和识别的优质特征,然后输出可信度(conf)和初步的定位框、类别标签。
(3)通过自适应的nms算法进行后处理,筛选掉可信度(conf)较低的定位框。具体筛选的方法就是运行自适应的nms算法,本发明选用的自适应的nms算法是soft-nms算法,是一种专门用于后处理的算法。
(4)输出最终的定位框及类别标签数据。
(5)将最终的定位框及类别标签数据传输至计价程序。
(6)计价程序将最终的定位框及类别标签数据转换成菜品种类及数量,根据预先录入的菜价计算并显示菜品总价格。
在系统的数据库中储存有定位框及类别标签数据与具体的菜品种类、数量相对应的数据,当系统生成具体的定位框及类别标签数据时,就会生成对应的菜品种类及数量数据。
(7)客户通过支付系统完成付款,回到步骤(1)。
本发明的自主设计的efficientnet骨干网络(即图中的enet骨干网络)算法模型通过depthwiseconv和groupconv的有效组合,减少了参数量,提高了运算速度;为防止表达力减弱,首先通过两次shuffle提高了优质特征产生的几率,再通过channelattention机制,增强了优势特征,减弱了劣势特征。
两次shuffle(doublechannelshuffle):
如图3所示,假设有8个卷积通道,然后分成4组(相邻的两列为一组),每组分别进行卷积,如第二行所示,这样可以降低内存访问率,提高运算,但同时降低了产生优质特征的可能性,因此我们在卷积之前,将8个通道的排列顺序打乱,从而产生了更多的组合,也就提高了优质特征产生的可能性;同时我们在卷积完成后,又将8个通道的顺序打乱,然后结合channelattention对8个通道进行重新加权,作为最终的卷积特征输出。
channelattention机制:
参见图4,对一组通道分别用sigmoid函数进行求值,得到的数值可以看作是每个通道的权重,再利用这个权重与每个通道相乘,这一步相当于加权平均,从而提高优质通道的比重。
双向注意力机制即为channelattention机制在两个方向上的运算,如图2、图5均有体现,下两段文字中也有对于双向注意力机制的具体释义。
参见图5,特征金字塔网络(fpn)可以提升小物体检测的性能,我们在此基础上设计了ffwa(fastfpnwithattention),即利用uplayer的语义信息来监督downlayer的外观特征筛选,同时利用channelattention筛选每层特征,从而抽取优质特征;但fpn增加了模型运算量,我们利用efficientnet骨干网络,减低了参数量,保证了速度优势。图中每一方块指中间过程的特征。
ffwa(fastfpnwithattention):
向上运算过程,即正常的卷积运算;向下运算过程,先对本层卷积进行解卷积操作,生成与下层相同尺寸的通道,然后利用sigmoid进行求值,作为下层通道的权重,最后将下层卷积与这个权重相乘,得到这一层的输出。
下层卷积有更多的底层特征,而上层卷积有更多的语义特征,这样可以有效提高显著物体的检测,同时底层的特征,也有利于检测出更多的小物体,从而提高了整个检测过程中的召回率,避免漏检。
由于餐盘里的食物一直在变化,为模型识别餐盘增加了很大的困难,所以我们设计了自适应normalization来解决外观变化给餐盘识别带来的困难,主要是结合了batchnormalization和instancenormalization,然后分别与权重相乘,再把两种结果相加,由于batchnormalization对内容具有不变性,instancenormalization对外观具有不变性,所以结合两者并寻找一个平衡权重,可以很大程度上提高模型的泛化能力。
自适应normalization(自适应归一化):
bn(批归一化):对内容具有不变性,利于餐盘类别判断;in(实例归一化):对外观具有不变性,利于颜色、形状、大小等外观特征多变情况下的外观迁移。针对餐盘识别过程中食物多变、而餐盘不变的特性,结合这两种技术成为可行。结合方法:out=alpha*bn+beta*in。alpha和beta这两个参数,每次根据数据本身自动调整大小,得到一个最终的归一化结果,这样就有效结合了两者的优点。
由于餐盘间会有一定遮挡,使用普通的nms算法会导致后面的餐盘初步定位框被删掉,因此使用自适应的nms算法进行后处理,即soft-nms,在原nms算法函数基础上采用线性加权:
其中m为当前得分最大的定位框,nt为抑制阈值,si为sore。
得益于soft-nms,我们把不符合条件的候选框保留,并给予更小的得分,从而提高了检测遮挡物体的召回率,可以有效解决餐盘遮挡问题。
模型训练的过程中,会对部分餐盘识别效果不佳,我们改进了损失函数,让模型可以更好的学习这些困难案例的特征:
y=-(1-p)*log(x)
其中:x即模型输出,p即餐盘对应的概率,y即损失函数
经典的损失函数没有(1-p)这个因子,而我们添加的这个因子可以增大困难案例的损失,从而让模型更关注这些困难案例。
本发明的自动结算方法过程中,在步骤(1)通过单目摄像头采集所需餐盘的完整图像后,可以对图像进行简单预处理(滤波、降噪、白平衡、扭曲处理、放射变化等),以提升图像识别准确率。
本发明可在上述单目摄像头获取餐盘图像的同时,利用其它摄像头采集用户面部图像,将采集的面部图像与预先存储的用户图像进行对比以确认当前用户的账户信息。
- 还没有人留言评论。精彩留言会获得点赞!