一种基于map-reduce原理的多数据库访问方法与流程
本发明涉及多数据库访问技术领域,尤其涉及一种基于map-reduce原理的多数据库访问方法。
背景技术:
随着技术日新月异,企业信息化不断推进,企业信息系统的数量和类型都不断增加,以满足企业各种各样管理需求。但多样化的信息系统带来了多样化的数据库,能对多种数据库进行连接统一的访问,是企业实现数据统一管理、互融互通的关键。
但有两大难点需要克服:一是能够同时连接多种数据库,二是各个数据库采用的sql语句是不同的、非标准化的、甚至是独特的,无法进行统一使用。
为了实现可靠的、高性能的多数据库访问,本发明创新的借鉴了map-reduce思想并行、可扩展、分治法的优点,利用数据对象技术先实现对单个数据库进行连接,再对连接共享、加工,使用ansisql,统一使用标准。本发明同时攻克了访问多数据库和统一不同种类数据库sql使用标准的难点,为企业数据库统一管理、互融互通提供行之有效的解决方案。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种基于map-reduce原理的多数据库访问方法。
本发明通过以下技术方案来实现上述目的:
一种基于map-reduce原理的多数据库访问方法,包括以下步骤:
步骤s1,通过配置其mapper进程能与不同的数据库建立一对一的连接;
步骤s2,其整体采用map-reduce的原理,将sql语句进行切分,对应多个数据库,分开查询,最后按顺序进行组合;
步骤s3,其内部通信过程采用随机法发送信息,能够有效地分摊计算量和工作量,均衡内部系统负载,提高整体性能;
步骤s4,其定义了多种内部数据格式,用于实现同时对不同数据库,采用统一ansisql标准查询的功能,具体体现在:
1)用户查询语句格式;
2)数据库连接对象格式;
3)sql切分过程数据格式;
4)sql处理过程数据格式;
5)reducer过程数据格式。
本发明优选的,根据步骤s4,所述数据库连接,首先以json格式定义了数据库连接对象描述文件,其包含:
{"type":"",
"ip":"",
"port":"",
"db_name":"",
"user":"",
"pass":""}
该数据对象包含type、ip、port、db_name、user、pass等五个字段,分别为数据库类型,数据库ip地址,数据库端口号,数据库名称,数据库用户名,数据库密码。
通过socket技术向数据库连接对象发起tcp连接,在建立连接后,通过数据库厂商提供的api解析其数据格式,最终建立数据库连接。
本发明优选的,根据步骤s4,所述sql切分过程接收到用户输入的查询语句后,用户查询语句格式为:
{"db_name1":{
"sql":"",
"sql2":"",
"type":""}
其中db_name为数据库名,type可不写,当存在不同种类的数据库种数据库重名情况是,需要写明type,以便进行区分;sql为ansi标准的sql语句;
根据sql语句中查询的数据库名,将sql语句进行切分,形成如下格式:
{"type":"",
"db_name":"",
"sql":"",
"code":"",
"data":"",
"num":"",
"index":""}
其中type、db_name与上文相同,sql为ansi标准sql,code随机生成的uuid,代表本次查询,num为切分的总sql条数,index为本sql在所有sql中的顺序;
为了实现高可用性,splittersql切分过程采用随机法发送sql语句到sql解析过程,防止某一个sql解析进程过度繁忙。
本发明优选的,根据步骤s4,所述sql解析过程接收到splittersql切分过程发来的sql语句后,sql解析过程根据数据库开发厂商提供的sql标准,将ansi标准的sql语句翻译为适合该数据库标准的sql语句,同样为了高性能,采用随机法将非标准的sql语句发给sql处理过程进行处理。
本发明优选的,根据步骤s4,所述sql处理过程,mapper进程收到非标准sql语句后,立即发送给数据库执行,取得数据后,将数据发送给reducer过程进程再加工,其发送的数据格式为:
{"code":"",
"data":"",
"num":"",
"index":""}
其中data为数据库执行结果。
本发明优选的,根据步骤s4,所述reducer数据加工过程根据code、num、index,将接收到的data顺序进行组合形成如下数据集合:
{"data1":"",
"data2":"",
"data3":""}
并将该集合返回给用户,完成一次完整的查询。
本发明的有益效果在于:
本发明利用数据对象技术先实现对单个数据库进行连接,再对连接共享、加工,使用ansisql,统一使用标准;本发明同主要解决了一是能够同时连接多种数据库,二是各个数据库采用的sql语句是不同的、非标准化的、甚至是独特的,无法进行统一使用的两大问题。
附图说明
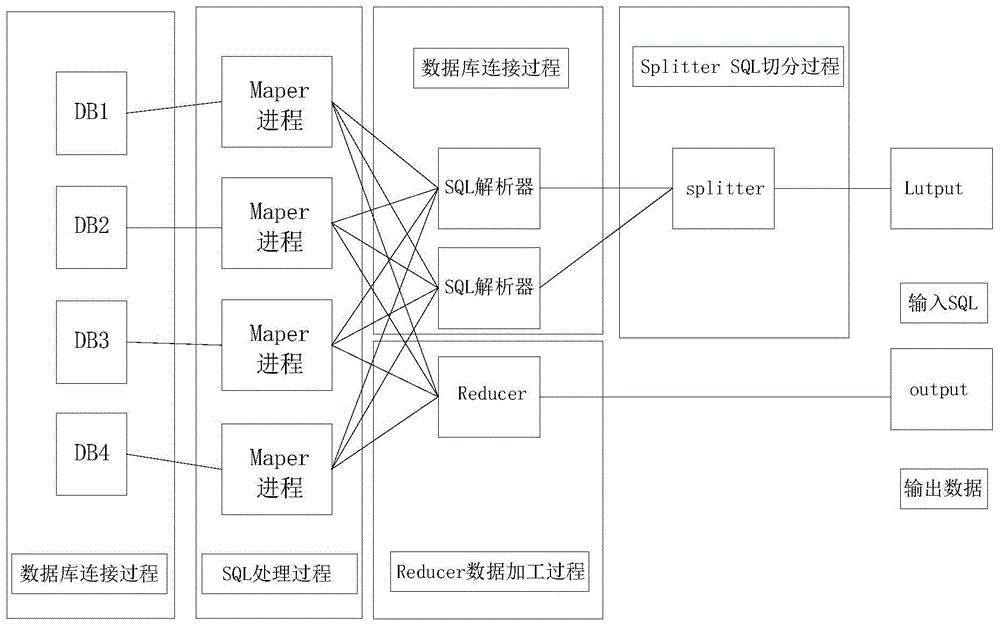
图1是本发明所述一种基于map-reduce原理的多数据库访问方法的过程结构示意图。
具体实施方式
下面结合附图对本发明作进一步说明:
如图1所示:一种基于map-reduce原理的多数据库访问方法,包括以下步骤:
步骤s1,通过配置其mapper进程能与不同的数据库建立一对一的连接;
步骤s2,其整体采用map-reduce的原理,将sql语句进行切分,对应多个数据库,分开查询,最后按顺序进行组合;
步骤s3,其内部通信过程采用随机法发送信息,能够有效地分摊计算量和工作量,均衡内部系统负载,提高整体性能;
步骤s4,其定义了多种内部数据格式,用于实现同时对不同数据库,采用统一ansisql标准查询的功能,具体体现在:
1)用户查询语句格式;
2)数据库连接对象格式;
3)sql切分过程数据格式;
4)sql处理过程数据格式;
5)reducer过程数据格式。
根据步骤s4,所述数据库连接,首先以json格式定义了数据库连接对象描述文件,其包含:
{"type":"",
"ip":"",
"port":"",
"db_name":"",
"user":"",
"pass":""}
该数据对象包含type、ip、port、db_name、user、pass等五个字段,分别为数据库类型,数据库ip地址,数据库端口号,数据库名称,数据库用户名,数据库密码。
通过socket技术向数据库连接对象发起tcp连接,在建立连接后,通过数据库厂商提供的api解析其数据格式,最终建立数据库连接。
根据步骤s4,所述sql切分过程接收到用户输入的查询语句后,用户查询语句格式为:
{"db_name1":{
"sql":"",
"sql2":"",
"type":""}
其中db_name为数据库名,type可不写,当存在不同种类的数据库种数据库重名情况是,需要写明type,以便进行区分;sql为ansi标准的sql语句;
根据sql语句中查询的数据库名,将sql语句进行切分,形成如下格式:
{"type":"",
"db_name":"",
"sql":"",
"code":"",
"data":"",
"num":"",
"index":""}
其中type、db_name与上文相同,sql为ansi标准sql,code随机生成的uuid,代表本次查询,num为切分的总sql条数,index为本sql在所有sql中的顺序;
为了实现高可用性,splittersql切分过程采用随机法发送sql语句到sql解析过程,防止某一个sql解析进程过度繁忙。
根据步骤s4,所述sql解析过程接收到splittersql切分过程发来的sql语句后,sql解析过程根据数据库开发厂商提供的sql标准,将ansi标准的sql语句翻译为适合该数据库标准的sql语句,同样为了高性能,采用随机法将非标准的sql语句发给sql处理过程进行处理。
根据步骤s4,所述sql处理过程,mapper进程收到非标准sql语句后,立即发送给数据库执行,取得数据后,将数据发送给reducer过程进程再加工,其发送的数据格式为:
{"code":"",
"data":"",
"num":"",
"index":""}
其中data为数据库执行结果。
根据步骤s4,所述reducer数据加工过程根据code、num、index,将接收到的data顺序进行组合形成如下数据集合:
{"data1":"",
"data2":"",
"data3":""}
并将该集合返回给用户,完成一次完整的查询。
综上所述,本发明利用数据对象技术先实现对单个数据库进行连接,再对连接共享、加工,使用ansisql,统一使用标准;本发明同主要解决了一是能够同时连接多种数据库,二是各个数据库采用的sql语句是不同的、非标准化的、甚至是独特的,无法进行统一使用的两大问题。
本领域技术人员不脱离本发明的实质和精神,可以有多种变形方案实现本发明,以上所述仅为本发明较佳可行的实施例而已,并非因此局限本发明的权利范围,凡运用本发明说明书及附图内容所作的等效结构变化,均包含于本发明的权利范围之内。
- 还没有人留言评论。精彩留言会获得点赞!