一种网页截图系统和方法与流程
本发明涉及网页截图技术领域,具体为一种网页截图系统和方法。
背景技术:
现有的网页截图方案大多数采用客户端截图工具的方式,如使用电脑自带的屏幕截图工具、腾讯公司的qq截图工具。这些方式通常需要人工进行截图分辨率的操作,效率低且不精准。而且不具备与服务端交互的功能。
现有技术中,安装客户端截图工具或浏览器插件,对需要截图的区域进行人工截图操作,调整窗口大小,再保存到本地。但现有的截图工具软件仅能对展现在客户端的显示屏幕上的网页部分进行截图操作,而无法实现在整个网页页面内的截图操作;同时人工截图操作繁琐,当有批量截图需求时,这种技术方案的效率很低;而且缺少与服务端通信的机制,当需要将图片提供给用户浏览时,还需要上传到图片服务器。
因此需要一种方法,能够模拟浏览器行为进行截图操作,并实现程序与服务端交互的功能。
术语解释:
puppeteer:是googlechrome团队官方的无界面(headless)chrome工具,它是一个node库,提供了一个高级的api来控制devtools协议上的无头版chrome。也可以配置为使用完整(非无头)的chrome。
express:是一种保持最低程度规模的灵活node.jsweb应用程序框架,为web和移动应用程序提供一组强大的功能。
api:应用程序接口(英语:applicationprogramminginterface,简称:api),又称为应用编程接口,就是软件系统不同组成部分衔接的约定。
技术实现要素:
针对上述问题,本发明的目的在于提供一种能够实现服务端网页截图api功能,用户不需要下载任何客户端截图工具就可以实现网页截图的系统和方法。技术方案如下:
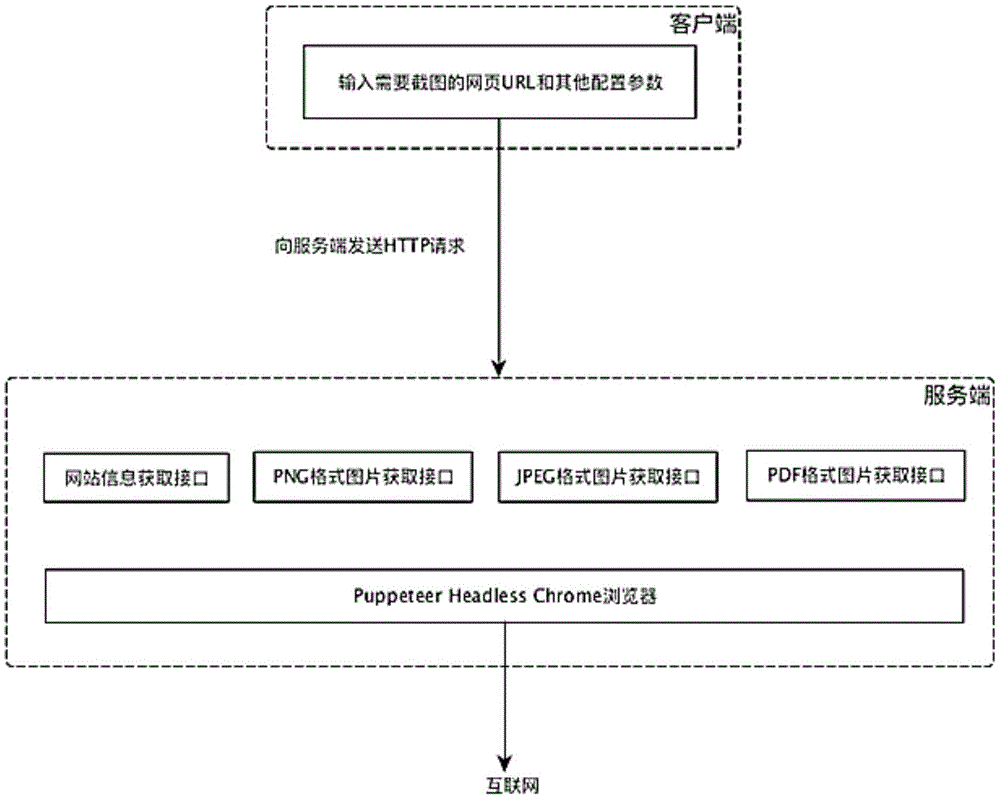
一种网页截图系统,包括客户端和服务端;
客户端用于供用户输入需要截图的网页url和其他配置参数,并通过网页浏览器、命令行工具或编程语言程序的方式向服务端api接口发送http请求;
服务端设置有网络信息获取接口、图片获取接口和puppteer无头浏览器;
服务端接受客户端发送过来的参数,通过puppteer无头浏览器访问互联网,在各个接口模块中,将返回的结果通过puppteer无头浏览器中的内置方法进行数据处理,最后将数据返回给客户端。
进一步的,所述图片获取接口包括png格式图片获取接口、jpeg格式图片获取接口和pdf格式图片获取接口。
一种网页截图方法,包括以下步骤:
步骤1:用户从客户端输入需要截图的网页url和其他配置参数;
步骤2:客户端通过网页浏览器、命令行工具或编程语言程序方式向服务端api接口发送
http请求;
步骤3:服务端接受客户端发送过来的http请求中的参数,通过puppteer无头浏览器访
问请求截图的网址;
步骤4:在服务端的四个接口模块中,将返回的结果通过puppteer无头浏览器中的内置方
法进行数据处理;
步骤5:通过web框架express封装这四个接口,提供服务端api,用户或程序通过访问这些api接口获取网站的截图信息更进一步的,。
更进一步的,所述http请求中的参数包括:需要访问的网页地址、像素值长宽、请求头、是否截取整个页面的标记。
更进一步的,所述步骤4具体为:
服务端的网站信息获取接口通过调用puppeteer无头浏览器内置的page.title()方法,获取网站的标题,通过正则表达式获取网站的描述,通过page.screenshot()获取网页截图,将获取的截图通过转码,以json格式返回网站标题、网站描述、base64后的网页截图图片信息;
png格式图片获取接口通过调用page.screenshot()方法获取网页截图,直接返回png格式图片;
jpeg格式图片获取接口通过调用page.screenshot()方法获取网页截图,直接返回jpeg格式图片;
pdf格式图片获取接口通过调用page.pdf()方法获取网页pdf截图,直接返回pdf格式图片。
本发明的有益效果是:本发明通过对headlesschromenodeapi—puppeteer进行封装,实现服务端网页截图api功能,用户不需要下载任何客户端截图工具就可以实现网页截图;通过api进行截图操作,可以有效的与其他程序进行交互,达到自动化批量截图的目的;还可以通过传入参数,达到全屏幕或固定长宽的截图效果。
附图说明
图1为本发明网页截图系统的结构示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细说明。如图1所示,本发明的网页截图系统,包括客户端和服务端。
其中,客户端用于供用户输入需要截图的网页url和其他配置参数,并通过网页浏览器、命令行工具或编程语言程序的方式向服务端api接口发送http请求。
服务端可以部署在任意服务器上(linux,windows等),如本机http://localhost:8000。服务端设置有网络信息获取接口、png格式图片获取接口、jpeg格式图片获取接口、pdf格式图片获取接口和puppteer无头浏览器;服务端接受客户端发送过来的参数,通过puppteer无头浏览器访问互联网,在各个接口模块中,将返回的结果通过puppteer无头浏览器中的内置方法进行数据处理,最后将数据返回给客户端。
本网页截图方法的步骤流程如下:
步骤1:用户从客户端输入需要截图的网页url和其他配置参数。
步骤2:客户端通过网页浏览器、命令行工具或编程语言程序方式向服务端api接口发送http请求。
步骤3:服务端接受客户端发送过来的http请求中的参数,通过puppteer无头浏览器访问请求截图的网址。
各个api接口所需要的参数:
url:需要访问的网页地址,如需要截取百度网站,则url是https://baidu.com
viewport:像素值长宽{“width”:720,“height”:1280}
headers:请求头
fullpage:是否截取整个页面,可选值1或0。
步骤4:在服务端的四个接口模块中,将返回的结果通过puppteer无头浏览器中的内置方法进行数据处理。
当接口接受到参数时,通过无头浏览器puppeteer访问参数url提供的地址。将返回页面对象交给各个接口处理:
1)网站信息获取接口(/info):通过调用puppeteer内置的page.title()方法,获取网站的标题,通过正则表达式page.$x(‘/html/head/meta[@name="description"]/@content’)获取网站的描述,通过page.screenshot()获取网页截图,将获取的截图通过pic.tostring('base64')转码,以json格式返回网站标题、网站描述、base64后的网页截图图片信息。
2)png格式图片获取接口(/png):通过调用page.screenshot()方法获取网页截图,直接返回png格式图片。
3)jpeg格式图片获取接口(/jepg):通过调用page.screenshot()方法获取网页截图,直接返回jpeg格式图片。
4)pdf格式图片获取接口(/pdf):通过调用page.pdf()方法获取网页pdf截图,直接返回pdf格式图片。
步骤5:通过web框架express封装这四个接口,提供服务端api,用户或程序通过访问这些api接口获取网站的截图信息。
例如通过访问http://localhost:8000/info?url=http://example.com可以获取网站example.com的首页标题,描述,base64后的图片信息;
访问http://localhost:8000/png?url=http://example.com可以获取example.com网站的png截图。
访问http://localhost:8000/png?url=http://example.com&fullpage=true可以获取example.com网站全屏幕的png截图。
- 还没有人留言评论。精彩留言会获得点赞!