一种基于稠密图的视频分类方法和系统与流程
本发明涉及计算机视觉与模式识别领域,并特别涉及一种基于稠密图的视频分类方法和系统。
背景技术:
目前主流的动作识别方法主要为双流法和3维卷积方法。双流卷积网络方法中,分为了空间流和时间流,它们的输入分别是rgb图像和光流场图,每个流都使用多层卷积神经网络对输入的模态进行建模,最后两个流的识别结果融合得到最终的结果。在3维卷积网络中,卷积核从二维升到了3维,增加了“时间”的维度,其出发点是希望通过3维卷积同时学习到视频中的表观特征和动作特征。
双流法将表观和动作特征分成两个流,增加了多模态的信息,但是依然存在以下两点不足:
1.计算量过大,对于每一个流都需要训练相应的深度卷积神经网络,而且光流图的计算代价和存储代价较大,难以在线上系统中部署;
2.对视频时序信息建模不足,其过度依赖光流图完成时序信息的建模,最近的研究表明光流图中的时序信息作用不明显,主要是其内在的外观不变性使得双流法行之有效。
3维卷积法期望通过3维卷积核同时学习到视频中的表观和动作特征,但是依然存在以下两点不足:
1.难以训练,其参数量较大,而且需要对视频进行密集采样,计算代价也相应提高;
2.时序建模不充分,最近研究表明3维卷积对时序顺序并不敏感,说明其3维卷积方式有待改进。
目前比较有效的视频动作识别方法主要有双流法以及3维卷积法,但是它们存在一定的缺点,前者过度依赖光流信息完成视频时序的建模,而最近的研究指出光流对时序信息建模是不充分的,而且其计算量代价较大,后者期待通过3维卷积同时学习表观和动作特征,这导致其参数量较大,同时结合密集采样使得其计算代价也很大,因此模型难以训练。为了更高效地完成视频分类任务,本发明提出了一种算法,该算法通过共享的二维卷积神经网络获取帧级特征,然后将其按照时间顺序堆起来组成稠密图,最后通过一层时序卷积网络并行地获取多尺度特征完成分类任务。
技术实现要素:
本发明的目的是有效解决现有动作识别算法计算速度慢,内存开销大,时序建模不足的问题,提出了一种基于稠密图的高效视频动作识别方法。
具体来说本发明公开了一种基于稠密图的视频分类方法,其中包括:
训练步骤,获取已分类的视频作为训练数据,根据帧特征编码函数,提取该训练数据的多个帧特征表达,并依时间顺序连接该多个帧特征表达,得到第一稠密图,以该第一稠密图训练卷积神经网络,得到时空演化特征提取模型;
第一提取步骤,获取待分类视频,根据该帧特征编码函数,提取该待分类视频的多个帧特征表达,依时间顺序连接该多个帧特征表达,得到第二稠密图;
第二提取步骤,根据预设的时间尺度范围,使用该时空演化特征提取模型提取该第二稠密图的时空演化特征,并对该时空演化特征进行最大池化操作,得到该第二稠密图在该尺度范围内的尺度特征;
循环步骤,调整该时间尺度范围,循环执行该第二提取步骤,以得到多个该尺度特征,对该多个尺度特征通过全连接层并融合,最后通过归一化指数函数,得到该待分类视频属于各类别的概率,提取最大概率对应的类别作为该视频的分类结果。
所述的基于稠密图的视频分类方法,其中该第一提取步骤包括:
从待分类视频中采样n帧:{i1,i2,...,in},其中in代表视频中的第i帧,
所述的基于稠密图的视频分类方法,其中该第二提取步骤包括:
时空演化信息提取步骤,对于第二稠密图x,令xi=xi+j,xi表示第二稠密图中第i帧特征到第i+j帧特征的组合,时序卷积操作按照如下公式进行:
其中m代表时序卷积层的输出通道索引,wm,h是用于抓取相邻h帧时空模式的卷积核,其高度为该时间尺度范围h,宽度为k,t代表转置操作,bm是偏置项,f是非线性映射函数,ci,mh表示第m通道卷积核对xi:xi+h提取的时空演化信息,m代表该时序卷积层的输出通道索引;
时空演化特征提取步骤,根据下式得到该时空演化特征cmh:
对cmh进行经过最大池化操作:
所述的基于稠密图的视频分类方法,其中该循环步骤包括,通过如下归一化指数函数,得到该待分类视频属于各类别的概率score;
所述的基于稠密图的视频分类方法,其中该循环步骤具体包括,将该时间尺度范围h分别调整为2、3、4、5、6帧。
本发明还公开了一种基于稠密图的视频分类系统,其中包括
训练模块,获取已分类的视频作为训练数据,根据帧特征编码函数,提取该训练数据的多个帧特征表达,并依时间顺序连接该多个帧特征表达,得到第一稠密图,以该第一稠密图训练卷积神经网络,得到时空演化特征提取模型;
第一提取模块,获取待分类视频,根据该帧特征编码函数,提取该待分类视频的多个帧特征表达,依时间顺序连接该多个帧特征表达,得到第二稠密图;
第二提取模块,根据预设的时间尺度范围,使用该时空演化特征提取模型提取该第二稠密图的时空演化特征,并对该时空演化特征进行最大池化操作,得到该第二稠密图在该尺度范围内的尺度特征;
循环模块,调整该时间尺度范围,循环调用该第二提取模块,以得到多个该尺度特征,对该多个尺度特征通过全连接层并融合,最后通过归一化指数函数,得到该待分类视频属于各类别的概率,提取最大概率对应的类别作为该视频的分类结果。
所述的基于稠密图的视频分类系统,其中该第一提取模块包括:
从待分类视频中采样n帧:{i1,i2,...,in},其中in代表视频中的第i帧,
所述的基于稠密图的视频分类系统,其中该第二提取模块包括:
时空演化信息提取模块,对于第二稠密图x,令xi=xi+j,xi表示第二稠密图中第i帧特征到第i+j帧特征的组合,时序卷积操作按照如下公式进行:
其中m代表时序卷积层的输出通道索引,wm,h是用于抓取相邻h帧时空模式的卷积核,其高度为该时间尺度范围h,宽度为k,t代表转置操作,bm是偏置项,f是非线性映射函数,ci,mh表示第m通道卷积核对xi:xi+h提取的时空演化信息,m代表该时序卷积层的输出通道索引;
时空演化特征提取模块,根据下式得到该时空演化特征cmh:
对cmh进行经过最大池化操作:
所述的基于稠密图的视频分类系统,其中该循环模块包括,通过如下归一化指数函数,得到该待分类视频属于各类别的概率score;
所述的基于稠密图的视频分类系统,其中该循环模块具体包括,将该时间尺度范围h分别调整为2、3、4、5、6帧。
本发明的重点包括:
高效的视频时空演化表达方法:稠密图,通过共享的二维卷积神经网络获取帧级特征,然后将其按照时间顺序连接起来组成稠密图,在网络训练过程中以task-driven的方式高效地压缩了时空演化特征;
多尺度时序建模;技术效果:通过一层时序卷积网络并行地提取多尺度时序特征,使得视频在类空间中更容易被区分;
本方法提出了一种基于稠密图的高效视频动作识别算法,由于本发明涉及的参数量相比现有技术更少,因此计算复杂度更低。本发明不需要光流图去建模时序信息,相对高效。发明中全部使用了二维卷积核,共享大量网络参数,充分发挥了显卡的并行计算能力,在不损失精度的情况下大大提升了速度,并且使得模型易训练。
附图说明
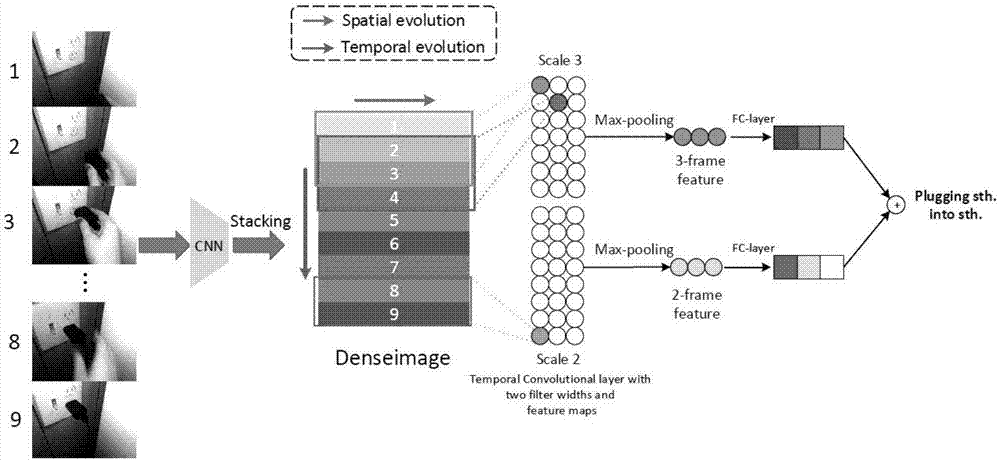
图1为系统结构的整体流程及效果图。
具体实施方式
发明人在进行视频分类/动作识别的研究过程中发现现有技术中存在两大缺陷,其一是双流法的时序建模能力不足,该缺陷主要由双流法的网络架构以及光流图时序信息不足导致;其二是参数量和计算量过大,该缺陷主要由光流图的计算代价高以及3维卷积的特点导致。针对上述缺陷,本发明提出了基于稠密图的视频分类算法,该算法通过共享的二维卷积神经网络提取帧特征,大大降低了模型的参数量,其次通过一层多尺度时序卷积网络获取多尺度的时序特征,大大提升了模型对时序信息的建模能力。
具体来说本发明公开了一种基于稠密图的视频分类方法,其中包括:
训练步骤,获取已分类的视频作为训练数据,根据帧特征编码函数,提取该训练数据的多个帧特征表达,并依时间顺序连接该多个帧特征表达,得到第一稠密图,以该第一稠密图训练卷积神经网络,得到时空演化特征提取模型;
第一提取步骤,获取待分类视频,根据该帧特征编码函数,提取该待分类视频的多个帧特征表达,依时间顺序连接该多个帧特征表达,得到第二稠密图;
第二提取步骤,根据预设的时间尺度范围,使用该时空演化特征提取模型提取该第二稠密图的时空演化特征,并对该时空演化特征进行最大池化操作,得到该第二稠密图在该尺度范围内的尺度特征;
循环步骤,调整该时间尺度范围,循环执行该第二提取步骤,以得到多个该尺度特征,对该多个尺度特征通过全连接层并融合,最后通过归一化指数函数,得到该待分类视频属于各类别的概率,提取最大概率对应的类别作为该视频的分类结果。
所述的基于稠密图的视频分类方法,其中该第一提取步骤包括:
从待分类视频中采样n帧:{i1,i2,...,in},其中in代表视频中的第i帧,
所述的基于稠密图的视频分类方法,其中该第二提取步骤包括:
时空演化信息提取步骤,对于第二稠密图x,令xi=xi+j,xi表示第二稠密图中第i帧特征到第i+j帧特征的组合,时序卷积操作按照如下公式进行:
其中m代表时序卷积层的输出通道索引,wm,h是用于抓取相邻h帧时空模式的卷积核,其高度为该时间尺度范围h,宽度为k,t代表转置操作,bm是偏置项,f是非线性映射函数,ci,mh表示第m通道卷积核对xi:xi+h提取的时空演化信息,m代表该时序卷积层的输出通道索引;
时空演化特征提取步骤,根据下式得到该时空演化特征cmh:
对cmh进行经过最大池化操作:
所述的基于稠密图的视频分类方法,其中该循环步骤包括,通过如下归一化指数函数,得到该待分类视频属于各类别的概率score;
所述的基于稠密图的视频分类方法,其中该循环步骤具体包括,将该时间尺度范围h分别调整为2、3、4、5、6帧。
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
该方法主要分为两个部分:稠密图的建立,多尺度时序卷积网络。
稠密图的建立:假设从视频中采样了n帧:{i1,i2,...,in},其中in代表视频中的第i帧,帧特征编码函数为:
多尺度时序卷积网络。基于上步得到的稠密图,本发明接着设计了高效的卷积神经网络来学习稠密图中的时空演化信息。
对于稠密图x,令xi=xi+j,xi表示稠密图中第i帧特征到第i+j帧特征的组合,时序卷积操作按照如下公式进行:
发明人将时序卷积核wm,h作用在稠密图x的每一个可能的位置,因此会产生一个特征向量:
对cmh进行经过最大池化操作:
最后由不同的尺度值h,获得多尺度的特征,然后分别通过全连接层并融合,通过归一化指数函数(softmax函数)计算最终的分类概率,如下式,其中h={2,3,4,5,6}。
整个网络从稠密图的建立到多尺度时序卷积都是可微分的,因此我们可以直接采用梯度反向传播算法方便的训练网络中的参数,本发明中我们采用小批量的随机梯度下降算法进行参数优化,每一个小批量含有32个样本,动量设置为0.9,权重衰减设置为5e-4,这些值是网络的超参数,可以根据验证集自行调整,本组参数仅作为示例。
具体实施例:假设有一个短视频,发明人首先等间隔采样10帧,每一帧都可以通过帧编码函数获得帧特征,假设帧特征为1024维,那么我们将10个帧特征按照时间顺序连接起来可以得到10*1024的矩阵,该矩阵即为稠密图,对于时间尺度h为2来说,单通道(假设该通道索引为m)的卷积核可以得到维度为10-2+1=9的特征向量cm2,对其进行最大池化操作可以得到一个标量omh,假设通道数m为256,则可以得到256维的特征:ch,该特征表示了相邻h帧的时空演化信息,然后通过全连接层将该特征映射到类别空间,并使用softmax函数获得归一化的概率表示。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还公开了一种基于稠密图的视频分类系统,其中包括
训练模块,获取已分类的视频作为训练数据,根据帧特征编码函数,提取该训练数据的多个帧特征表达,并依时间顺序连接该多个帧特征表达,得到第一稠密图,以该第一稠密图训练卷积神经网络,得到时空演化特征提取模型;
第一提取模块,获取待分类视频,根据该帧特征编码函数,提取该待分类视频的多个帧特征表达,依时间顺序连接该多个帧特征表达,得到第二稠密图;
第二提取模块,根据预设的时间尺度范围,使用该时空演化特征提取模型提取该第二稠密图的时空演化特征,并对该时空演化特征进行最大池化操作,得到该第二稠密图在该尺度范围内的尺度特征;
循环模块,调整该时间尺度范围,循环调用该第二提取模块,以得到多个该尺度特征,对该多个尺度特征通过全连接层并融合,最后通过归一化指数函数,得到该待分类视频属于各类别的概率,提取最大概率对应的类别作为该视频的分类结果。
所述的基于稠密图的视频分类系统,其中该第一提取模块包括:
从待分类视频中采样n帧:{i1,i2,...,in},其中in代表视频中的第i帧,
所述的基于稠密图的视频分类系统,其中该第二提取模块包括:
时空演化信息提取模块,对于第二稠密图x,令xi=xi+j,xi表示第二稠密图中第i帧特征到第i+j帧特征的组合,时序卷积操作按照如下公式进行:
其中m代表时序卷积层的输出通道索引,wm,h是用于抓取相邻h帧时空模式的卷积核,其高度为该时间尺度范围h,宽度为k,t代表转置操作,bm是偏置项,f是非线性映射函数,ci,mh表示第m通道卷积核对xi:xi+h提取的时空演化信息,m代表该时序卷积层的输出通道索引;
时空演化特征提取模块,根据下式得到该时空演化特征cmh:
对cmh进行经过最大池化操作:
所述的基于稠密图的视频分类系统,其中该循环模块包括,通过如下归一化指数函数,得到该待分类视频属于各类别的概率score;
所述的基于稠密图的视频分类系统,其中该循环模块具体包括,将该时间尺度范围h分别调整为2、3、4、5、6帧。
- 还没有人留言评论。精彩留言会获得点赞!