一种基于猫头鹰搜索算法的计算密集型云工作流调度方法与流程
本发明涉及一种云工作流调度方法,具体涉及一种基于猫头鹰搜索算法的计算密集型云工作流调度方法,属于云计算技术领域。
背景技术:
云计算作为一种商业计算模式,采用虚拟化技术,将数据中心的存储、计算以及网络通信等资源整合为一个共享的、可动态配置的计算资源池,为用户提供按使用付费的计算服务。用户无需购置任何服务器等硬件资源,即可通过可用的、便捷的网络访问,进入可配置的共享计算资源池(例如服务器、存储、应用软件和网络等),按需获取计算能力、存储空间和信息服务。
随着云计算的不断发展,大规模的复杂工作流成为云计算应用的新模式。云工作流的执行主要包括任务调度和资源供给两个阶段。在任务调度过程中,需要根据适当的调度策略,为用户请求的任务选择合适的虚拟机,并满足其服务质量(qos)等约束,从而完成整个调度过程。计算密集型云工作流,由多个具有相互依赖关系的子任务组成,因此,在整个工作流调度过程中,不仅要考虑任务的执行时间,还需要满足任务之间的依赖关系约束并使得整个工作流的执行跨度时间(makespan)最短。不同的任务分配策略会直接影响整个云工作流的执行时间与成本,如何为云工作流任务分配最合适的计算资源,并在满足任务间逻辑依赖约束的同时实现其调度目标,成为各个云服务提供商亟需解决的问题。
云工作流调度是一类典型的np-hard问题,目前,主要采用启发式算法和随机搜索算法求解。启发式算法主要分为列表调度、任务复制、任务集合簇等,例如heft、min-min、min-max,不易找到近优解。随机搜索算法,主要包括遗传算法、粒子群算法、免疫进化算法等,本质是设计一种高效的搜索策略。其中,遗传算法等进化算法具有全局搜索优势以及避免陷入局部最优的能力,但搜索时间过长,影响算法的实时性;群智能优化算法具有收敛速度快,且适应面广,但是缺乏有效的局部搜索机制。
技术实现要素:
本发明的目的是为了解决计算密集型云工作调度问题,提出一种基于改进猫头鹰搜索算法的计算密集型云工作流调度方法。其基本思想是:采用猫头鹰搜索算法,对云工作流中所有依赖任务到虚拟机资源映射的不同调度方案进行遍历搜索,寻找具有最小工作流执行跨度时间的调度方案。同时,根据云工作流的特点,对现有的猫头鹰搜索算法进行改进,一是通过声强平方反比定律将强度变化量定义为最优解(即最优调度方案)对其它不同个体(或调度方案)的影响大小,并以此对不同个体的寻优步长进行自适应调节,从而大大提高了最优解的搜索效率;二是针对云工作流调度问题的特点,修改了个体的寻优方向,以避免产生过多的无效解,并使所有个体根据不同的步长直接向最优解逐渐逼近,从而提高了个体解的稳定性、改善了整个算法的寻优速度;三是针对群智能优化算法容易陷入局部最优的问题,利用进化计算的变异思想,通过在种群迭代更新机制中增加变异策略来引入随机性,并当最优解迭代l次尚未更新时,随机更改一些调度方案中个别任务与虚拟机的映射关系,以跳出局部最优,寻找全局更好的调度方案。
本发明方法包括以下步骤:
步骤一、输入用户提交的待调度计算密集型云工作流模型及其所包含的依赖子任务集合,可供租赁的虚拟机集合;
步骤二、将各云工作流子任务调度至最合适虚拟机上执行的过程,建模为标准的最小值求解问题。其调度目标为:优化整个云工作流的执行跨度时间makespan,使所有云工作流任务执行完毕所花费的时间最短。
步骤三、利用基于声强平方反比定律的猫头鹰搜索算法,求解云计算环境下的任务-虚拟机调度问题。迭代过程包括以下步骤:
步骤1、初始化算法的基本参数,包括步长参数β、调度方案个数m以及最大迭代次数iteration、第一次出现最优解时的寻优迭代次数bestnum;
步骤2、使用均匀分布的随机数来初始化每个调度方案;
步骤3、算法迭代过程中,当迭代次数t小于最大迭代次数iteration时,t=t+1,转步骤4;当迭代次数t大于或等于最大迭代次数iteration时,转步骤8;
步骤4、根据云工作流模型,即子任务之间的依赖关系,计算当前代中所有调度方案的工作流执行跨度时间makespan;
步骤5、找到当前代中最佳的调度方案。如果最优解有更新,则bestnum=t。更新每个调度方案与当前最优解的距离信息以及每个调度方案的强度变化量;
步骤6、判断是否已经迭代l代而其最优解仍然没有更新,若t-bestnum>l,则使用遗传变异的思想,随机更改任一个体的任一位置的虚拟机映射关系,转步骤7;否则,直接转步骤7;
步骤7、根据强度变化量,对当前代的所有调度方案进行更新,并返回步骤3;
步骤8、找到最优调度方案,按照调度方案给出的任务与虚拟机映射关系,将工作流子任务与虚拟机进行绑定。
有益效果
本发明能够有效克服现有方法中最优解搜索随机性大、易于陷入局部最优且收敛速度慢的缺点,提升搜索效率、缩短搜索时间,可在更短的时间内寻找到更优的调度方案,减少工作流调度的总体时间开销,具体包括以下三点:
1、首次将猫头鹰搜索算法应用于调度问题,为计算密集型云工作流调度提供了一条新的解决途径。
2、通过对现有的猫头鹰搜索算法进行改进,即修改种群更新迭代公式,有效减少了最优解搜索的随机性,提高了搜索效率,使寻优过程更具目标导向性。
3、通过在现有猫头鹰搜索算法的种群迭代更新机制中应用遗传变异思想、引入随机性,有效避免了搜索陷入局部最优的情况,并能够在更短的时间内找到全局更优的调度方案,提高了算法的收敛速度,改善了云工作流调度性能。
附图说明
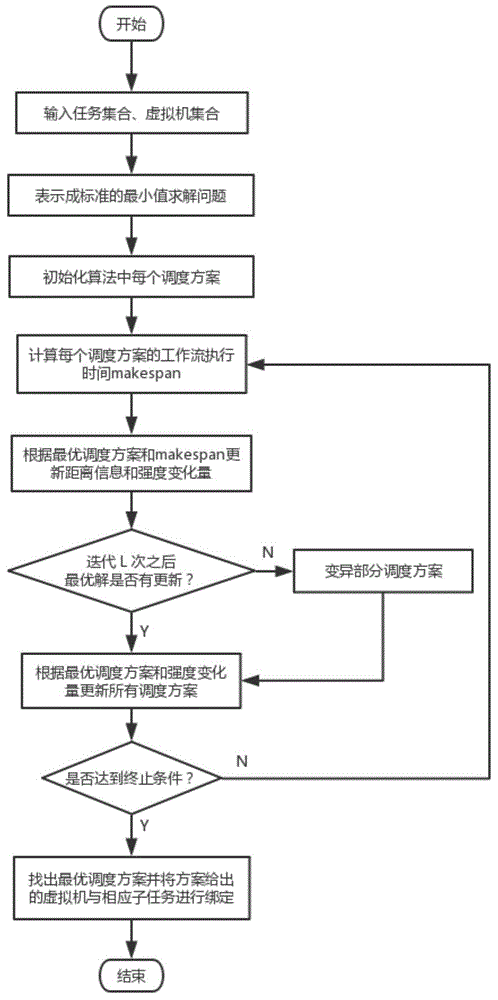
图1为本发明所述的基于猫头鹰搜索算法的云工作流调度方法流程。
图2为一个简单的17个任务的montage工作流。
图3为不同算法针对montage_25执行跨度时间最小值变化过程。
图4为不同算法针对montage_50执行跨度时间最小值变化过程。
图5为不同算法针对montage_100执行跨度时间最小值变化过程。
图6为不同算法针对montage_25寻优过程。
图7为不同算法针对montage_50寻优过程。
图8为不同算法针对montage_100寻优过程。
图9为不同算法的程序运行时间。
图10为不同算法最优调度方案的执行跨度时间的最小值。
具体实施方式
下面结合附图并举实施例,对本发明方法进行详细描述。
一种基于猫头鹰搜索算法的计算密集型云工作流调度方法,如图1所示,包括以下步骤:
步骤一、输入用户提交的待调度计算密集型工作流模型及其相应的依赖子任务集合,可供租赁的虚拟机资源集合;
针对计算密集型云工作流调度问题,将云工作流描述成一个有向无环图g=(t,e),其中:t为有向无环图中节点的集合,表示云工作流中的n个任务,即t={t1,t2,……,ti,tj,……,tn},其中i,j=1,2,……,n;tentry为入口任务,texit为出口任务;e是有向无环图中有向边的集合,e={<ti,tj>|ti,tj∈t},有向边ti→tj表示父任务ti与其子任务tj之间的依赖关系,tj只有在其父任务ti完成后才可以开始执行。如图2所示,一个具有17个任务的简单montage工作流,即任务数量n=17,云工作流图中的有向弧(箭线)表示任务之间的依赖关系e,有向弧上相应的数字表示父、子任务之间需要传输的文件大小。
用vm表示虚拟机,m表示可供用户租赁的虚拟机总个数,虚拟机资源集合可表示为:vm={vm1,vm2,……,vmk,……,vmm},其中k=1,2,...,m。假设mips表示计算设备每秒可处理的百万级机器语言指令数,则虚拟机vmk的处理速度可用mips(vmk)来表示。
步骤二、将各云工作流子任务调度至最合适虚拟机上执行的过程,建模为标准的最小值求解问题。具体如下:
假设:(1)任务集合中的所有子任务都是原子任务,即每个任务都不可再拆分为更小粒度的任务;(2)每个虚拟机在同一时间只能处理一个任务,即仅当虚拟机执行完毕当前正在处理的任务时,才可以接收新任务的请求;(3)任务执行不可中断,即每个子任务在其所租赁的虚拟机上执行或进行计算时,不允许被其它任务请求打断。
调度目标为优化整个云工作流任务的执行跨度时间开销,也就是使所有云工作流子任务执行完毕所花费的总时间makespan最短;
约束条件为云工作流子任务的数目n大于可供租赁的虚拟机的数目m,即n>m;
定义任务ti在虚拟机vmk上的执行时间etc(ti,vmk),以及父任务ti和子任务tj之间的传输时间tt(ti,tj)如下:
其中,length(ti)表示任务ti的指令长度,mips(vmk)表示虚拟机vmk的处理速度;transfersize(ti,tj)表示父任务ti和子任务tj之间的传输文件大小,bandwidth表示虚拟机之间通信线路的带宽。
定义云工作流中任务ti的开始时间st(ti)和完成时间ft(ti)如下:
ft(ti)=st(ti)+etc(ti,vmk)(4)
其中,st(tentry)表示入口任务tentry的开始时间,st(ti)表示任务ti的开始时间,ft(tp)、ft(ti)分别表示任务tp及其子任务ti的完成时间,avail(vmk)表示虚拟机vmk的可用时间,predr(ti)表示任务ti的所有父任务构成的集合,tt(tp,ti)表示任务tp及其子任务ti之间的传输时间。
云工作流的总执行跨度时间开销makespan,用云工作流中所有子任务完成时间的最大值来表示,即:
步骤三、用基于声强平方反比定律的猫头鹰搜索算法,求解云工作流任务-虚拟机调度问题,迭代过程包括以下步骤:
步骤1、初始化算法的基本参数,包括步长参数β、调度方案个数m以及最大迭代次数iteration、第一次出现最优解时的寻优迭代次数bestnum;
步骤2、使用均匀分布的随机数来产生第0代的m个初始调度方案
其中,ol和ou分别是第0代第s个调度方案
步骤3、算法迭代过程中,当迭代次数t小于最大迭代次数iteration时,t=t+1,转步骤4;当迭代次数t大于或等于最大迭代次数iteration时,转步骤8;
步骤4、根据云工作流模型中各个子任务之间的依赖关系,对当前代t产生的每个调度方案
其中,
步骤5、找到当前代中最佳的调度方案。如果最优解有更新,则bestnum=t。对每个调度方案
式中,v表示全局最优调度方案,makespan(v)表示最优调度方案对应的工作流执行跨度时间,random表示[0,1)的随机数;
步骤6、判断是否已经迭代l代而且最优解仍然没有更新。若t-bestnum>l,则使用遗传变异的思想,随机更改任一个体的任一位置的任务-虚拟机映射关系,然后转步骤7;否则,直接转步骤7;
步骤7、根据强度变化量,对当前代t的每个调度方案
其中,
步骤8、找到最优调度方案,按照调度方案给出的任务与虚拟机映射关系,将工作流子任务与虚拟机进行绑定。
实施例
为了检验本发明提出的利用改进的猫头鹰搜索算法(osa)进行云工作流调度的效果,本发明使用了云计算仿真模拟工具workflowsim,用以模拟一个云计算数据中心,并通过对工作流执行跨度时间makespan的估计算法进行优化,提高了makespan的计算效率。实验选取了最常用的智能优化算法作对比,如蚁群算法(aco)、粒子群算法(pso)、遗传算法(ga)。
针对不同规模的montage工作流模型,使用10个相同的虚拟机分别进行实验,选取工作流最小执行跨度时间以及每一代的个体对应工作流的平均执行跨度时间为调度性能指标,来衡量算法的泛化能力和性能,对比结果如图3至图10所示。
由图3、图4、图5可知,针对不同规模的工作流模型,基于猫头鹰搜索的调度算法均能找到较好的解,且只需迭代更少的次数即可找到近似最优解。由图6、图7、图8可知,osa算法寻优速度较快,且不易陷入局部最优。由图9可知,osa的算法时间复杂度较低。由图10可知,对于小型工作流,osa算法均能找到较好解;对于中型和大型工作流,本发明改进的osa算法能找到一个较优的调度方案,其执行跨度时间分别为95.03、174.15,与ga算法的寻优结果相同。但是,由图9可以看出,ga算法的执行时间开销较大,是osa算法的2倍以上。
- 还没有人留言评论。精彩留言会获得点赞!