一种基于深度强化学习的主动式视频行为检测系统及其方法与流程
本发明涉及视频行为分析技术领域,具体涉及到一种基于深度强化学习的主动式视频行为检测方法,该方法采用深度学习框架,利用强化学习算法来主动式产生行为提议,在此基础上完成视频行为分类和行为时间域定位。
背景技术:
视频行为检测是计算机视觉领域长期以来的一个研究热点,随着互联网用户上传视频量的爆炸式增长,近年来越来越多的学者开始关注这个课题。视频行为检测通常回答两个问题:1)what?是什么行为;2)when?在什么时间段发生。通常地说,目前存在的检测方法基本上都遵循一个两步走的检测方案:1)采用滑动窗口的方式,在视频多个位置处在多个时间尺度上利用一个行为/背景的二分类器产生超量的行为提议;2)用预训练的行为分类器对行为提议进行分类,同时采用一些后处理技术,比如:行为持续时间先验、非极大值抑制等,对行为提议的位置进行调整。这种方案虽然产生了不错的检测结果,但是当输入的视频序列持续时间较长时,会带来大量的计算开销,在实际的应用场景下是不可取的。同时由于行为提议和行为检测是分离的,模型各部分的优化是分段进行的,无法完成从端(视频输入)到端(结果输出)的全局下的优化训练。2016年,yeung等人(seranayeung,olgarussakovsky,gregmoriandlifei-fei,“endtoendlearningofactiondetectionfromglimpseinvideos”,ieeeconferenceoncomputervisionandpatternrecognition,pp.2678-2687),利用强化学习构建一种基于注意力机制的模型来实现输入视频中行为时间域定位。他们的模型通过在视频感兴趣区域间不断地进行跳跃观测来实现行为分类和行为起止时间点预测。这种模型的缺点在于行为时间域的定位是通过多次累积观测后直接给出的,而无法实现位置的逐步调整。
技术实现要素:
本发明的目的是提供一种基于深度强化学习的主动式视频行为检测方法,通过对输入视频多次累积的观测,逐步调整当前观测时间窗口的尺寸与位置,使之与行为发生的真实区域逐渐地重合,进而产生少量而优质的行为提议,同时对行为提议进行分类和位置校正,完成视频行为检测的任务。
本发明的另一目的是提供一种基于深度强化学习的主动式视频行为检测方法。
本发明提出的方法与现有的方法相比有两点主要的改进:1)本发明的方法基于深度强化学习产生行为提议,相比于传统的滑动窗口的方式,此方法可以产生少量而优质的行为提议,在很大程度上节省了运算量;2)本发明提出的模型可以进行端到端整体优化训练,相比于现有的两段式分离的方法,我们的模型训练起来更简单,模型的参数优化的更加充分。
本发明的原理是:1)构建深度强化学习模型来训练一个动作策略,使得模型根据对输入视频的累次观测结果,对当前关注的时间窗口的位置和尺寸进行调整,而此调整从有限步调整(例如,15步)长远的结果(例如,结果是关注的时间窗口与行为发生真实区域的交并比intersection-over-union)来看,是当前可以做出的最优选择;2)把行为提议、行为分类和位置调整模块放置在同一个模型中,构建一个多任务的网络结构,实现模型端到端整体的优化训练。
本发明提供的技术方案如下:
一种基于深度强化学习的主动式视频行为检测系统,包括视频序列深度特征提取模块、强化学习模型视频行为提议模块和视频行为检测模块;其中:所述视频序列深度特征提取模块,用于提取任意长度的视频序列深度表述特征;所述强化学习模型视频行为提议模块,用于对一段视频产生少量而优质的行为提议,且产生过程是主动探索式的;所述视频行为检测模块,用于对视频行为提议进行行为分类和行为位置确定。
所述视频序列深度特征提取模块具体包括:单帧图像特征提取网络,用于提取视频序列随机抽样产生的若干图像的深度表述特征;lstm时间序列网络,用于构建若干离散图像之间的时间关联关系,提取对一段视频序列的抽象表征。
所述强化学习模型视频行为提议模块具体包括:时间观测窗口和时间扩张窗口设置,用于提取强化学习模型当前观测内容及其上下文信息;观测窗口状态表述向量设置,用于联合表述当前窗口观测内容和其上下文信息,以及强化学习模型历史输出记录;强化学习网络设置,用于根据当前观测内容,在长期回报最大的情况下,给出当前最优的执行动作;强化学习模型执行动作集设置,用于规定对观测窗口可采取的可能的动作操作。
所述视频行为检测模块具体包括:行为检测网络,用于对强化学习模块产生的行为提议进行行为检测,得到行为分类得分和校正后的行为发生位置。
本发明提出的视频行为检测方法包括三个部分:对当前关注时间窗口和扩展时间窗口提取抽象特征表述;利用深度强化学习模型在输入视频中提取行为提议;利用多分类网络和位置回归网络对行为提议进行分类和位置调整。从一段视频输入到行为检测结果输出包括以下若干步骤(为了叙述的简洁,当前关注时间窗口以下简述为观测窗口,当前扩张时间窗口简述为扩张窗口)。本发明一种基于强化学习的主动式视频行为检测方法,包括以下步骤:
步骤1:根据待测视频,设置观测窗口和扩张窗口的初始位置;
步骤2:提取观测窗口和扩张窗口的特征表述;
步骤3:由深度强化学习模型对观测窗口的位置做一系列调整,得到动作候选区域;
步骤4:对动作候选区域进行排序,得到动作提议;
步骤5:利用行为检测网络对行为提议进行分类和位置校正,得到最终的检测结果。
与现有技术相比,本发明的有益效果是:
利用本发明提供的技术方案,在对视频中存在的行为进行检测时,采用一种主动搜索的方式来产生少量而优质的行为提议。相比于传统的滑动窗口的产生方法,节省了大量的计算开销,便于应用在对实时性要求比较高的场合;本发明中提出的模型可以进行端到端的整体优化训练,相比于现有的分段式的模型,提升了行为检测的准确性。
下面结合附图,通过实施例子对本发明进一步说明。
附图说明
图1为本发明的流程图;
图2为本发明所提出模型的网络结构图;
图3为深度强化学习模型所采用的动作指令集;
图4为观测和扩张窗口初始位置图。
附图中:
1—当前扩张窗口,2—当前观测窗口,3—cnn模块,4—lstm模块,5—历史操作记录表述,6—扩张窗口内容表述,7—观测窗口内容表述,8—dqn模块,9—动作指令得分输出,10—行为检测模块,11—分类结果输出,12—位置调整输出,13—分类和位置输出模块全连接层,14—dqn模块全连接层,15—转换动作指令集,16—右移指令,17—左移指令,18—右扩张指令,19—左扩张指令,20—收缩指令,21—跳跃指令,22—终止指令,23—终止动作指令集,24—初始观测窗口,25—初始扩张窗口,26—t=0时刻,27—给定视频v,28—t=lv时刻
具体实施方式
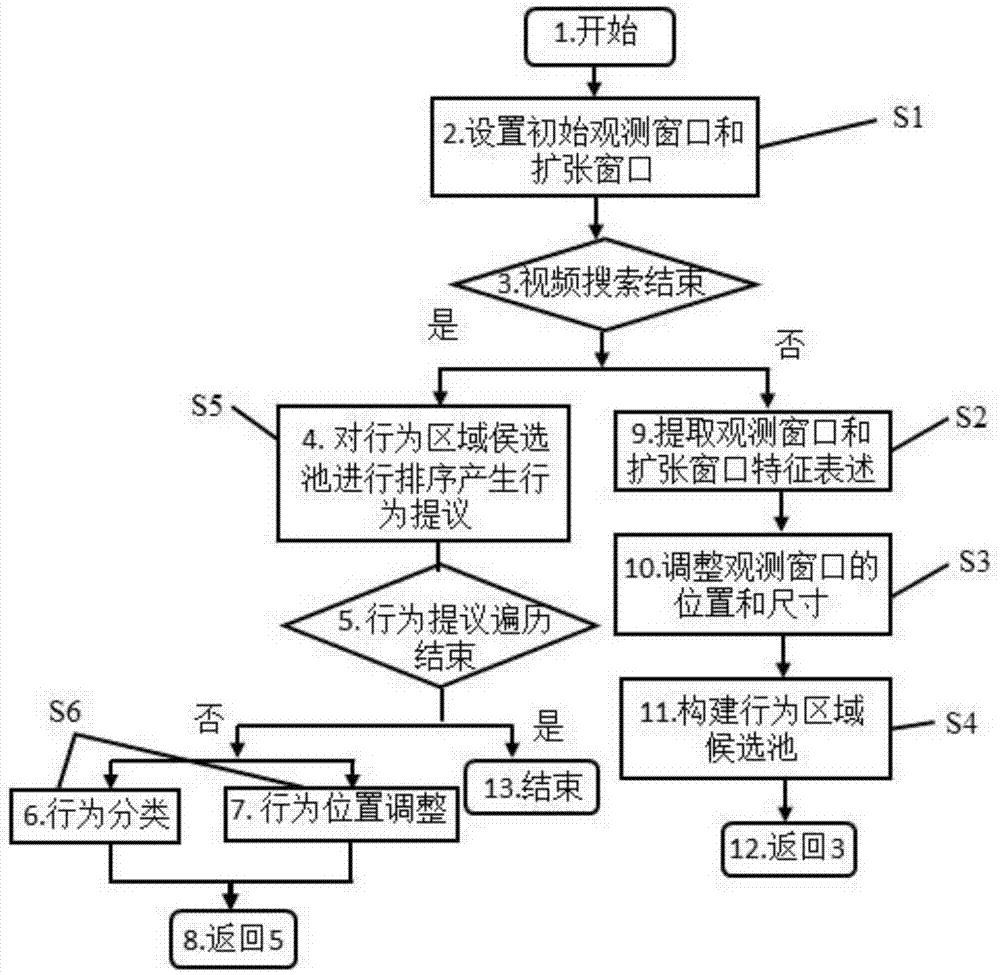
图1为本发明的流程图,其中s1—s6依次对应于具体实施步骤1)—6)。一种基于强化学习的主动式视频行为检测方法,其特征在于,包括以下步骤:
1)把观测窗口放置在视频开始处,窗口长度设置为行为平均持续长度。扩张窗口与观测窗口同位置,两端各向外延伸1/3窗口长度;
2)将观测窗口均匀划分为若干段,每段选取一帧图像,提取其convolutionalneuralnetwork(cnn)特征作为此段的表述。再将各段的表述依次输入到longshort-termmemory(lstm)模块中得到对整个观测窗口的表述。对扩张窗口采用同样的操作得到其表述。
3)根据当前观测结果(包括观测窗口和扩张窗口的表述)和历史操作记录(对观测窗口所做调整的历史记录),按照深度强化学习模型训练得到的动作执行策略,选择一个最优的执行动作对观测窗口的位置和尺寸进行调整,以此产生不同的动作候选区域;
4)按照得分值的高低对动作候选区域进行排序,得分值靠前的若干区域被选作为最终的动作提议;
5)利用多分类网络对动作提议进行分类,同时利用位置回归网络对动作提议的位置进行调整,进而得到最终的行为检测结果。
本发明的一种基于深度强化学习的主动式视频行为检测方法具体实施方式及整体操作流程现分述如下:
1)给定一个测试视频集,计算其中行为实例持续的平均时长,记为ld。观测和扩张窗口初始位置放置如附图4所示。给定一段测试视频v(图4中27),其持续时长记为lv(图4中28)。在v的开始处(即t=0时刻(图4中26)),放置一个观测窗口t(图4中24)和一个扩张窗口a(图4中25),两个窗口的中心位置重合。观测窗口长度为ld,扩张窗口左右边界由观测窗口两个边界向外各伸长
2)若观测窗口t尚未遍历搜索完整个视频v,则提取观测窗口t和扩张窗口a的特征表述。t和a的特征提取过程相同,以下以t为例进行说明。图2为本发明所提出的网络结构图,其中包括数据输入和特征提取部分。图2中1为当前扩张窗口a,2为当前观测窗口t。首先将t均匀划分为16段,从每段中随机抽取一帧图像,对这些图像用cnn模块(图2中3)提取其特征。在这里,我们使用vgg-16模型(simonyank.andzissermana.2014.verydeepconvolutionalnetworksforlargescaleimagerecognition.arxiv(2014).https://doi.org/arxiv:1409.1556),提取其fc6层特征pcnn。用pca降维模型将pcnn的维度从4096维降到1024维,记为p′cnn。然后将各段p′cnn依次输入到lstm模块(图2中4)中提取t的特征表述。lstm模块由一层构成,包含512个隐藏单元。lstm模块最后一个时间步(第16个时间步)隐含层输出作为t的特征表述,记为vt。同理可以得到a的特征表述,记为va。首先构建对观测窗口t的历史操作记录表述。对t的每次操作用一个7维向量来表述,每一维分量分别对应7个动作指令,0表示动作没有执行,1表示动作执行。7个动作指令如附图3所示,可划分为两组:图3中15是转换动作指令集,图3中23是终止动作指令集。转换动作指令集实现对t的位置和尺寸的操作,包括图3中16至图3中21。终止动作指令集停止当前搜索,包括图中22。将对t的最近5次操作进行联合表述,得到一个35维的向量,记为vh,作为历史操作记录表述。再将vt,va和vh连接起来,作为对t的状态表述,记为vs。随后把vs输入到深度强化学习模块dqn(图2中8),得到7个动作指令对应的得分值,根据最大得分值对应的动作对t的位置和尺寸进行调整。dqn包括3个全连接层(图2中14)和一个输出层(图2中9)。全连接层具有1024个隐单元,输出层具有7个输出。强化学习模块dqn(图2中9)的损失函数定义如下:
max1≤i≤nsign(iou(t′,gi)-iou(t,gi))(1)
其中n为当前视频中存在的行为实例个数,t′为t执行动作a后更新后的状态,gi代指行为实例,iou(t,gi)为观测窗口t和行为实例gi之间的交并比。sign(x)为示例函数,当x≥0,sign(x)取值为1;当x<0,sign(x)取值为-1。动作指令对t的位置和尺寸调整操作如下:右移和左移操作(图3中16和17)固定t的尺寸不变,位置移动距离为t长度的α倍;右扩张、左扩张和收缩操作(图3中18,19,20)固定t的位置不变,尺寸变化距离为t长度的α倍。跳跃操作(图3中21)固定t的尺寸不变,位置移动距离为t长度的β倍。这里取α=0.2,β=2。调整后的观测窗口t长度记为lt,固定t的位置不变,左右边界各向外延伸
4)将每轮搜索中观测窗口t所在的区域记录下来,构建行为区域侯选池p,同时记录t每次调整时终止操作(图3中22)所对应的得分值,作为对应行为区域的得分。
5)若观测窗口t已经遍历搜索完整个视频v,则开始构建行为提议。把p中的行为区域按照其得分从高到低进行排序,保留前200个行为区域作为对视频v产生的行为提议。
6)对行为提议进行遍历。若遍历结束,则对视频v行为检测结束。若遍历没结束,则对行为提议进行分类和位置调整。图2中10为行为检测模块,包括行为分类和位置调整网络。把对当前观测窗口t的特征表述vt输入到此网络中,经过两个全连接层(图2中13),最后输出行为分类结果(图2中11)和位置调整量(图2中12)。其中全连接层包括1024个隐藏单元,分类结果输出为在所有动作类别和背景类别上的得分,位置调整输出为观测窗口t中心位置和长度的相对偏差。行为分类结果(图2中11)的损失函数采用softmax多分类损失,计算如下:
lcls(u)=-logpu(2)
其中pu为当前行为属于动作类别u的概率。位置调整结果(图2中12)的损失函数计算如下:
lreg=|tu-tv|1
(3)
其中tu和tv分别为真实值和模型预测值,两者均为二元组{δc,δl}。设pi,,ci和li分别为行为提议及其中心位置和长度,
以上即为本发明提出的一种基于深度强化学习的主动式视频行为检测方法的具体实施方案。此实施例是在实际视频数据集thomas’14上进行的,并用目前公认的评价标准map(meanaverageprecision)对实验结果进行了评估。在iou(intersectionoverunion)为0.5时,本发明提出的方法都达到了目前领先的检测精度,与当前方法的比较如表1所示。
表1.与当前方法的对比
表1所比较的方法列举如下:
[1]d.oneata,j.verbeek,andc.schmid.actionandeventrecognitionwith
[2]yeungs.,russakovskyo.,morig.,andfei-feil.,end-to-endlearningofactiondetectionfromframeglimpsesinvideos.ieeeconferenceoncomputervisionandpatternrecognition(cvpr),pp.2678-2687,2016.
[3]shouz.,wangd.,andchangs.f.,temporalactionlocalizationinuntrimmedvideosviamulti-stagecnns.ieeeconferenceoncomputervisionandpatternrecognition(cvpr),pp.10491058,2016
[4]shou,z.;chan,j.;zareian,a.;miyazawa,k.;andchang,s.f.cdc:convolutional-deconvolutionalnetworksforprecisetemporalactionlocalizationinuntrimmedvideos,incomputervisionandpatternrecognition(cvpr),2017.
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!