一种基于自学习的方式建立纤维种类图谱库的方法与流程
本发明涉及纤维定性鉴别技术领域,具体涉及一种基于自学习的方式建立纤维种类图谱库的方法。
背景技术:
对于纺织品纤维种类的鉴别,目前主要采用化学方法对被检样品的纤维做定性的鉴别。化学方法的主要缺陷是,化学品对环境的污染和对检验人员的人体伤害。为了解决化学方法的污染问题,各种物理检验的方法被引进,譬如近红外图谱,紫外漫反射光谱,拉曼光谱等。但是在实际应用中,当得到了被检验纤维的图谱后,需要将其和已知的纤维种类标准图谱比对,从而确定被检验的纤维是什么种类的纤维。这就需要有一个涵盖所有纤维种类的纤维图谱库。就目前来说还没有一个可实际应用的纤维图谱库可以给纤维检验机构采用,用其来做纤维种类的定性鉴别。其困难的地方主要有以下几点:
·对于每种种类的纤维需要用不含杂质的纯纤维来采集其图谱,从而得到这种纤维种类的标准图谱;
·对于由不同纤维混合成纤维浆而生产出的混合纤维,由于不同纤维的混合比率无法穷尽,从而不可能对每种混合比率的纤维得到其相应的图谱;
·如果生产单位不提供新型纤维的图谱,那么这种新纤维的图谱检验机构无法得到,从而检验机构无法对其做定性检验。
有鉴于此,要靠单一家或几家检验机构或企业来建立涵盖全种类纤维的图谱库是不可能的。然而,通过对纤维图谱的比对来做纤维的定性检验离不开可用于比对的纤维种类图谱库。由此,如何建立一个在做纤维定性检验时能比对的可靠的纤维种类图谱库至关重要。
每种纤维在某种特定的图谱中都有其特定的特征,这奠定了可以通过物理方法来取得相应的图谱,从而用来辨别纤维种类的理论基础。例如,专利1(cn201510133888.0)记载了基于紫外漫反射光谱的纺织纤维的鉴别方法;专利2(cn101187635a)记载了一种基于拉曼光谱定性鉴别纺织纤维的方法;专利3(cn106706548a)记载了一种基于红外光谱曲线拟合分峰技术的聚酯纤维定性鉴别方法;文献1(应用可见/近红外光谱进行纺织纤维鉴别的研究,光谱学与光谱分析2010年2月第30卷,第2期)记载了应用可见或近红外光谱进行纺织纤维的鉴别技术。
无污染的物理纤维含量检测方法是纺织品质量检验技术的发展方向。为了取代化学法,对于基于图谱分析的检验方法的关键是需要有一个可以比对纤维种类的图谱库。但是,现有的纤维种类建库技术难以解决在短期内快速高效地建立涵盖所有纤维种类的图谱库的难题。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于自学习的方式建立纤维种类图谱库的方法,使用稀疏自编码神经网络模型对纤维图谱进行特征学习的方法(简称特征学习),得到纤维特征图谱,并以一定的相似度和图谱库中的图谱比对来确定被检纤维的纤维种类。
本发明应用一定的相似度进行检测,是因为纤维检验的标准都有一定的容错率,譬如国标aatcc-20a-2000。如果容错率是95%,那么也可以将其表述为被检纤维以95%以上的概率是某种纤维。也可以说被检纤维是某种纤维的相似度达到95%或以上时,其容错率可以满足95%。
对于一未知纤维种类,本发明提供一种大数据的方法,通过收集数据,而后对带标签的数据进行人工智能处理,从而对数据进行分类。具体的说,通过收集纤维图谱,利用收集的图谱所积累的知识(标签),当积累的图谱累积到一定的量时用深度自学习的方法来确定一新的纤维种类的方法。通过这种方法,可以解决在短期内无法涵盖所有纤维种类的难题。应用本发明的方法,检验机构或企业或互联网+纤维检验的机构可以在检验过程中积累所遇到的纤维种类的信息,或通过互联网广泛的从各种相关的地方收集纤维种类的图谱,从而确立纤维种类的名称及其特征的图谱。一旦建立了纤维种类的名称和其特征图谱,相关的检验机构就能扩大其检验能力。
本发明提供的技术方案的前提是:
1.同类型的检测设备(譬如近红外或红外、拉曼光谱仪等);
2.同类型的图谱图(譬如红外光谱图、热重图谱、拉曼光谱图)。
本发明提供的技术方案是:
一种基于自学习方法建立纤维种类图谱库的方法,采用同类型的检测设备(譬如近红外或红外、拉曼光谱仪等),针对同类型的纤维图谱图(譬如红外光谱图、热重图谱、拉曼光谱图),使用稀疏自编码神经网络模型,对纤维图谱进行特征学习,得到纤维特征图谱,并通过计算相似度,将待检测纤维与图谱库中的图谱进行比对,由此识别得到待检测纤维的纤维种类。如果待检纤维不是图谱库中的已知的种类,那么把此纤维收集在一个数据集中,当此数据集中收集的纤维数量达到一定量时,再通过深度学习的方法来确定一个新纤维种类。由此,该方法可用于进行纤维检测。
本发明提供的建立纤维种类图谱库的方法包括如下步骤:
1)采用稀疏线性神经网络模型作为深度学习图谱分类识别的稀疏编码神经网络模型(简称编码模型);
2)针对样本纤维图谱x,采用编码模型提取x的纤维特征,并经softmax分类器初步确定纤维的分类;
具体地,将样本纤维图谱x输入到编码模型中,提取其纤维特征向量,记为x。x表示为输入的2维特征向量(图谱),d为标准化的基础矩阵,简称为基,用于表示图谱中的波形。则x可以由d中少量元素d及其系数线性α组合而成。其一般表示为式1:
式1中,d1~dp分别表示基中的元素;α1~αp分别表示对应于di的权数;
3)如果编码模型的输出表明样本纤维图谱是一已知分类,记为r,则得到输出结果,结束操作;
4)如果编码模型的输出表明样本图谱是一未知分类,则将其归类于模型的未知分类;
5)对模型的未知分类进一步细分,把含有相同关键字(例如为abc)的图谱样本归在同一待定分类数据集。当一待定分类数据集中图谱的数据量达到y(预先设定阈值)数量值后,确定一个新的以关键字abc命名的纤维种类。其步骤如下;
51)随机从一待定分类集中取少量样本图谱,譬如10个样本图谱,作为初始比对样本。对所取少量样本的样本图谱进行预训练(步骤53)-55)),由此得到此待定分类的初始化特征向量;
52)随机从y张图谱中挑选n张图谱,一般n>200,y和n均为预设定值;设定的y取值即收集的带同样标签的图谱数量要达到的值,一般取大于200;
53)对n张图谱中的每张图谱,按照e*e的尺寸进行切割成小图片(掩模),e为常数,可预设定取值;本发明具体实施时,e取值为8;
54)从这些掩模中随机挑选一系列的样本图片(如表示为[x1x2…]),将图谱使用灰度均衡法对样本图片进行预处理,然后对像素信息进行归一化,通过rbm(受限玻尔兹曼机)学习机制得到一组初始化基[d1d2…];
55)确定目标优化函数以及样本的基;
其具体过程如下:
i.使用稀疏编码模型,需要系数α稀疏;在目标优化函数使用l1范数约束,目标优化函数(损失函数)表示为式3:
其中,α为稀疏系数/线性系数;αi,j是α中的元素;m为训练数据集中样本的个数、k为已知分类的个数,λ为常数可按经验来调整。
ii.通过对样本的训练学习,使得上述目标函数最小。该训练过程,是一个重复迭代过程,每次迭代按照以下步骤进行:
1)固定样本基di,调整αi,使得上式目标函数最小;
2)固定αi,调整di,使得上式目标函数最小;
iii.通过以上步骤的不断迭代,可以得到一组可以良好表达该系列样本的特征向量的基d;
56)进行稀疏编码,得到稀疏向量α。
给定一个新的图谱z,利用步骤55)训练阶段得到的基d,重复步骤53)-55).i的过程,便可以得到一个稀疏向量α,即线性系数,则该稀疏向量即为输入的图谱z的特征向量z的一个稀疏表达,也即为向量z在神经网络中的参数,记为hw,v(z),表达式为式4:
57)固定上述模型参数hw,v(z),这里w表示模型参数中的特征向量的权重,v表示权重衰减项。此模型参数作为训练完成后的模型参数,将用于对测试数据的识别和相似度计算;
58)对编码模型的softmax分类器进一步训练,
具体步骤如下:
i.用m个已知标记的训练样本组成训练样本:{(x(1),y(1)),..,{x(m),y(m)}},其中y(i)∈{1,2,...,k},用以标定k个不同的类别。例如,我们定义k=6种类别,分别为棉,麻,毛,丝,天丝及未知类别;
ii对于给定的测试输入r使用一个假设函数hθ(r)对每一类别j估算出概率值p(y=j|r),以此来估计r的每一种分类结果出现的概率。输入一个k维的向量(向量元素的总和为1)来表示这k个估计的概率值。假设函数hθ(r)的形式表示为式5:
其中,模型参数
t表示转置。
在softmax回归中将x分类为类别j的概率表示为式7:
因此,softmax分类器的损失函数(对类标记的k个可能值进行累加)表达式为式8:
其中,m为训练样本个数,k为已知分类数,x表示训练集元素,t表示转置;
iii.添加权重衰减项来修改损失函数,从而来惩罚数值过大的参数,设定衰减项为
其中,λ为常数,n为n维向量,log是以e为底的对数;
iv.对损失函数的最小化问题,采用最小梯度下降法进行。首先,对上式(式9)损失函数求导,可得梯度公式如式10:
然后,使用最小梯度下降法来最小化j(θ),在其标准实现中,在每次迭代过程中需要如下的参数更新:
这里θj表示元素第j次迭代的向量参数,α为因子,
v.重复上述迭代步骤(i-iv),优化softmax模型参数,以此训练得到一个优化的回归模型;
vi.更新已有的编码模型,也就是更新hw,v(z),此时新的编码模型含有新分类(如abc);
以此循环,建立得到纤维种类的图谱库。
具体地,利用本发明建立的纤维种类图谱库进行纤维检测的方法包括如下步骤:
1)设定确定一未知纤维(送检纤维)是某种纤维的相似度为a,数据集阈值y,累积增值阈值s;
2)得到送检纤维的纤维图谱;
3)针对得到的纤维图谱,用稀疏编码神经网络模型(简称编码模型)提取其特征,并初步确定纤维的分类;
4)确定送检纤维的种类,执行如下操作:
4.1.如果编码模型输出的分类是编码模型中的已知分类,记为r,则:
4.1.1.计算r与编码模型中所有已知分类之间的最大相似度,记为b,其相对应的分类是b;
4.1.2.如果b>=a,则可确定送检纤维是纤维种类b;
4.1.3.如果b<=a,则将送检纤维归类于编码模型的未知分类;
4.2.如果编码模型输出的分类是模型中的未知分类,则将送检纤维归类于稀疏编码神经网络模型(编码模型)的未知分类;
5)对编码模型的未知分类做进一步细分;
5.1.将含有相同关键字(例如含关键字abc)的图谱样本归于同一待定带标签的分类数据集;
5.2.如果某一带标签(例如含abc)的数据集中的数据数量达到预先设定阈值y,例如y=300,则通过编码模型对样本数据做训练学习,从而确定新的纤维种类abc;
6)对编码模型的已知分类做进一步的训练学习,以提高识别精确度;
6.1.如果已知分类的某一分类数据数量达到预先设定的累积增值的阈值s,例如s=3000,则通过编码模型对此分类数据做进一步地训练学习,从而提高分类的精确度,这里累积增值是指前一次总数量上增加的值
6.2.如果任何一个分类的数据量尚未达到累积增值的阈值,则进一步累积相应分类的数据。
通过上述步骤进行纤维检测,得到送检纤维的种类。
本发明依据预先设定的相似度,当被检纤维和一已知纤维的相似度大于等于预设相似度时,即可以以预先设定相似度或概率值确定被检纤维的种类。对纤维识别的神经网络自学习模型
(编码模型),本发明方法提供了一种渐进式的优化方法,也就是通过调节稀疏系数α来求解优化值。
与现有技术相比,本发明的有益效果是:
本发明提供一种基于自学习方法建立纤维种类数据库进行纤维检测的方法,采用同类型的检测设备,针对同类型的纤维图谱图如红外光谱图、热重图谱、拉曼光谱图,使用稀疏自编码神经网络模型,对纤维图谱进行特征学习,得到纤维特征图谱,并通过计算相似度,将待检测纤维与图谱数据库中的图谱进行比对,由此在一定的相似度下识别得到待检测纤维的纤维种类。本发明利用大数据人工智能的方法提供了一个可操作的实用的纤维建库和纤维检测方法,解决了应用纤维图谱来识别纤维种类的理论成果到可以实际应用的问题。
附图说明
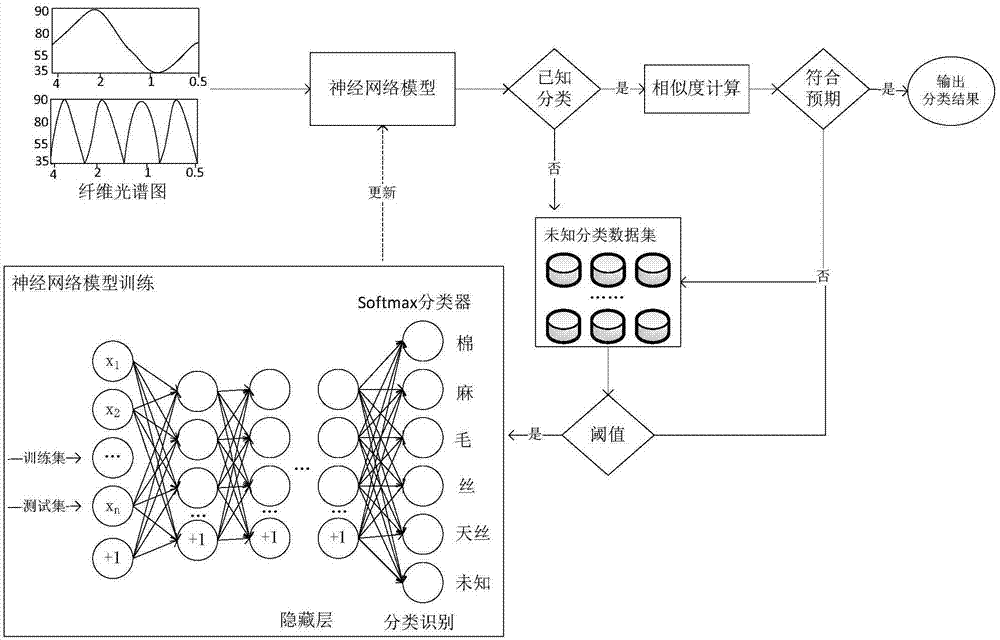
图1为本发明方法的检测步骤示意图。
图2为本发明方法的算法流程框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于自学习方法建立纤维种类图谱库进行纤维检测的方法,采用同类型的检测设备(譬如近红外或红外、拉曼光谱仪等),针对同类型的纤维图谱图(譬如红外光谱图、热重图谱、拉曼光谱图),使用稀疏自编码神经网络模型,对纤维图谱进行特征学习,得到纤维特征图谱,并通过计算相似度,将待检测纤维与图谱库中的图谱进行比对,由此识别得到待检测纤维的纤维种类。如果待检纤维不是图谱库中的已知的种类,那么把此纤维收集在一个数据集中,当数据集中收集的纤维数量达到一定量时,再通过深度学习的方法来确定一个新纤维种类。检测步骤如图1所示。
图2为本发明方法的流程框图。实施步骤如下:
1.采用基于深度学习图谱识别的稀疏编码神经网络模型(简称编码模型),这里的稀疏编码神经网络模型,采用稀疏线性模型;
2.针对送检纤维的样本纤维图谱x,采用编码模型提取其纤维特征,并经softmax分类器初步确定纤维的分类;
具体地,将样本图谱x输入到编码模型中,提取其纤维特征向量,记为x。x表示为输入的2维特征向量(图谱),d为标准化的基础矩阵,简称为基,用于表示图谱中的波形。则x可以由d中少量元素d及其系数线性α组合而成。其一般表示为式1:
式1中,d1~dp分别表示基中的元素;α1~αp分别表示对应于di的权数;
3.如果编码模型的输出表明样本图谱是一已知分类,记为r,则转到步骤7,对其进行相似度计算;
4.如果编码模型的输出表明样本图谱是一未知分类,则将其归类于模型的未知分类;
5.对模型的未知分类进一步细分,把含有相同关键字(例如为abc)的图谱样本归在同一待定分类数据集。当一待定分类数据集中图谱的数据量达到v(预先设定阈值)数量值后,确定一个新的以abc命名的纤维种类。其步骤如下;
5.1.随机从待定分类集中取少量样本图谱,譬如10个样本图谱,作为初始比对样本。对样本图谱进行预训练(5.3-5.5)得到此分类的初始化特征向量;
5.2.随机从y张图谱中挑选n张图谱,一般n>200,y和n均为预设定值;设定的y取值即收集的带同样标签的图谱数量要达到的值,一般取大于200;
5.3.对每张图谱按照e*e的尺寸进行切割成小图片(掩模),e为预设定值,一般e取值为8;
5.4.从这些掩模中随机挑选一系列的样本图片[x1x2…],将图谱使用灰度均衡法对样本图片进行预处理,然后对像素信息进行归一化,通过rbm(受限玻尔兹曼机)学习机制得到一组初始化基[d1d2…]
5.5.确定优化函数以及样本的基,其具体过程如下:
5.5.1.使用稀疏编码模型,需要系数α稀疏,为此,需在目标优化函数使用l1范数约束,因此目标优化函数(损失函数)表示为式3:
其中,m为训练数据集中样本的个数、k为已知分类的个数,λ为常数可按经验来调整,αi,j是α中的元素;
5.5.2通过对样本的训练学习,使得上述目标函数最小。该训练过程,是一个重复迭代过程,每次迭代按照以下步骤进行:
3)固定样本基di,调整αi,使得上式目标函数最小;
4)固定αi,调整di,使得上式目标函数最小;
5.5.3通过以上步骤的不断迭代,可以得到一组可以良好表达该系列样本x的基d;
5.6.进行稀疏编码。
通过给定一个新的图谱图片z并利用训练阶段得到的基d,然后重复5.3-5.5.1运算过程,便可以得到一个稀疏向量α,即线性系数,则该稀疏向量即为输入向量z的一个稀疏表达,也即为向量z在神经网络中的参数,记为hw,v(z),表达式为式4:
5.7.固定上述模型参数hw,v(z),这里w表示模型参数中的特征向量的权重,v表示权重衰减项。此模型参数作为训练完成后的模型参数,将用于对测试数据的识别和相似度计算;
5.8.对编码模型的softmax分类器进一步训练,具体步骤如下:
5.8.1.用m个已知标记的训练样本组成训练样本:{(x(1),y(1)),..,{x(m),y(m)}},其中y(i)∈{1,2,...,k},用以标定k各不同的类别。例如,我们定义k=6种类别,分别为棉,麻,毛,丝,天丝及未知类别;
5.8.2.对于给定的测试输入x,使用一个假设函数对每一类别j估算出概率值p(y=j|x),以此来估计x的每一种分类结果出现的概率。因此假设函数输入一个k维的向量(向量元素的总和为1)来表示这k个估计的概率值。假设函数hθ(x)的形式表示为式5:
其中,
在softmax回归中将x分类为类别j的概率为:
因此,softmax分类器的损失函数(对类标记的k个可能值进行累加)表达式为:
5.8.3.添加权重衰减项来修改损失函数,从而来惩罚数值过大的参数,设定衰减项为
5.8.4.对损失函数的最小化问题,采用最小梯度下降法进行。首先,对上式损失函数求导,可得梯度公式如下:
然后,使用最小梯度下降法来最小化j(θ),在其标准实现中,在每次迭代过程中需要如下的参数更新:
5.8.5.利用5.8.4中的迭代步骤重复进行来优化softmax模型参数,以此来训练出一个优化的回归模型
5.8.6.更新已有的编码模型,也就是更新hw,v(z),此时新编码模型含有新分类(abc):
6.以此循环建立起纤维种类的图谱库。
7.对已知分类进行相似度计算;具体执行如下操作:
7.1.与已知编码模型的定义的k种分类的特征向量进行相似度计算,采用特征向量的余弦相似度算法,已知的特征向量设为y,则计算公式为式2:
式2中,θsimilarity表示送检纤维与已知纤维特征向量的余弦相似度;θ表示是向量x与y的夹角;xi、yi分别表示向量x中的特征向量与向量y中的特征向量;
7.2.将计算得到的余弦相似度结果的最大值记为b,并将其相对应的分类记为b,通常b就是r;
7.3.在纤维种类图谱库中,预先设定相似度(概率)阈值为a,将得到的余弦相似度与阈值进行比较,即将送检纤维与已知纤维分类对比,从而确定送检纤维的种类;
7.3.1.如果b>=a,那么所检验的纤维按相似度a确定其种类为b,并把图谱样本归在此分类数据集中;
7.3.2.如果b<a,则将其归类于模型的未知分类。
8.如果某一已知分类的数据集里数据量达到累积增量s,s为预先按经验设定,则重复5.2-5.8的步骤,以进一步提高此分类的识别精确度。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!