一种基于机器学习和大数据处理的内容生产系统的制作方法
本发明涉及一种生产系统,尤其是涉及一种基于机器学习和大数据处理的内容生产系统。
背景技术:
传统的内容的生产方式应用领域比较狭窄,并且需要大量的传统劳动力。
该系统的本质是支持机器学习算法设计和大规模数据处理的一体化大数据机器学习系统。包括机器学习方面的模型、训练、精度问题以及大数据处理方面的数据挖掘、分布式存储、并行化计算、网络通信、局部性计算、任务调度、系统管理等诸多因素。
该系统旨在利用ai机器学习和大数据处理技术自动化地进行数据采集、识别、清洗、加工、分析、模型运算与智能化输出,来实现内容的自动化生产,最终输出成果既包括结构化数据呈现、又包括文本及超文本类内容成果。
技术实现要素:
本发明要解决的技术问题是现有传统的内容的生产方式应用领域比较狭窄,并且需要大量的传统劳动力,因此提供一种基于机器学习和大数据处理的内容生产系统,从而解决上述问题。
为实现上述目的,本发明提供如下技术方案:一种基于机器学习和大数据处理的内容生产系统,其特征在于,该系统包括用户管理模块、系统功能需求模块、数据管理模块、机器学习系统、特征收集系统、分析处理系统和hadoop大数据底层系统,其中用户管理模块由用户管理和用户验证组成,其中系统功能需求模块由模板库、成果管理和回收站,其中数据管理由数据源和系统底层数据。
作为本发明的一种优选技术方案,用户管理包括本系统的用户设置主账号和子账号两个级别,主账号拥有上传模板、修改模板、查看及管理生产成果,以及管理子账号的权限;子账号拥有查看生产成果,以及由主账号指派的相应任务的操作权限;用户验证:如有需要,用于进一步进行数据源平台的权限登录验证。
作为本发明的一种优选技术方案,模板库包括:
1)模板库为在内容生成前期,需要研究及开发完成的样本库,其中集成了模型算法、数据源、加工逻辑、算法逻辑、模型逻辑、文本逻辑等;
2)根据不同的内容类型及客户类型,将产生不同的模板,模板将存储在系统中,供选择性调用;
3)对于系统已经开发完成的模板,管理员拥有上传模板,以及修改模板的权限;
4)对于完全新的需要开发的模板,开放申请模块,可提交至系统进行判断审核是否进行下一步开发。
作为本发明的一种优选技术方案,成果管理包括:
1)新建内容任务:选择模板库和数据源,输入参数,点击一键生成,内容成果生成,手动在线校对与编辑,支持保存,指派其他用户编辑等操作,最终完成成果导出;
2)进行中任务:指上一次保存下来,还需要继续进行编辑的半成品,可在此点击继续编辑直至完成;
3)已完成成果:对已完成并导出的内容可重新编辑,也可删除。
作为本发明的一种优选技术方案,回收站包括:
1)用于暂时储存历史作废的内容成果;
2)最长保存周期为30天,30天后自动永久清除;
3)支持手动永久删除。
作为本发明的一种优选技术方案,数据源根据不同的数据源和不同的算法模型设计,对数据源进行不同维度的存取与计算底层设计。
作为本发明的一种优选技术方案,系统底层数据包括mysql:业务数据库的处理、hadoop:提供实时数据接口、文件系统:用于报告文件及文本等的处理。
作为本发明的一种优选技术方案,机器学习系统包括核心算法库,核心算法库存储算法模型配置项等资料,通过不断的优化和提升来保证核心算法库的越发完善;
步骤一:选择数据源,并训练数据、验证数据和测试数据;
步骤二:模型数据:依据训练数据的特征来构建使用计算模型;
步骤三:验证模型:将验证数据接入模型进行验证,并根据结果不断优化;
步骤四:测试模型:使用测试数据检查被验证的模型的表现,并根据结果不断优化;
步骤五:使用模型:使用完全训练好的模型在目标数据上做计算分析;
步骤六:调优模型:在不断应用实践中,依据更多数据和不同的特征或调整过的参数来提升算法性能。
作为本发明的一种优选技术方案,特征收集系统是根据业务数据的持续更新,数据源不断累加,特征指标不断丰富及提升完善,并存放于队列处理,然后分类存储;
步骤一:根据数据源的特征库在获取到的元数据中抽取特征指标;
步骤二:并将新抽取的特征指标更新到特征库;
步骤三:分类存储及扩充;
作为本发明的一种优选技术方案,分析处理系统包括:
a、根据输入数据,判断分析并决策输出结果到业务系统中;
b、判断分析决策原则:使用底层数据特征作为依赖条件;
hadoop大数据底层系统包括:
a、hadoop大数据底层作为数据仓库,用于机器学习的底层数据支撑,主要用于海量数据的清洗、分析、以及数据特征和数据汇总的处理;
b、数据处理完成后,使用数据分类模型进行数据归类处理。
与目前技术相比,本发明的有益效果是:该系统打破了传统内容的生产方式,以海量数据处理能力为基础,通过机器学习的模型算法运算来实现内容的自生产,同时机器学习的不断迭代与自适应将使得内容成果愈发精准。该系统的产生将极大的释放传统劳动力,任何有些许固化模式的内容都可以实现智能化自动生产,可以广泛应用到营销活动、咨询行业、资本市场、行业研究、政府项目等领域,极大地提高社会和经济生产效率。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明的系统数据处理模型图;
图2为本大明的机器学习系统流程图;
图3为本发明的特征收集系统流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
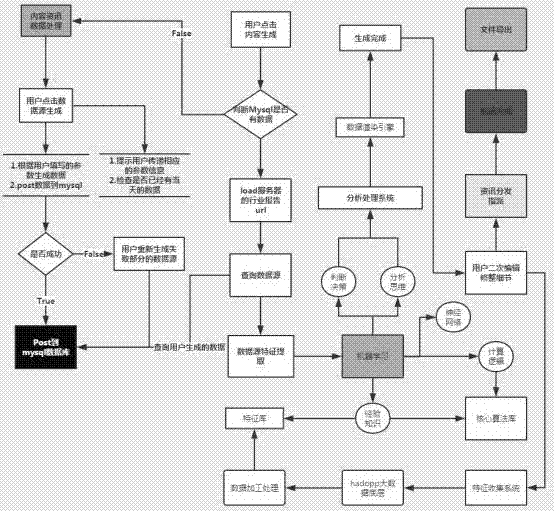
如图1-3所示,一种基于机器学习和大数据处理的内容生产系统,该系统包括用户管理模块、系统功能需求模块、数据管理模块、机器学习系统、特征收集系统、分析处理系统和hadoop大数据底层系统,其中用户管理模块由用户管理和用户验证组成,其中系统功能需求模块由模板库、成果管理和回收站,其中数据管理由数据源和系统底层数据。
作为本发明的一种优选技术方案,用户管理包括本系统的用户设置主账号和子账号两个级别,主账号拥有上传模板、修改模板、查看及管理生产成果,以及管理子账号的权限;子账号拥有查看生产成果,以及由主账号指派的相应任务的操作权限;用户验证:如有需要,用于进一步进行数据源平台的权限登录验证。
模板库包括:
1)模板库为在内容生成前期,需要研究及开发完成的样本库,其中集成了模型算法、数据源、加工逻辑、算法逻辑、模型逻辑、文本逻辑等;
2)根据不同的内容类型及客户类型,将产生不同的模板,模板将存储在系统中,供选择性调用;
3)对于系统已经开发完成的模板,管理员拥有上传模板,以及修改模板的权限;
4)对于完全新的需要开发的模板,开放申请模块,可提交至系统进行判断审核是否进行下一步开发。
成果管理包括:
1)新建内容任务:选择模板库和数据源,输入参数,点击一键生成,内容成果生成,手动在线校对与编辑,支持保存,指派其他用户编辑等操作,最终完成成果导出;
2)进行中任务:指上一次保存下来,还需要继续进行编辑的半成品,可在此点击继续编辑直至完成;
3)已完成成果:对已完成并导出的内容可重新编辑,也可删除。
回收站包括:
1)用于暂时储存历史作废的内容成果;
2)最长保存周期为30天,30天后自动永久清除;
3)支持手动永久删除。
数据源根据不同的数据源和不同的算法模型设计,对数据源进行不同维度的存取与计算底层设计。
系统底层数据包括mysql:业务数据库的处理、hadoop:提供实时数据接口、文件系统:用于报告文件及文本等的处理。
机器学习系统包括核心算法库,核心算法库存储算法模型配置项等资料,通过不断的优化和提升来保证核心算法库的越发完善,如图2所示;
步骤一:选择数据源,并训练数据、验证数据和测试数据;
步骤二:模型数据:依据训练数据的特征来构建使用计算模型;
步骤三:验证模型:将验证数据接入模型进行验证,并根据结果不断优化;
步骤四:测试模型:使用测试数据检查被验证的模型的表现,并根据结果不断优化;
步骤五:使用模型:使用完全训练好的模型在目标数据上做计算分析;
步骤六:调优模型:在不断应用实践中,依据更多数据和不同的特征或调整过的参数来提升算法性能。
特征收集系统是根据业务数据的持续更新,数据源不断累加,特征指标不断丰富及提升完善,并存放于队列处理,然后分类存储,如图3所示;
步骤一:根据数据源的特征库在获取到的元数据中抽取特征指标;
步骤二:并将新抽取的特征指标更新到特征库;
步骤三:分类存储及扩充;
分析处理系统包括:
a、根据输入数据,判断分析并决策输出结果到业务系统中;
b、判断分析决策原则:使用底层数据特征作为依赖条件;
hadoop大数据底层系统包括:
a、hadoop大数据底层作为数据仓库,用于机器学习的底层数据支撑,主要用于海量数据的清洗、分析、以及数据特征和数据汇总的处理;
b、数据处理完成后,使用数据分类模型进行数据归类处理。
请参阅图1,数据处理模型基本逻辑如下:
(1)用户点击数据源生成,输入将要生成内容的各类参数:模板参数、分析对象参数等;
(2)系统进行参数验证,以及数据源是否成功调取判断;
(3)验证及判断成功后,开始进行数据采集、识别、清洗、加工、分析、模型运算等一系列操作;
(4)直至运算完成,输出初步结果;
(5)用户对内容结果进行必要的校验编辑;
(6)之后可将生成的结果面向不同角色用户进行分发及指派;
(7)确认无误后,编辑完成,点击导出,最终成果内容文件输出完成。
该系统打破了传统内容的生产方式,以海量数据处理能力为基础,通过机器学习的模型算法运算来实现内容的自生产,同时机器学习的不断迭代与自适应将使得内容成果愈发精准。该系统的产生将极大的释放传统劳动力,任何有些许固化模式的内容都可以实现智能化自动生产,可以广泛应用到营销活动、咨询行业、资本市场、行业研究、政府项目等领域,极大地提高社会和经济生产效率。
本发明旨在建设一套基于机器学习和大数据处理的内容自生产系统,该系统本质是搭建海量数据集群化处理和机器学习并行作用并能达到自迭代优化的创新型一体化架构系统,在该架构不断应用和实践下,实现机器自学习和自适应,最终在内容生产领域实现自动化、智慧化、高标准、高质量的生产。
该系统的核心意义在于将ai技术应用在产业服务链上的的落地化实践,以hadoop大数据底层和处理技术为支撑,透过系统构架的实现,保证机器学习乃至深度学习算法的不断优化和迭代,从而能够实现数据化和文本智能双重内容的自助呈现,并在应用实践中透过机器自学习来不断提升智慧化程度,从而最大化地节省人财物等资源投入,改变传统行业生产模式,以创新动能实现社会价值最大化。
该项目的实现包括机器学习模型调用、训练、修正以及数据挖掘、分布式存储、并行化计算、网络通信、局部性计算、任务调度、系统管理等数据底层核心技术。系统实现流程集中在用机器学习算法和大数据处理技术自动化地进行数据采集、识别、清洗、加工、分析、算法调用与自学习、模型优化、智慧化输出等环节,最终输出成果既包括结构化数据呈现、又包括文本及超文本类内容成果。
系统特征:
(1)机器学习是该系统的核心,确保系统可以自学习和自适应,在不断的应用实践下持续提升智慧化水平,使得内容产生结果更加智能化、精准化。
(2)训练数据和特征的提取、并行学习算法的设计、训练模型和参数的查询管理、分布式训练计算过程、自学习优化迭代等,都集成在该系统平台中完成。
(3)提供多种并行训练模式,支持不同的机器学习模型和算法。
(4)提供对底层系统的抽象,以实现对底层通用大数据处理引擎的支持,并提供数据科学中常用的编程语言接口(api)。
(5)拥有开放和丰富的生态、广泛的应用和快速的进化能力
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!