一种面向MapReduce框架的有效计算与数据传输重叠执行方法与流程
本发明涉及大数据处理计算框架等领域,特别是提出了一种面向mapreduce框架的有效计算与数据传输重叠执行方法。
背景技术:
mapreduce是google公司于2004年提出的一种用于大数据处理的并行计算框架,通过在大量廉价的机群节点同时运行多个任务并行地处理海量数据,提高了处理数据的性能,在过去十多年得到了迅速的发展和广泛应用。
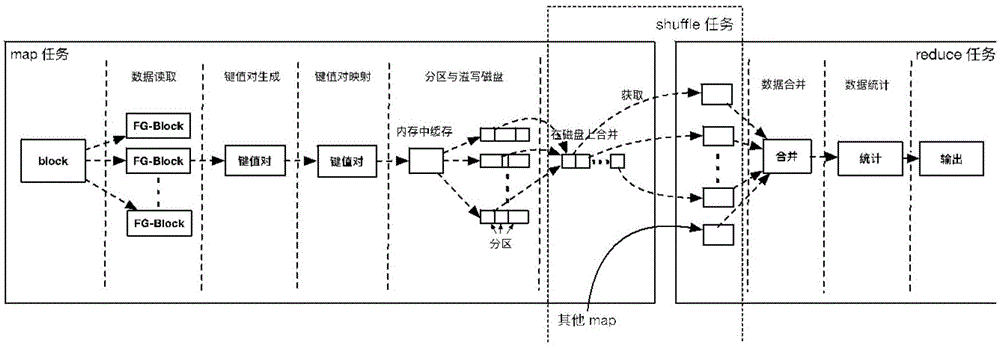
mapreduce框架主要提供了映射和化简操作,其中映射操作对集合中每个元素应用同一个操作,在mapper端实现;化简操作遍历集合中的元素返回一个综合结果,在reducer端实现。mapper端的操作主要包含了数据读取、键值对生成、键值对映射、分区与磁盘溢写,数据读取即从分布式文件系统读取对应数据块内容,键值对生成将元素对象抽象为键值对<key,value>的形式,是操作数据的最小单位,键值对映射将原键值通过一系列映射变换得到新的键值对,分区与磁盘溢写包含两部分内容,分区根据键值key的hash值对reducer个数取余得到一个编号值,这个编号值决定了键值对应该分配到哪一个reducer上,磁盘溢写指当mapper端操作输出数据结果超过内存阈值,从内存往磁盘写数据的过程。
reducer端的操作主要包含数据获取、数据合并和数据统计,数据获取是指根据mapper端分区的结果,从mapper端复制对应数据到reducer端计算,数据合并是指将从多个mapper端获取到的数据做合并,数据统计指遍历所有元素并得到最终结果,其中将mapper端产生的数据发送到reducer端的过程称为shuffle,也就是数据传输。
目前,mapreduce框架对mapper端任务、数据传输和reducer端任务是串行执行的,mapper端的溢写文件需要合并得到最终文件才可以进行数据传输,reducer端获取到数据才能够开始计算,这导致reducer端计算的延迟。同时,数据传输所产生的通信延迟对mapreduce的整体性能和吞吐率产生了显著影响。
关于数据延迟优化问题,国内外研究者主要从硬件、预取等方面给出了优化方案。zhang(internationalconferenceonparallel&distributedsystems,2009)等提出了一种将中间数据存入分布式内存方法,用来提高mapreduce读写性能;wang等(lecturenotesincomputerscience,2014)提出了一种基于固态硬盘ssd的数据缓存技术mpcache,用于缓存输入数据和本地数据从而提高mapreduce的读写性能,该方法需要配置额外的存储资源以获取较好的读写性能;seo等(procoftheieeeinternationalconferenceonclustercomputingandworkshops,2009)提出了一种基于预取和预排序技术提高mapreduce性能;郭梦影等(计算机研究与发展,2015)对mapreduce在不同虚拟化平台(lxc、kvm和vmware)上的i/o性能进行了测评,能够使mapreduce在虚拟化平台中获得最好的i/o性能;liroz等(informationsystems,2016)提出一种增加中间阶段的方法提高数据的处理能力,通过了一个intermediatereducer并行地处理元组数据集,将元组根据key进行关联分区,减轻了后续reduce的任务。这些方法通过特殊的硬件或机制来优化数据延迟,对提高整体性能具有一定的作用,然而其适用性和效果还需要进一步提高,因为普通机群还不具备这些硬件条件。
技术实现要素:
为了减少数据传输产生的通信延迟对mapreduce框架整体性能的影响,本发明提出了一种面向mapreduce框架的有效计算与数据传输重叠执行方法,隐藏数据通信延迟,提高框架的整体性能。
一种面向mapreduce框架的有效计算与数据传输重叠执行方法,包括以下步骤:
(1)创建细粒度数据块;
在mapreduce框架中,默认的数据处理单位是粗粒度数据块block,其大小一般为64m或128m,对block进一步细分,得到多个细粒度数据块(fine-grainedblock,fg-block),对这些fg-block进行流水线处理;
设数据块block的大小为c,细分粒度为f,细分后得到的细粒度数据块fg-block数量为n,则有以下关系:
n=c/f
(2)分离数据传输与有效计算;
将主要利用cpu资源对数据处理的操作称为有效计算,如数据转换与数据聚合,将主要利用i/o资源和带宽资源的数据处理操作称为数据传输,如数据读写与网络通信,将有效计算与数据通信分耦,实现有效计算与数据传输重叠执行;
(2.1)有效计算;
有效计算主要分为mapper端的有效计算与reducer端的有效计算,mapper端的有效计算主要将数据转换成键值对形式,再通过一系列映射变换产生新的键值对,根据新键值对的键值通过hash函数分区,计算结果超过内存阈值则向磁盘溢写文件;reducer端的有效计算主要是从多个mapper端获取得到的数据并合并统计得到最终的结果;
(2.2)数据传输;
数据传输指将mapper端产生的数据传输到reducer端的过程,mapper端的计算结果超出内存阈值就会溢写到磁盘,对溢写文件逐一判断,若溢写文件大小超过一定阈值则将溢写文件发送到reducer端,否则对溢写文件合并,合并达到阈值后将其发送到reducer端,将数据传输提前;
(3)文件合并发送准则;
在对溢写文件合并时,需要考虑两个因素,文件发送阈值与文件合并路数;
(3.1)文件发送阈值;
文件发送阈值指溢写文件合并得到的新文件达到设定的阈值时开始将新文件发送到reducer端,如果文件发送阈值过大,将延迟数据传输并将reducer端计算时间延迟,如果文件发送阈值过小,将增加数据传输开销以及reducer端的读写开销;
(3.2)文件合并路数;
文件合并路数是指将多个溢写文件合并为一个文件的路数,如果文件合并路数过大,需要等待的溢写文件数也就越多,将增加数据传输延迟,如果文件合并路数过小,则合并带来的额外开销同样也会造成过多的数据传输延迟;
(4)数据传输与有效计算重叠执行;
将mapper端的有效计算、数据传输和reducer端的有效计算以流水的方式重叠执行,隐藏数据传输延迟,其基本步骤是:
步骤1:fg-block作为流水处理的基本单位,mapper端读取完fg-block数据,完成有效计算之后即可处理下一个fg-block;
步骤2:当溢写文件满足文件发送阈值即可开启数据传输,将数据从mapper端传输到reducer端,然后等待传输后续溢写文件;
步骤3:reducer端接收到数据之后,启动有效计算,如果存在数据依赖的操作,则等待数据全部传输完成进行计算;
步骤4:以上三个步骤按照流水方式,以fg-block为单位进行迭代处理,执行过程相互重叠,数据传输被隐藏于有效计算中;
步骤5:reducer端接收完所有数据,做最后的统计计算。
本发明的优点:
本发明通过将mapreduce框架的有效计算和数据传输重叠执行,隐藏了数据传输导致的延迟开销,提高了mapreduce框架的数据处理性能,具体的方法是将mapper端的有效计算、中间数据传输和reducer端的有效计算隔离开来,以流水线的方式重叠执行,提高了mapreduce的整体性能。
附图说明
图1是本发明的mapreduce框架的数据处理总体流程。
图2是本发明的溢写文件合并流程。
图3是本发明的有效计算和数据传输重叠执行示意图。
具体实施方式
以经典的wordcount单词计数程序作为实例,结合图1~图3对本发明专利的实施方式进行说明,步骤如下:
(1)创建细粒度数据块
假设数据块block大小为128m,对block进一步细分,得到多个细粒度数据块fg-block,每个fg-block的大小为8m,则根据公式n=c/f,可得一共得到细粒度数据块fg-block数量为16;
(2)分离数据传输与有效计算
(2.1)有效计算
mapper端的有效计算:将从划分的8m细粒度fg-block中读取到数据单词分离,得到每一个单词,并将每个单词转换为〈key,value〉键值对形式,然后根据键值key将决定每个键值对应分配到reducer节点编号,当超过内存阈值时,则将数据溢写到磁盘得到溢写文件;
reducer端的有效计算:将来自mapper端的溢写文件合并,并将key值相同的键值的value值相加,得到单词数量统计最终结果;
(2.2)数据传输
定义一个队列,将mapper端的溢写文件加入队列中,每次采用8路归并的方法得到一个新的溢写文件,若该溢写文件超过8m,则将该溢写文件发送到reducer端,否则将该溢写文件加入队列中,直到文件全部发送reducer端,若只剩一个溢写文件则直接发送到reducer端;
(3)文件发送阈值与文件合并路
(3.1)文件发送阈值
文件发送阈值不宜过大也不宜过小,通过实验表明当阈值取32m时,集群的计算性能是最优的;
(3.2)文件合并路数
文件合并路数不宜过大也不宜过小,通过实验表明当合并路数取16时,集群的计算性能是最优的;
(4)数据传输与有效计算流水执行
结合如图3所示,将mapper端的有效计算、数据传输和reducer端的有效计算以流水的方式重叠执行,其基本步骤是:
步骤1:将划分好的8m细粒度fg-block作为流水处理的基本单位,mapper端读取fg-block数据,按照空格划分取出每个单词,再将每个单词转化为<key,value>键值对,例如<hello,1>;然后通过hash分区确定key应该分配到哪一个reduce节点,数据结果超过内存阈值则溢写磁盘,之后即可处理下一个fg-block;
步骤2:对溢写的文件做一个大小判断,当满足文件发送阈值8m即可开启数据传输,否则合并溢写文件;将满足条件的数据从mapper端传输到reducer端,然后等待传输后续满足条件的溢写文件;
步骤3:reducer端接收到来自各个mapper端数据之后,对数据做一个合并;
步骤4:以上三个步骤按照流水方式,以fg-block为单位进行迭代处理,执行过程相互重叠;
步骤5:reducer端接收完所有数据,最后遍历合并结果并对单词统计,得到最终单词数量统计。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!