一种基于FP-growth算法的未来股价预测方法与流程
本发明涉及股价预测技术领域,具体来说,涉及一种基于fp-growth算法的未来股价预测方法。
背景技术:
股票作为一种有价证券,蕴含经济利益、还可以通过上市进行流通转让,同时,股份有限公司在筹集资本时,可以通过签发给各股东的股份来体现持有人对公司部分资产拥有的所有权。交易市场出现的时间最早可以追溯到上世纪六十年代,美国是现代交易市场出现的最早的地方。世界经济金融市场的开放程度自从中国加入wto后得到迅速提高,同时国际市场也为中国企业在境外上市提供了越来越多的机会和空间,因此,中国的证券市场在我国经济发展中的作用显得越来越重要。
伴随着我国不断的加快推进经济转型以及针对实际需求对产业结构的不断调整,越来越多的国内知名的股份有限公司公开在境外的交易所上市并发行股票。股票作为一种蕴含潜力和经济利益的金融产品为更快更好的提高市场经济提供可能,并与国民经济和人们的生活息息相关。同时随着人民生活水平的不断改善和提高,人们的理财方式也变得越来越多样化,因此,促使更多的股票投资者们都参与到股票市场中。但由于股票市场本身的复杂性,容易产生暴涨暴跌的情况,因此需要时刻对股票市场进行观测,以便对股价的走势进行预测,从而最大限度的降低风险,增加收益。而fp-growth算法是韩嘉炜等人在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(fp-tree),但仍保留项集关联信息。在算法中使用了一种称为频繁模式树(frequentpatterntree)的数据结构。fp-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成,fp-growth算法基于以上的结构加快整个挖掘过程。
目前传统的股价预测方法中,常用的进行股价预测的方法主要是基于回归和分类的算法,其中涉及大量的非线性运算和拟合的过程,在实际应用过程中,可能会有不错的效果,但是其缺点在于不可解释性,是一个黑盒子模型,因此无法做到对股价运动的有效解释,而且模型受到不频繁项目的干扰较大。
针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
针对相关技术中的问题,本发明提出一种基于fp-growth算法的未来股价预测方法,以克服现有相关技术所存在的上述技术问题。
本发明的技术方案是这样实现的:
一种基于fp-growth算法的未来股价预测方法,包括以下步骤:
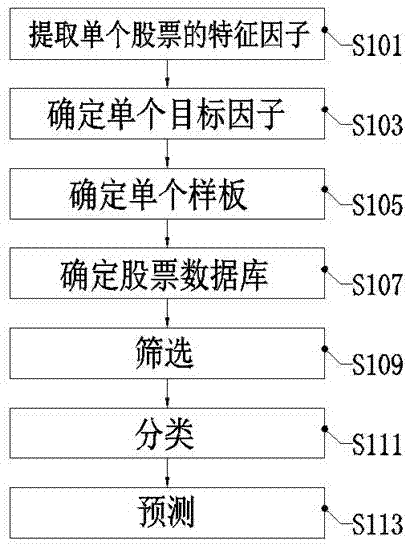
s101、提取单个股票的特征因子:预先通过采集市盈率和利润基本面因子以及均线和波动率技术面因子,并将数值数据转化为分类别的数据,作为股价的基本特征,确定单个股票的特征因子;
s103、确定单个目标因子:预先提取步骤s101中的单个股票的特征因子时间点,并将时间点之后的三个月的股价特征数值数据处理成分类别的数据,确定单个目标因子;
s105、确定单个样板:将步骤s101的单个股票的特征因子和步骤s103的目标因子项目组合,确定单个样本;
s107、确定股票数据库:预先通过将所有股票重复步骤s101、步骤s103和步骤s105,获取多组样本,将多组样本作为训练数据,确定股票数据库;
s109、筛选:预先对步骤s107的股票数据库中的多组样本分别使用fp-growth算法,通过设置阈值,筛选出频繁项集;
s111、分类:将步骤s109的频繁项集,按照步骤s103的目标因子的类别,保留包含高收益的项目集合,过滤掉包含低收益的项目集合;
s113、预测:对于将要进行预测的对象股票,通过步骤s101的特征因子和步骤s111的频繁项集,确定对应的频繁项,确定股价预测。
进一步的,所述s103中的股价特征数值数据,包括未来三个月的股价的均值和未来三个月股价的最高值。
进一步的,所述s101的特征因子的提取时间早于所述s103目标因子的提取时间。
进一步的,所述s109的算法包括fp-growth算法或apriori算法。
本发明的有益效果:通过采用fp-growth算法寻找影响股价的频繁出现的特征,其中不涉及复杂的非线性拟合的过程,只关注不同的特征是否同时出现,可以过滤掉不频繁出现的特征,并且按照目标收益率水平,再做一次过滤,将低收益率的项目过滤掉,可以直观地看到各个因子组合的实际情况,使得具有可直观和可解释的特点,而且fp-growth算法的运算速度较快,相对于常用的回归和分类算法,具有更加高效的优势。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种基于fp-growth算法的未来股价预测方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
根据本发明的实施例,提供了一种基于fp-growth算法的未来股价预测方法。
如图1所示,根据本发明实施例的基于fp-growth算法的未来股价预测方法,包括以下步骤:
s101、提取单个股票的特征因子:预先通过采集市盈率和利润基本面因子以及均线和波动率技术面因子,并将数值数据转化为分类别的数据,作为股价的基本特征,确定单个股票的特征因子;
s103、确定单个目标因子:预先提取步骤s101中的单个股票的特征因子时间点,并将时间点之后的三个月的股价特征数值数据处理成分类别的数据,确定单个目标因子;
s105、确定单个样板:将步骤s101的单个股票的特征因子和步骤s103的目标因子项目组合,确定单个样本;
s107、确定股票数据库:预先通过将所有股票重复步骤s101、步骤s103和步骤s105,获取多组样本,将多组样本作为训练数据,确定股票数据库;
s109、筛选:预先对步骤s107的股票数据库中的多组样本分别使用fp-growth算法,通过设置阈值,筛选出频繁项集;
s111、分类:将步骤s109的频繁项集,按照步骤s103的目标因子的类别,保留包含高收益的项目集合,过滤掉包含低收益的项目集合;
s113、预测:对于将要进行预测的对象股票,通过步骤s101的特征因子和步骤s111的频繁项集,确定对应的频繁项,确定股价预测。
借助于上述技术方案,通过采用fp-growth算法寻找影响股价的频繁出现的特征,其中不涉及复杂的非线性拟合的过程,只关注不同的特征是否同时出现,可以过滤掉不频繁出现的特征,并且按照目标收益率水平,再做一次过滤,将低收益率的项目过滤掉,可以直观地看到各个因子组合的实际情况,使得具有可直观和可解释的特点,而且fp-growth算法的运算速度较快,相对于常用的回归和分类算法,具有更加高效的优势。
另外,在一个实施例中,所述s103中的股价特征数值数据,包括未来三个月的股价的均值和未来三个月股价的最高值。
另外,在一个实施例中,所述s101的特征因子的提取时间早于所述s103目标因子的提取时间。
另外,在一个实施例中,所述s109的算法包括fp-growth算法或apriori算法。
另外,在一个实施例中,对于上述特征因子和目标因子来说,因子提取方面,需要将特征因子和目标因子按照时间点分开,在逻辑上,特征因子是目标因子的原因,因此特征因子的提取必须要在该时间点之前,而目标因子需要在该时间点之后,否则会引入未来信息。
另外,在一个实施例中,需要将提取的数值类型的数据转化为类别类型的数据,数据分组数目需要根据算法的表现不断调整,如果分组数目过多,出现的频繁项就会过多,模型的泛化能力会比较差;如果分组的数目太少,则虽然泛化能力足够,但是预测能力有限,直观地看到各个因子组合的实际情况。
另外,在一个实施例中,对于上述频繁项集来说,在初步筛选出频繁项集之后,还需要按照应用的目标,将收益率低的部分过滤掉,保留收益率高的部分。
综上所述,借助于本发明的上述技术方案,通过采用fp-growth算法寻找影响股价的频繁出现的特征,其中不涉及复杂的非线性拟合的过程,只关注不同的特征是否同时出现,可以过滤掉不频繁出现的特征,并且按照目标收益率水平,再做一次过滤,将低收益率的项目过滤掉,可以直观地看到各个因子组合的实际情况,使得具有可直观和可解释的特点,而且fp-growth算法的运算速度较快,相对于常用的回归和分类算法,具有更加高效的优势。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!