一种基于深度特征和视频目标检测的安全帽佩戴检测方法与流程
本发明涉及一种基于深度特征和视频目标检测的安全帽佩戴检测方法,尤其涉及一种施工场景下的安全帽佩戴检测方法。
背景技术:
实际的施工场景下安全事故频发,造成大量的人员和财产损失。安全帽能够有效的保护施工人员的头部,特别是减少可能存在的高空坠物带来的伤害程度。施工人员是否安全帽检测以及后续的跟踪报警对于安全生产意义重大。在工地监控中,主要依靠人力观察监视画面或安排人员定期巡查来检测安全帽的佩戴情况,大规模工地需要相当数量的监控人员才能实现所有的监视画面或巡查较大的施工区域,存在严重的人力浪费,监控人员也会因为疲劳遗漏异常画面。因此,需要一个有效的低人力成本且结果准确的检测方法来发现施工人员未佩戴安全帽就上岗作业的现象并及时报警。
随着计算机视觉技术的不断发展,基于视频分析的安全帽检测也受到越来越多人的关注。经过检索,中国专利申请,申请号201610641223.5,公开日2017年1月4日,公开了一种基于视频分析的人员安全帽佩戴情况实时检测方法,首先从监测区域的摄像头中实时读取采集到的视频帧,然后对当前帧的图像利用检测器进行分类以识别人体上半身,定位检测到的人体目标的上半身最高点位置并以最高点为基准点提取相应的区域,最后根据颜色特征判断该图像区域的颜色从而判断被检测人员是否佩戴安全帽。另外,中国专利申请号201610778655.0,公开日2017年2月1日,通过训练人体位置模型提取安全帽所在区域,训练人头安全帽联合检测模型检测区域判断是否佩戴安全帽。现有的安全帽检测方法主要都是首先提取头部区域在设计不同的算法检测区域中是否含有安全帽,这类方法一定程度上能够降低背景环境对安全帽检测的影响,但是提取人体头部区域需花费较多的时间,影响了检测的实时性;基于安全帽颜色来判断是否佩戴安全帽,缺乏鲁棒性,不能适应复杂的环境。
技术实现要素:
针对以上问题,本发明提供了一种施工场景下基于视频的安全帽深度特征提取,施工场景下基于视频的不同颜色安全帽佩戴检测,施工场景下基于视频的安全帽检测实时性的基于深度特征和视频目标检测的安全帽佩戴检测方法。
为了以上问题,本发明采用了如下技术方案:一种基于深度特征和视频目标检测的安全帽佩戴检测方法,其特征在于,包括以下步骤:
step1视频数据采集
基于施工现场摄像头采集的mp4格式的视频数据实现,数据采集的对象是施工现场佩戴或未佩戴安全帽的工作人员;
step2数据标注
针对step1采集的数据进行人工标注;人工将输入视频每一帧中的安全帽通过最小外接矩形标出,记录该图像在视频序列中的帧号,记录框中目标的类别(如安全帽),记录图片中最小外接矩形的左上角和右下角坐标;数据记录标注的格式与pascalvoc格式相同;
step3数据集准备
将原始视频按7:1:2的比例随机划分为训练集、测试集和验证集,以step2中对应视频的标注图像数据分别替换训练集、测试集和验证集中的视频,替换时使用视频对应的所有标注视频帧替换原视频;最后的数据集组成包括划分后的训练集、测试集以及验证集,每一个集合中包含的是原始视频对应的图片,特别的训练集和验证集还包含每一张图片对应的标注数据;
step4网络构建和训练
step4-1特征提取
如果对视频中的每一帧都提取特征进行检测,时间上的开销是巨大的;视频中的连续帧内容是高度相关的,在卷积神经网络特征图中这种相似性表现的更明显,因此只对输入视频中的关键帧提取特征,将关键帧提取的特征传递给不同的相邻帧;
step4-2特征映射
直接复用和传递关键帧的特征信息给相邻帧,虽然会提高速度但是最终的检测精度损失严重,因此利用光流将关键帧特征传递并复用给当前帧的特征;
step4-3目标分类和位置框预测
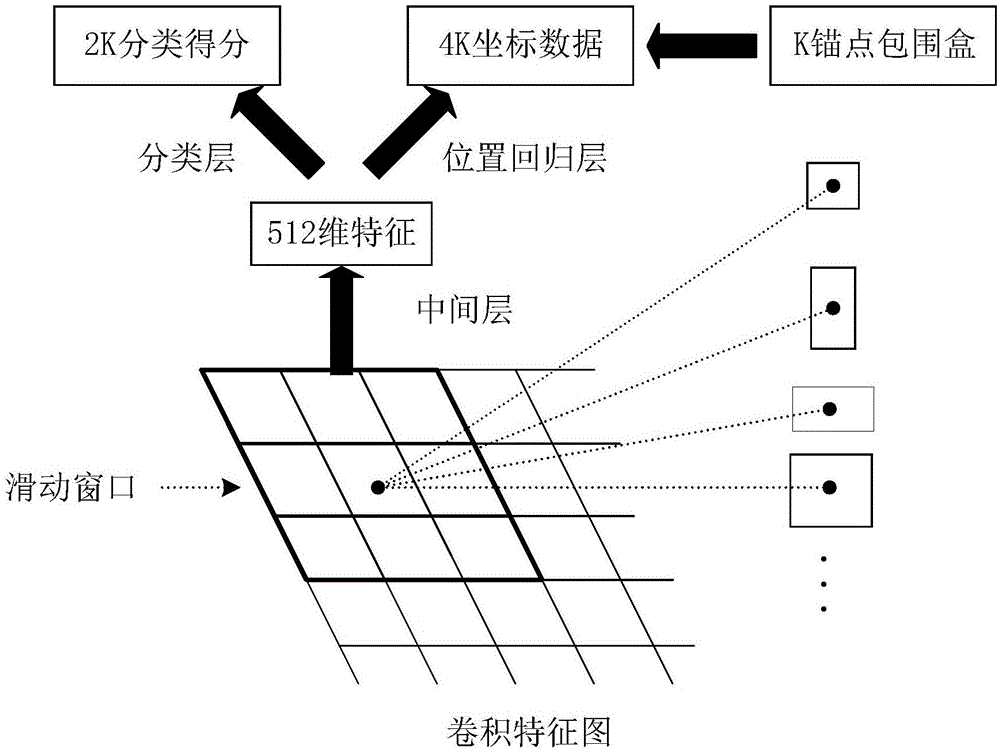
对于step4-1提取的特征,使用区域建议网络(regionproposalnetwork,rpn)生成候选区域,区域建议网络是一个全卷积网络,使用大小为3*3的卷积核遍历(滑动步长为1)提取的特征图。为每个滑动窗口的中心设计9种长宽组合,相应的产生9个大概率含有目标的预测框。使用2次卷积核大小为1*1,滑动步长为1的卷积操作来实现全连接,训练回归模型预测目标位置,训练分类模型判别目标类别。对于k个特征点,最终输出得到2k(背景+目标两类)个分类概率,4k个坐标数据(矩形框左上角顶点x,y坐标以及矩形框的长和宽);在此基础上使用基于区域的全卷积网络检测物体(region-basedfullyconvolutionalnetworks,r-fcn)对候选区域进行分类;r-fcn最后1个卷积层输出从整幅图像的卷积响应图像中分割出的感兴趣区域的卷积响应图像,即对r-fcn的卷积响应图像按rpn的结果分割出来感兴趣区域;将单通道的感兴趣区域分成k×k的网格,对每个网格平均池化,然后所有通道再平均池化;在整幅图像上为每类生成k2(k2对应描述位置的空间网格数)个位置敏感分数图;对于待识别的物体类别数c外加1个背景,因此共有k2(c+1)个通道的输出层。
step4-4网络训练
每个感兴趣区域的损失函数为交叉熵损失与边界框回归损失的和,计算方法如公式(6)所示:
其中,λ表示一个加权平均参数,s表示所有感兴趣区域的分类得分,
所述的step4-1特征提取的主要流程为:(1)判断输入视频流中当前帧是否为关键帧(视频中目标动作的转折帧就是关键帧,一般取一个动作的起始和结束位置作为关键帧,其他的连接转折动作的的帧就是中间帧);(2)若为关键帧,则将关键帧送入特征提取网络中提取关键帧的特征(2)如果不是,则复用当前帧的前一个关键帧的特征,特征复用的方法是将前一个关键帧的特征传递给当前帧,将当前帧前一个关键帧的特征作为当前帧的特征;(3)将每一帧(输入视频的全部视频帧)的特征传送到目标检测网络进行类别判别和目标位置预测。所述step4-2特征映射的主要流程如下:step4-2-1光流计算:对应的二维流场mi→k中(即当前帧i到关键帧k),对于特征点p的映射描述为变化量δp,即p→p+δp(箭头表示映射,该式表示关键帧的特征点p映射到当前帧的特征点p+δp);利用flownet(flownet:learningopticalflowwithconvolutionalnetwork)计算当前帧i到i前一个关键帧k的光流δp,计算方法如公式(1)所示:
mi→k=f(ik,ii),δp=mi→k(p)(1)
其中,ii表示当前帧,ik表示当前帧的前一个关键帧。
step4-2-2当前帧特征图计算:对于当前帧i的特征图,特征图上的每一个特征点p,如表述的值,都对应于关键帧k的特征图上的p+δp的值;通过双线性插值计算得到关键帧k上δp的值,即对于p+δp周围的四个整数点像素值进行插值计算,如公式(2)所示:
其中,c表示特征图f的通道数,i和k分别表示当前帧和关键帧,δp表示关键帧k特征图上位置p(对应x和y两个坐标值)到当前帧i的对应位置的光流,q(对应x和y两个坐标值)表示当前帧i上对于关键帧位置p对应的位置q,g表示双线性插值的内核,g分为两个一维内核g,如公式(3)所示:
其中,g表示g对应的一维内核,a和b分别表示g输入的两个参数,qx表示当前帧i上对于关键帧位置p对应的位置q的x坐标值,px表示当前帧i上位置p的x坐标值,
所述step4-3目标分类和位置框预测具体操作如下:对1个宽和长分别为w和h的感兴趣区域,将单通道的感兴趣区域分成k×k的网格,定义一个bin的大小为
其中,rc(i,j|θ)为第c类第(i,j)个bin的池化响应,zi,j,c为k2(c+1)个分数图中的输出,(x0,y0)感兴趣区域的左上角坐标,n为bin中的像素总数,且θ为网络的参数;
对于感兴趣区域每类的所有相对空间位置的分数平均池化使用softmax回归分类,计算方法如公式(5)所示,其中rc(i,j|θ)为第c类第(i,j)个bin的池化响应:
rcθ=∑i,jrc(i,j|θ)(5)
在k2(c+1)维的卷积层后,增加1个4*k2维的卷积层来回归边界框实现位置框的预测,最终输出1个4维向量(tx,ty,tw,th),其中tx,ty分别表示预测框左上角顶点的坐标,tw,th分别表示预测框的宽和长。
本发明与现有技术相对,具有以下有益效果:本发明通过卷积神经网络提取视频中安全帽的深度高维特征,实现了施工场景下基于视频流的安全帽的有效特征表示。本发明基于视频流中相邻帧之间的上下文信息,安全帽的有效特征表示对于颜色信息有较好的延拓性,能够实现施工场景下基于视频的不同颜色安全帽佩戴检测。本发明只对关键帧进行特征提取,避免了对冗余帧的特征提取,实现了特征图在帧间的传递和复用,大大提高了特征提取和目标检测花费的时间,实现了施工场景下基于监控视频的安全帽佩戴情况实施检测。
附图说明
图1为rpn网络结构示意图。
具体实施方式
以真实施工现场的安全帽佩戴情况检查为例,具体的实施方式如下所述:
硬件设备:
a.摄像头(品牌:萤石型号:cs-c3wn)
b.处理平台
处理平台为amax的psc-hb1x深度学习工作站,处理器为inter(r)e5-2600v3,主频为2.1ghz,内存为128gb,硬盘大小为1tb,显卡型号为geforcegtxtitanx。运行环境为:ubuntu16.0.4,python2.7。或其他的性能相当的计算机。
step1视频数据采集
本方法基于施工现场摄像头采集的mp4格式的视频数据实现,摄像头距离地面约3米,摄像机镜头与水平面夹角约为45度。截取获取视频中包含佩戴安全帽施工人员的部分,保证施工人员处于视频画面中间且整体画面相对清晰。
step2数据标注
针对step1采集的数据进行人工标注。人工将输入视频每一帧中的安全帽通过最小外接矩形标出,记录该图像在视频序列中的帧号,记录框中目标的类别(如安全帽),记录图片中最小外接矩形的左上角和右下角坐标。数据记录标注的格式与pascalvoc格式相同。
step3数据集准备
针对采集的原始视频,按7:1:2的比例随机选取其中415段用于训练,61段用于验证,124段用于测试。以步骤2中对应视频的标注图像数据分别替换训练集、测试集和验证集中的视频,替换规则为使用某视频对应的所有标注视频帧替换数据集中的该视频。最后的数据集组成包括划分后的训练集、测试集以及验证集,每一个集合中包含的是原始视频对应的标注图片,特别的训练集和验证集还包含图片对应的标注信息。保证最终数据集格式与ilsvrc2015-vid数据集一致。
step4网络构建和训练
step4-1特征提取
对输入视频中的关键帧提取特征,将关键帧提取的特征传递给不同的相邻帧;
特征提取的主要流程为:(1)判断输入视频流中当前帧是否为关键帧;(2)若为关键帧,则将关键帧送入特征提取网络中提取关键帧的特征(2)如果不是,则复用当前帧的前一个关键帧的特征,特征复用的方法是将前一个关键帧的特征传递给当前帧,将当前帧前一个关键帧的特征作为当前帧的特征;(3)将每一帧的特征传送到目标检测网络进行类别判别和目标位置预测。
step4-2特征映射
利用光流将关键帧特征传递并复用给当前帧的特征;
特征映射的主要流程如下:
step4-2-1光流计算:对应的二维流场mi→k中(即当前帧i到关键帧k),对于特征点p的映射描述为变化量δp,即p→p+δp(箭头表示映射,该式表示关键帧的特征点p映射到当前帧的特征点p+δp);利用flownet(flownet:learningopticalflowwithconvolutionalnetwork)计算当前帧i到i前一个关键帧k的光流δp,计算方法如公式(1)所示:
mi→k=f(ik,ii),δp=mi→k(p)(1)
其中,ii表示当前帧,ik表示当前帧的前一个关键帧;
step4-2-2当前帧特征图计算:对于当前帧i的特征图,特征图上的每一个特征点p,如表述的值,都对应于关键帧k的特征图上的p+δp的值;通过双线性插值计算得到关键帧k上δp的值,即对于p+δp周围的四个整数点像素值进行插值计算,如公式(2)所示:
其中,c表示特征图f的通道数,i和k分别表示当前帧和关键帧,δp表示关键帧k特征图上位置p(对应x和y两个坐标值)到当前帧i的对应位置的光流,q(对应x和y两个坐标值)表示当前帧i上对于关键帧位置p对应的位置q,g表示双线性插值的内核,g分为两个一维内核g,如公式(3)所示:
其中,g表示g对应的一维内核,a和b分别表示g输入的两个参数,qx表示当前帧i上对于关键帧位置p对应的位置q的x坐标值,px表示当前帧i上位置p的x坐标值,
step4-3目标分类和位置框预测
对于step4-1提取的特征,使用区域建议网络(regionproposalnetwork,rpn)生成候选区域,rpn网络结构如图1所示(区域建议网络是一个全卷积网络,使用大小为3*3的卷积核遍历(滑动步长为1)提取的特征图。为每个滑动窗口的中心设计9种长宽组合,相应的产生9个大概率含有目标的预测框。使用2次卷积核大小为1*1,滑动步长为1的卷积操作来实现全连接,训练回归模型预测目标位置,训练分类模型判别目标类别。对于k个特征点,最终输出得到2k(背景+目标两类)个分类概率,4k个坐标数据(矩形框左上角顶点x,y坐标以及矩形框的长和宽。)。在此基础上使用基于区域的全卷积网络检测物体(region-basedfullyconvolutionalnetworks,r-fcn)对候选区域进行分类;r-fcn最后1个卷积层输出从整幅图像的卷积响应图像中分割出的感兴趣区域的卷积响应图像,即对r-fcn的卷积响应图像按rpn的结果分割出来感兴趣区域;将单通道的感兴趣区域分成k×k的网格,对每个网格平均池化,然后所有通道再平均池化;在整幅图像上为每类生成k2(k2对应描述位置的空间网格数)个位置敏感分数图;对于待识别的物体类别数c外加1个背景,因此共有k2(c+1)个通道的输出层。
具体操作如下:对1个宽和长分别为w和h的感兴趣区域,将单通道的感兴趣区域分成k×k的网格,定义一个bin的大小为
其中,rc(i,j|θ)为第c类第(i,j)个bin的池化响应,zi,j,c为k2(c+1)个分数图中的输出,(x0,y0)感兴趣区域的左上角坐标,n为bin中的像素总数,且θ为网络的参数;
对于感兴趣区域每类的所有相对空间位置的分数平均池化使用softmax回归分类,计算方法如公式(5)所示,其中rc(i,j|θ)为第c类第(i,j)个bin的池化响应:
rcθ=∑i,jrc(i,j|θ)(5)
在k2(c+1)维的卷积层后,增加1个4*k2维的卷积层来回归边界框实现位置框的预测,最终输出1个4维向量(tx,ty,tw,th),其中tx,ty分别表示预测框左上角顶点的坐标,tw,th分别表示预测框的宽和长。
step4-4网络训练
每个感兴趣区域的损失函数为交叉熵损失与边界框回归损失的和,计算方法如公式(6)所示:
其中,λ表示一个加权平均参数,s表示所有感兴趣区域的分类得分,
在实际的实施中,通过编写和部署代码,上述的网络构建的4个分步骤已被融合在一个端到端的网络中,即输入训练数据集将自动进行特征提取、特征映射、分类和位置框预测。
将网络部署在b所述的服务器上。网络训练中首先需要调整网络参数,主要包括修改类别信息为待识别和定位的安全帽(hat),修改网络的预测框类别置信度阈值为0.4,修改预测框大小的最小值为16*16(像素),其余的网络超参数保持默认值。
在训练过程中,对于所有的训练样本首先提取关键帧的特征图,对于非关键帧进行特征复用和特征映射,具体的方法如公式(2)所示。对于提取的特征,使用区域建议网络(regionproposalnetwork,rpn)生成候选区域,在此基础上使用基于区域的全卷积网络检测物体(region-basedfullyconvolutionalnetworks,r-fcn)对候选区域进行分类(公式4),并输出预测框的位置信息。在训练的过程中联合类别损失和预测框偏移损失作为训练的目标损失函数(公式6)。基于上述完整的一次计算过程完成一次训练,当训练次数达到预定阈值或者损失小于预定阈值训练结束。
step5模型测试
在运行测试代码前,修改测试文件代码中的标签信息存放路径、修改训练完成的安全帽检测模型存放路径、修改测试视频的存放路径,上述路径均依据自身对应数据的存放地址来修改和确定。
测试时输入待检测样本视频,输出为视频中待检测安全帽的类别信息(hat)和定位结果(最小外接矩形预测框的坐标信息),并最终测试视频中可视化的展现出安全帽的预测位置框。
以上所述仅为本发明的优选实施例而已,并不限制于本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!