基于不平衡学习策略高影响缺陷报告预测方法与流程
本发明涉及一种预测方法,具体地说是一种基于不平衡学习策略高影响缺陷报告预测方法。
背景技术:
随着开源软件项目规模和复杂性的增加,在大多数软件系统中出现了不可避免的bug(缺陷),bug修复已经成为软件开发和维护中最重要的活动之一。但是,缺陷报告的数量非常巨大,开发人员难以有效管理,而在这些缺陷报告中,不同的缺陷有着不同的影响,开发人员最需要优先解决的缺陷是那些少量的但是具有重大影响的缺陷,因此,提供一种有效的方法来来帮助开发人员检测到那些对于软件系统有重大影响的缺陷是非常有必要的。而这些具有高优先级的缺陷被称为高影响bug。在之前的研究及相关工作中,有人提出了通过分类算法和不平和策略的组合来识别高影响bug的方式,但是这些方法的结果并不尽如人意,识别准确率并不是很高,并不能应用于软件项目中。
文献[automatedidentificationofhighimpactbugreportsleveragingimbalancedlearningstrategies]和[high-impactbugreportidentificationwithimbalancedlearningstrategies]中对于两种高影响力的缺陷(bug)进行了研究,对于surprisebugs采用了smote(合成少数过采样技术)+knn(k临近)来进行不平衡问题的优化以及分类问题,对于breakagebugs采用了rus(随机欠采样)+nb(朴素贝叶斯)来处理不平衡问题以及分类问题。
上述的方法提出的解决问题的方式在分析问题时只使用了一种分类方法,由于不同的分类方式具有不同的特性,因此只使用一种分类方式在求解问题时很难得到较高的评价。
技术实现要素:
根据上述提出的技术问题,提出了一种基于通过优化集成与不平衡学习策略(oiils)的预测方法,以确定该缺陷是否具有高影响力,旨在帮助开发人员检测对软件系统构成更多威胁的漏洞。本发明采用的技术手段如下:
一种基于不平衡学习策略与优化集成的关于高影响缺陷报告预测方法,具有如下步骤:
s1、使用文本预处理方法对缺陷报告的文本信息进行处理;
s2、使用10折交叉验证的方法,将步骤s1得到的处理后文本信息分储为训练集和测试集;
s3、使用不平衡学习策略smote(syntheticminorityover-samplingtechnique)算法对训练集做多次数据平衡处理;
s4、使用多个分类器对经过平衡处理的训练集进行训练;
s5、根据不同分类器对每个类别的发现能力不同,使用cplex约束求解器对多个分类器进行优化集成,把多个分类器的优点进行集成并输出;
s6、使用文本特征提取模块来对测试集中的报告进行文本特征提取;
使用步骤s5中的训练好的模型对测试集中的缺陷报告进行预测。
所述步骤s1的具体步骤如下:
从缺陷报告的摘要和描述字段中提取文本特征;
利用分词将提取的文本特征分段为单词,并删除其中包含很少含义的停用词,数字和标点符号(为了减少噪声数据),之后应用iteratedlovinsstemmer算法进行词干化处理以协调具有相似含义的单词;
根据词干化处理后的单词,使用one-hot模式将每个缺陷报告转换成文本向量。
所述步骤s3的具体步骤如下:
将训练集的文本信息转换成文本特征向量之后,采用smote算法对训练集进行平衡化处理;
根据文本特征向量的值,检测属于少数类中的每个缺陷的k个欧氏距离最相近的邻居;
将每个缺陷及其k个最相似的邻居连接起来,并分别在这些连线中随机选择点,作为少数类别的新数据,以减少训练集的不平衡分布带给分类器的负面影响。如果一个数据集出现属于少数类中的n个缺陷,smote算法将产生k*n个人工点。
所述步骤s4的具体步骤如下:
获取经过平衡处理的训练集数据后,开始对数据进行分类,获取训练集中缺陷报告属于每个类别的概率:
不同的分类器在不同的数据集上执行不同的预测能力,利用不同的分类器预测同一数据集的效果也不同。另外,由不平衡学习策略smote构建的人工数据存在一定的随机性,为了提高稳定性我们整合了不同的分类器。
分别采用knn,j48和nbm三种分类器来获取训练集中缺陷报告属于每个类别的概率。
所述步骤s5的具体步骤如下:
包含权重训练阶段,权重调整阶段以及最小选择阶段;
权重训练:分类器对于每个样本会输出该样本属于不同类别的判别概率,通过比较概率的大小来确定目标的类别;并通过权重调整每个训练样本属于不同类别的判别概率,提高分类器的预测准确性;
提取训练集数据的特征,并确定缺陷报告是属于多数类还是少数类,相应结果用ci表示,1表示多数类,-1表示少数类;
对训练集数据,使用分类器来进行自测,用pi0表示多数类概率,用pi1表示少数类概率;
将子目标函数建立等式:
子目标函数只包含两个结果,为1时表示第i个缺陷结果预测为真,为-1时为假;
这种集成方法将优化权重问题视为线性规划问题。
使用约束求解器来获取合适的权重,以此来获得识别高影响缺陷报告的最高性能;优化目标即确定合适的权重值,约束则要求权重的和为1,并且每个权重的值都要在0到1之间;
权重调整:权重训练后,为每个分类器获得最合适的权重w0和w1;
权重w0和w1用于调整由相应分类器生成的预测结果:利用相应的w0来调整多数类概率
最小选择:权重调整之后,获取三组预测结果,每组包含两个类别的概率(对于同一个缺陷来说多数类的预测有三种结果,少数类的预测也有三种结果),将
使用由
令k=1,即将属于少数类的训练集数据的数量加倍。
本发明克服了数据的不平衡特性并加以利用,将不平衡学习策略与约束求解相结合,基于不同分类算法(分类器)的不同能力,提出了利用权重优化每个分类器的判别概率以提高分类效果,并将优化后的多个分类器进行集成,通过获取更合适的权重来获得更高的准确率。
基于上述理由本发明可在预测方法等领域广泛推广。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
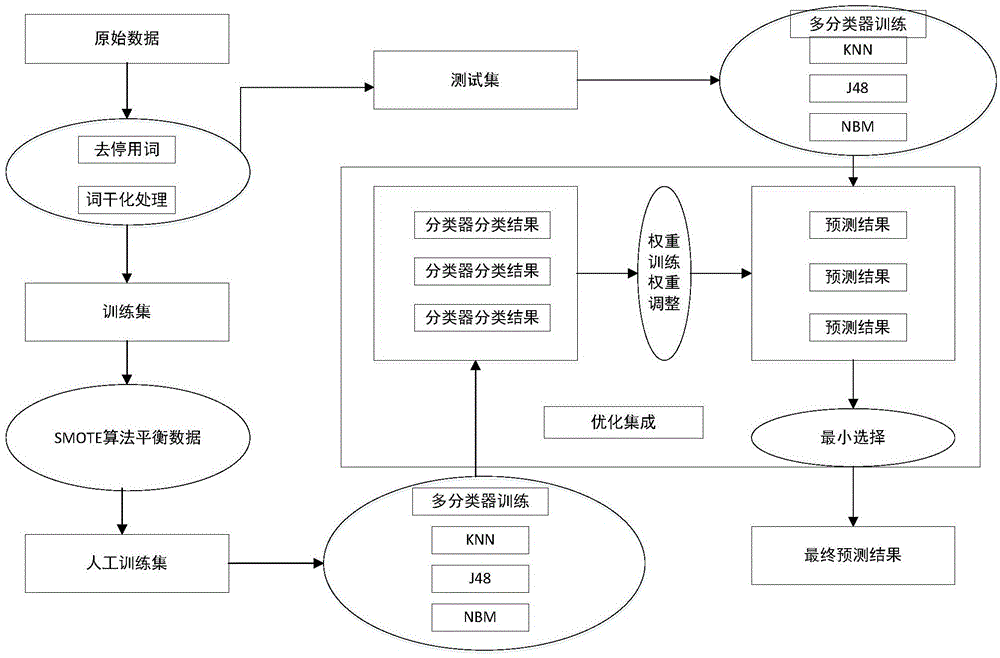
图1是本发明的具体实施方式中基于不平衡学习策略高影响缺陷报告预测方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种基于不平衡学习策略高影响缺陷报告预测方法,具有如下步骤:
s1、使用文本预处理方法对缺陷报告的文本信息进行处理:
从缺陷报告的摘要和描述字段中提取文本特征;
利用分词将提取的文本特征分段为单词,并删除其中包含很少含义的停用词,数字和标点符号,之后应用iteratedlovinsstemmer算法进行词干化处理以协调具有相似含义的单词;
根据词干化处理后的单词,使用one-hot模式将每个缺陷报告转换成文本向量;
s2、使用10折交叉验证的方法,将步骤s1得到的处理后文本信息分储为训练集和测试集;
s3、使用不平衡学习策略smote算法对训练集做数据平衡处理:
将训练集的文本信息转换成文本特征向量之后,采用smote算法对训练集进行平衡化处理;
根据文本特征向量的值,检测属于少数类中的每个缺陷的k个欧氏距离最相近的邻居,令k=1;
将每个缺陷及其k个最相似的邻居连接起来,并分别在这些连线中随机选择点,作为少数类别的新数据,以减少训练集的不平衡分布带给分类器的负面影响;
s4、使用多个分类器对经过平衡处理的训练集进行训练:
获取经过平衡处理的训练集数据后,开始对数据进行分类,获取训练集中缺陷报告属于每个类别的概率:
分别采用knn,j48和nbm三种分类器来获取训练集中缺陷报告属于每个类别的概率;
s5、根据不同分类器对每个类别的发现能力不同,使用cplex约束求解器对多个分类器进行优化集成,把多个分类器的优点进行集成并输出:
包含权重训练阶段,权重调整阶段以及最小选择阶段;
权重训练:分类器对于每个样本会输出该样本属于不同类别的判别概率,通过比较概率的大小来确定目标的类别;并通过权重调整每个训练样本属于不同类别的判别概率,提高分类器的预测准确性;
提取训练集数据的特征,并确定缺陷报告是属于多数类还是少数类,相应结果用ci表示,1表示多数类,-1表示少数类;
对训练集数据,使用分类器来进行自测,用
将子目标函数建立等式:
子目标函数只包含两个结果,为1时表示第i个缺陷结果预测为真,为-1时为假;
使用约束求解器来获取合适的权重,以此来获得识别高影响缺陷报告的最高性能,优化目标即确定合适的权重值,约束则要求权重的和为1,并且每个权重的值都要在0到1之间;
权重调整:权重训练后,为每个分类器获得最合适的权重w0和w1;
权重w0和w1用于调整由相应分类器生成的预测结果:利用相应的w0来调整多数类概率
最小选择:权重调整之后,获取三组预测结果,每组包含两个类别的概率,将
使用由
s6、使用文本特征提取模块来对测试集中的报告进行文本特征提取;
使用步骤s5中的多个分类器对测试集中的缺陷报告进行预测,得到结果;
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!