基于多尺度池化的白细胞识别系统的制作方法
本发明涉及图像处理,深度学习,尤其涉及一种基于多尺度池化的白细胞识别系统。
背景技术:
随着计算机技术的显著发展,针对医学病理图像进行自动分析的图像处理算法也应用得越来越广泛。在医学图像分析中,白细胞的数量作为某些疾病的指征,对疾病诊断有着重要的临床意义。白细胞分割是对白细胞图像进行识别和计数的基本前提。白细胞分割问题的难点在于白细胞图像切片制作过程中,细胞的随机分布会在显微镜下形成细胞重叠或粘连。另外,由于实际图像的复杂性,如细胞大小不一致、细胞重叠、灰度变化等原因,都会影响分割算法的准确性,导致分割误差。
针对细胞分割问题,已经提出很多方法,例如基于阈值的分割方法,基于梯度的分割方法,基于颜色的分割方法,基于能量的分割方法。随着近几年深度神经网络的发展,卷积网络端到端的分割方法,渐渐出现在细胞分割领域。2015年,olafronnebergerde等人提出了u-net网络,大大改善了细胞分割准确度。之后assafarbelle等人提出了一种基于生成式对抗网络(gan)的分割方法。国内近几年也陆续提出了依托深度卷积网络的细胞分割方法。黄籽博等人提出了基于小波变换和形态分水岭的分割方法。曹贵宝提出了基于随机森林和卷积神经网络在神经细胞图像分割的方法。杨金鑫等人提出了结合卷积神经网络和超像素聚类的细胞图像分割方法。
本文也是依托深度网络快速的发展,借助这优秀的方法,在针对细胞紧邻的问题利用分水岭方法解决,针对细胞大小不一提出一种基于多处度池化层的卷积神经网络的分割系统。
技术实现要素:
本发明的目的针对细胞紧挨着,重叠,大小不一致等原因,很难分割的问题,提出了一种基于多尺度池化的端到端的卷积神经网络,并且利用分水岭算法后处理针对白细胞紧邻的细胞分割系统。
为了实现上述目的,本发明采用的技术方案是:
本发明公开了一种基于多尺度池化的神经网络的白细胞分割系统,具体的实现步骤如下:
(1)对样本库的细胞图片样本,进行预处理,得到训练样本和验证样本。
(2)利用(1)中得到的训练样本,依批次输入如图1的设计的神经网络,进行训练。采用以交叉熵为损失函数带动量的随机梯度下降法训练网络。得到训练好的网络。
(3)对测试图片按照如(1)中的预处理方式处理,得到处理后的测试图片。
(4)将(3)中得到的处理后的测试图片,利用(2)中训练好的网络,得到预测图片。
(5)对(4)中得到的预测图片,进行后处理,完成对测试图片的分割。
所述步骤(1)中的预处理步骤如下:
(11)对样本库中样本按照一定比例分为训练样本和验证样本,然后将训练样本和验证样本都进行数据增强,将每个样本进行旋转,翻转,随机下采样,形变,以及改变对比度,饱和度,光照,得到数据增强后的训练样本和验证样本,样本大小是512×512。
(12)对(11)中训练样本和验证样本图片对应的标签图片,使用(11)中一样的旋转,翻转,同样的下采样,形变,保证标签样本与训练样本或验证样本对应,得到数据增强后的标签样本,样本大小是512×512。
(13)用(11)中的数据增强后的训练样本和验证样本归一化,将(11)中大批训练样本减去样本本身的均值,实现归一化,得到可训练样本和验证样本。
所述步骤(2)中的构建深度神经网络及使用以交叉熵为损失函数带动量的随机梯度下降法进行优化的步骤如下:
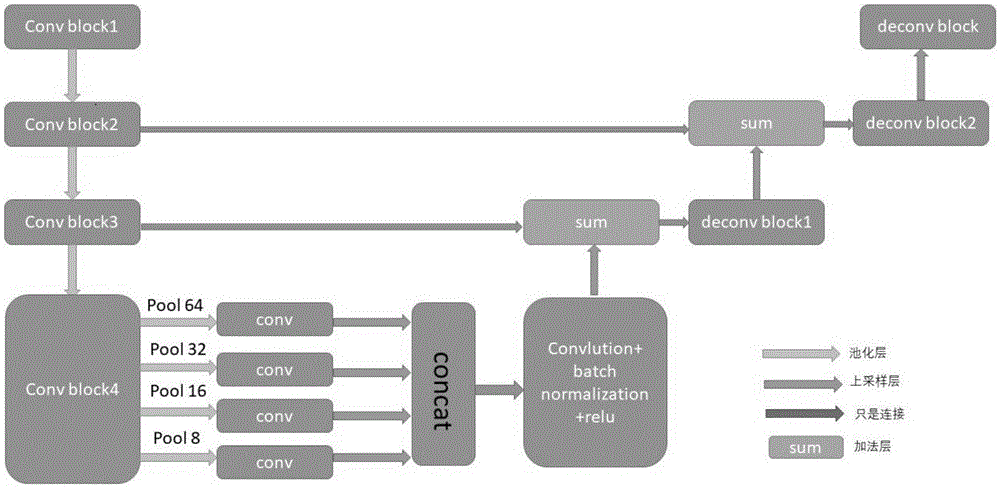
(21)构建一个如图1的深度网络,其中特征提取部分由四个卷积模块组成(图1中convblock),每个卷积模块由一个卷积层连接一个batchnormalization层连接一个修正线性单元(rectifiedlinerunit),再连接一个卷积层连接一个batchnormalization层连接一个修正线性单元(rectifiedlinerunit)组成。所有卷积均是采用padding是[1,1,1,1]的填充,卷积核都是3×3的。连接卷积模块的下采样是2×2的最大下采样。
(22)在(21)中特征提取网络部分的基础上,为了解决细胞大小不一的问题,使用多尺度池化层(poolinglayer)提取特征。这部分使用四种大小不一的池化,分别是64×64大小的平均池化,也就是全局池化,32×32大小的平均池化,16×16大小的平均池化,8×8大小的平均池化。之后都连接一层卷积层,然后都上采样到64×64大小尺度,再由连接层(concatlayer)全部连接。到这完成了全部特征的提取。
(23)将(22)中得到的特征,通过一个卷积层加一个batchnormalization层和修正线性单元的模块(如图convlution+batchnormalization+relu),得到融合后的特征。
(24)将(22)中得到的特征通过2×2大小的上采样和图中convblock3得到的特征相加。它们的权重是2:1,之后通过一个反卷积模块(图中deconvblock1)。该模块又反卷积,batchnormalization和修正线性单元组成。得到特征尺度为128×128的特征通道。
(25)将(24)中得到的特征通道进行如(24)中一样的步骤,得到特征尺度为256×256的特征通道。
(26)将(25)中得到的特征上采样后,进过一个反卷积模块最终得到特征尺度为512×512的特征通道。
(27)将(26)得到特征,使用使用softmax函数将概率图的值归一化到0到1,softmax函数如下:
(28)使用交叉熵函数为代价函数(cross-entropyloss)将(27)中得到的归一化的概率图与标签图对比,交叉熵代价函数如下:
为了防止过拟合,在代价函数后再加上一个l2正则项,得到的代价函数如下:
(29)得到(210)中代价函数值后,根据随机梯度下降法,反向传播,更新网络中参数的值。
(210)将验证样本依同样的方式输入网络,得到交叉熵代价函数的结果值,但不进行反向传播更新网络参数的值。
(211)将(212)中得到的验证样本的交叉熵代价函数的结果值,与(28)中训练样本的交叉熵代价函数的结果值进行对比,直到验证样本交叉熵代价函数的结果值不在下降,反而上升,而训练样本的交叉熵代价函数的结果值一直下降时,停止训练。以验证样本的交叉熵代价函数的结果值最小的一代网络为最终训练好的网络。
所述步骤(3)中的对测试样本的预处理的具体步骤如下:
(31)将测试样本进行最近邻采样得到大小一样的测试样本,样本大小是512×512。
(32)将(31)中的测试样本归一化,将(31)中大批训练样本减去样本本身的均值,实现归一化,得到可训练样本。
所述步骤(4)的输入网络预测具体步骤如下:
(41)将(32)中得到的测试样本输入已经训练好的网络得到预测标签图片,对于细胞分割图片,也就是二值图,其中0表示背景,1表示细胞。
所述步骤(5)的预测概率图的后处理具体步骤如下:
(51)将(41)中得到的预测标签图先进行填充操作,然后再删除小连通域。排除噪声(52)将(51)得到的处理后的标签图,进行分水岭算法,分水岭算法如下:
步骤(1)将(51)得到的处理后的二值图像,进行距离标记。也就是标记出所有点的位置到最近的值为0的点的位置的距离。
步骤(2)使用梯度幅度作为分割函数。也就是利用sobel梯度算子,计算出边界。
步骤(3)利用(1)中得到的距离图片,进行腐蚀膨胀,标记出前景,也就是细胞。
步骤(4)利用(51)中得到的处理后的二值图像,通过腐蚀膨胀,进行背景标记。
步骤(5)利用(2)(3)(4)得到的梯度图,前景标记图,背景标记图,使用分水岭变换,得到细胞分割图,得到的分割图,每个细胞使用不同灰度值标记。
附图说明
图1是神经网络结构图
具体实施方式
以下将结合附图所示的各实施方式对本发明进行详细描述
本发明公开了一种基于多尺度池化的深度学习的白细胞分割系统,具体实施步骤包括
(1)对样本库的细胞图片样本,进行预处理,得到训练样本和验证样本。
(2)利用(1)中得到的训练样本,依批次输入如图1的设计的神经网络,进行训练。采用以交叉熵为损失函数带动量的随机梯度下降法训练网络。得到训练好的网络。
(3)对测试图片按照如(1)中的预处理方式处理,得到处理后的测试图片。
(4)将(3)中得到的处理后的测试图片,利用(2)中训练好的网络,得到预测图片。
(5)对(4)中得到的预测图片,进行后处理,完成对测试图片的分割。
所述步骤(1)中的预处理步骤如下:
(11)对样本库中样本按照一定比例分为训练样本和验证样本,然后将训练样本和验证样本都进行数据增强,将每个样本进行旋转,翻转,随机下采样,形变,以及改变对比度,饱和度,光照,得到数据增强后的训练样本和验证样本,样本大小是512×512。
(12)对(11)中训练样本和验证样本图片对应的标签图片,使用(11)中一样的旋转,翻转,同样的下采样,形变,保证标签样本与训练样本或验证样本对应,得到数据增强后的标签样本,样本大小是512×512。
(13)用(11)中的数据增强后的训练样本和验证样本归一化,将(11)中大批训练样本减去样本本身的均值,实现归一化,得到可训练样本和验证样本。
所述步骤(2)中的构建深度神经网络及使用以交叉熵为损失函数带动量的随机梯度下降法进行优化的步骤如下:
(21)构建一个如图1的深度网络,其中特征提取部分由四个卷积模块组成(图1中convblock),每个卷积模块由一个卷积层连接一个batchnormalization层连接一个修正线性单元(rectifiedlinerunit),再连接一个卷积层连接一个batchnormalization层连接一个修正线性单元(rectifiedlinerunit)组成。所有卷积均是采用padding是[1,1,1,1]的填充,卷积核都是3×3的。连接卷积模块的下采样是2×2的最大下采样。
(22)在(21)中特征提取网络部分的基础上,为了解决细胞大小不一的问题,使用多尺度池化层(poolinglayer)提取特征。这部分使用四种大小不一的池化,分别是64×64大小的平均池化,也就是全局池化,32×32大小的平均池化,16×16大小的平均池化,8×8大小的平均池化。之后都连接一层卷积层,然后都上采样到64×64大小尺度,再由连接层(concatlayer)全部连接。到这完成了全部特征的提取。
(23)将(22)中得到的特征,通过一个卷积层加一个batchnormalization层和修正线性单元的模块(如图convlution+batchnormalization+relu),得到融合后的特征。
(24)将(22)中得到的特征通过2×2大小的上采样和图中convblock3得到的特征相加。它们的权重是2:1,之后通过一个反卷积模块(图中deconvblock1)。该模块又反卷积,batchnormalization和修正线性单元组成。得到特征尺度为128×128的特征通道。
(25)将(24)中得到的特征通道进行如(24)中一样的步骤,得到特征尺度为256×256的特征通道。
(26)将(25)中得到的特征上采样后,进过一个反卷积模块最终得到特征尺度为512×512的特征通道。
(27)将(26)得到特征,使用使用softmax函数将概率图的值归一化到0到1,softmax函数如下:
(28)使用交叉熵函数为代价函数(cross-entropyloss)将(27)中得到的归一化的概率图与标签图对比,交叉熵代价函数如下:
为了防止过拟合,在代价函数后再加上一个l2正则项,得到的代价函数如下:
(29)得到(210)中代价函数值后,根据随机梯度下降法,反向传播,更新网络中参数的值。
(210)将验证样本依同样的方式输入网络,得到交叉熵代价函数的结果值,但不进行反向传播更新网络参数的值。
(211)将(212)中得到的验证样本的交叉熵代价函数的结果值,与(28)中训练样本的交叉熵代价函数的结果值进行对比,直到验证样本交叉熵代价函数的结果值不在下降,反而上升,而训练样本的交叉熵代价函数的结果值一直下降时,停止训练。以验证样本的交叉熵代价函数的结果值最小的一代网络为最终训练好的网络。
所述步骤(3)中的对测试样本的预处理的具体步骤如下:
(31)将测试样本进行最近邻采样得到大小一样的测试样本,样本大小是512×512。
(32)将(31)中的测试样本归一化,将(31)中大批训练样本减去样本本身的均值,实现归一化,得到可训练样本。
所述步骤(4)的输入网络预测具体步骤如下:
(41)将(32)中得到的测试样本输入已经训练好的网络得到预测标签图片,对于细胞分割图片,也就是二值图,其中0表示背景,1表示细胞。
所述步骤(5)的预测概率图的后处理具体步骤如下:
(51)将(41)中得到的预测标签图先进行填充操作,然后再删除小连通域。排除噪声
(52)将(51)得到的处理后的标签图,进行分水岭算法,分水岭算法如下:
步骤(1)将(51)得到的处理后的二值图像,进行距离标记。也就是标记出所有点的位置到最近的值为0的点的位置的距离。
步骤(2)使用梯度幅度作为分割函数。也就是利用sobel梯度算子,计算出边界。
步骤(3)利用(1)中得到的距离图片,进行腐蚀膨胀,标记出前景,也就是细胞。
步骤(4)利用(51)中得到的处理后的二值图像,通过腐蚀膨胀,进行背景标记。
步骤(5)利用(2)(3)(4)得到的梯度图,前景标记图,背景标记图,使用分水岭变换,得到细胞分割图,得到的分割图,每个细胞使用不同灰度值标记。
- 还没有人留言评论。精彩留言会获得点赞!