一种基于声场定位的现实模拟方法及智能穿戴设备与流程
本发明涉及现实模拟与反馈的方法,特别涉及一种基于声场定位的现实模拟方法。
背景技术:
声学成像(acousticimaging)是基于传声器阵列测量技术,通过测量一定空间内的声波到达各传声器的信号相位差异,依据相控阵原理确定声源的位置,测量声源的幅值,并以图像的方式显示声源在空间的分布,即取得空间声场分布云图-声像图,其中以图像的颜色和亮度代表声音的强弱。
声成像的研究开始于20世纪20年代末期。最早使用的方法是液面形变法。随后,很多种声成像方法相继出现,至70年代已形成一些较为成熟的方法,并有了大量的商品化产品。声成像方法可分为主动声成像、扫描声成像和声全息。
由于很多声检测器均能记录声波的幅度和相位,并将其转换成相应的电信号,记录换能器阵列各单元接收信号的幅度和相位,即可重现物体声像。
目前随着虚拟现实技术的发展,出现了很多智能的穿戴设备。通过投影眼镜或者显示屏可以将虚拟的物体投射于现实的影像中。但是这些装置一般缺少相应的反馈动作,佩戴者的代入感不强,难以形成较好的沉浸式虚拟现实体验。
技术实现要素:
本发明的一个目的是提供一种基于声场定位的现实模拟方法。本发明的另一个目的是提供一种用于现实模拟的智能穿戴设备。
根据本发明的一个方面,提供了一种基于声场定位的现实模拟方法,包括:
在空间周围设置多个的扬声器;
扬声器通过一个音频解码器与音频输出装置相连接,音频解码器将音频输出装置输出的音频信号进行解码,从而在空间内部的受体周围形成一个立体的声场;
音频解码器通过调节各个扬声器的输出的声波信号的声强差、时间差以及波形相位差,从而在受体周围的空间内确定一个虚拟声源;
虚拟声源位于受体周围且其方位与其他的场景信息相对应并匹配,受体通过场景信息结合虚拟声源获得一个将虚拟场景现实化的一个真实体验。
在一些实施方式中,多个扬声器构成一个三轴定位声场。
在一些实施方式中,多个扬声器至少包括至少三组分别没置在不同的维度上的扬声器,扬声器分别设于空间的边缘。
在一些实施方式中,其他的场景信息包括受体接收到的视觉信息和/或受体表面相应的部位产生的动作反馈,动作反馈包括振动刺激、微流电击和挤压刺激。
在一些实施方式中,受体为穿戴有一个与中央处理器相连接的智能穿戴设备的人,受体处于声场中,智能穿戴设备用于接受中央处理器控制并对受体施加动作反馈。
采用以上技术方案的基于声场定位的现实模拟方法,通过三轴声场定位技术拟合出一个虚拟声源并将该虚拟声源与其他的场景信息相对应并匹配,由此获得一个将虚拟场景现实化的一个真实体验。该方法还针对虚拟声源的方位在相应的反馈位置执行反馈动作,通过对受体进行刺激,从而进一步增加现实代入感。
根据本发明的另一个方面,提供了一种用于现实模拟的智能穿戴设备,智能穿戴设备为智能马甲或者智能外套,智能马甲或者智能外套分布有多个换能器、微流电击装置或者可控充气气囊,中央处理器控制换能器、微流电击装置或者可控充气气囊与扬声器同步动作,从而产生与虚拟声源相对应的动作反馈。
在一些实施方式中,智能马甲或者智能外套沿受体表面分为多个独立控制的反馈区域,反馈区域按照点阵式设置且每个反馈区域分别设有换能器或者微流电击装置,中央处理器设有一个点阵驱动器,点阵驱动器与换能器或者微流电击装置相连接,并对换能器或者微流电击装置进行独立的控制。
在一些实施方式中,智能马甲或者智能外套至少具有以下三种工作模式其中之一:
贯穿模式,用于模拟利器或者子弹对人体产生的贯穿感觉,在此模式下,受体两个表面上相对应的且不相邻的两个反馈区域进行反馈动作,两个反馈区域同时进行反馈动作,或者靠近虚拟声源的反馈区域的先进行反馈动作,另一反馈区域随后进行反馈动作,虚拟声源位于受体一侧或者先位于受体一侧然后跳跃至受体另一侧;
剐蹭模式,用于模拟外部环境中的物体对人体产生的剐蹭或者抚摸的感觉,在此模式下,受体表面上的多个相邻的反馈区域按照一条路径依次进行反馈动作,多个反馈区域按照点动的方式动作,另一个反馈区域动作时前一个反馈区域停止,虚拟声源沿与路径相对应的范围进行移动;
切割模式,用于模拟利器对人体产生的切割感觉,在此模式下,受体表面上的多个相邻的反馈区域按照一条路径依次进行反馈动作,多个反馈区域按照自锁的方式动作,另一个反馈区域动作时前一个反馈区域继续保留,直至整做反馈动作完成,虚拟声源沿与路径相对应的范围进行移动。
在一些实施方式中,智能马甲或者智能外套沿受体表面设有多个可控充气气囊,每个可控充气气囊对应一个或者多个反馈区域,可控充气气囊分别与排气阀和充气泵相连接,排气阀和充气泵与中央处理器相连接,中央处理器通过排气阀和充气泵控制可控充气气囊的充放气,当可控充气气囊充气时,智能马甲或者智能外套对受体的相应区域产生挤压刺激。
在一些实施方式中,智能马甲或者智能外套通过可控充气气囊实现撞击模式,撞击模式用于模拟外部环境中高速运动的物体对人体造成的撞击感觉。
采用以上技术方案的用于现实模拟的智能穿戴设备,针对虚拟声源的方位在相应的反馈位置执行反馈动作,通过对受体进行刺激,从而进一步增加现实代入感。
附图说明
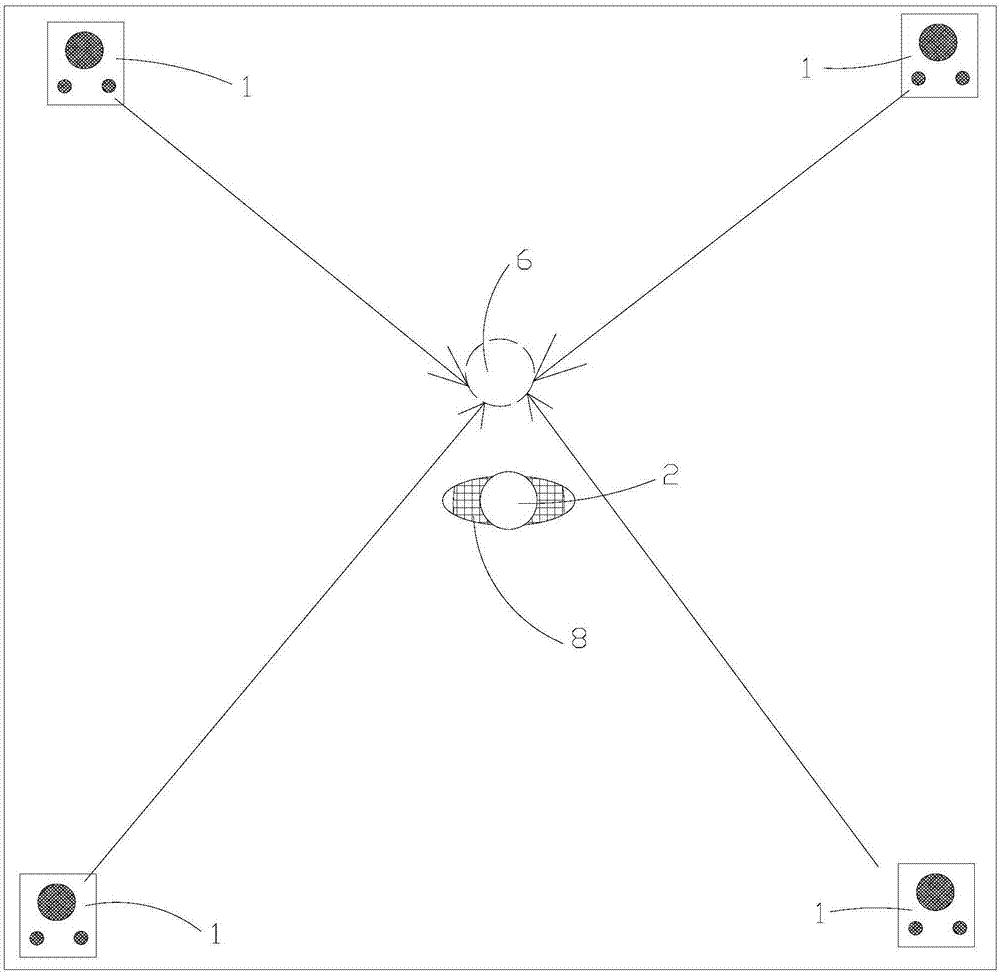
图1为本发明一种实施方式的基于声场定位的现实模拟方法的声场的布置结构示意图。
图2为基于声场定位的现实模拟方法的装置连接关系图。
图3为本发明一种实施方式的用于现实模拟的智能马甲的结构示意图。
图4为图3所示的智能马甲的贯穿模式的反馈过程示意图。
图5为图3所示的智能马甲的剐蹭模式的反馈过程示意图。
图6为图3所示的智能马甲的切割模式的反馈过程示意图。
图7为本发明另一种实施方式的基于声场定位的现实模拟方法的声场的装置连接关系图。
具体实施方式
下面结合附图对本发明作进一步详细的说明。
实施例1
图1至图3示意性地显示了根据本发明的一种实施方式的一种基于声场定位的现实模拟方法。
如图1所示,声场由设置在空间周围的多个扬声器1共同构建。
受体2为穿戴有可穿戴式智能穿戴设备的人。
其中,扬声器1通过一个音频解码器4与音频输出装置5相连接。
音频解码器4将音频输出装置5输出的音频信号进行解码,形成多个声道并通过扬声器1产生声波信号,从而在空间内部的受体2周围形成一个立体的声场。
音频解码器4通过调节各个扬声器1的输出的声波信号的声强差、时间差以及波形相位差。
人耳在接收到各个扬声器1声波信号后在受体2周围的空间内确定一个虚拟声源6。
虚拟声源6位于受体2周围且其方位与其他的场景信息相对应并匹配。
受体2通过场景信息结合虚拟声源6获得一个将虚拟场景现实化的一个真实体验。
在本实施例中,多个扬声器1构成一个三轴定位声场。
优选地,多个扬声器1至少包括至少三组分别没置在不同的维度上的扬声器1。扬声器1分别设于空间的边缘。
在本实施例中,其他的场景信息包括受体2接收到的视觉信息和/或受体表面相应的部位产生的动作反馈,动作反馈包括振动刺激、微流电击和挤压刺激。
在本实施例中,受体2为穿戴有一个与中央处理器7相连接的智能穿戴设备的人。
受体2处于声场中,智能穿戴设备用于接受中央处理器7控制并对受体2施加动作反馈。
在本实施例中,智能穿戴设备为智能马甲8,智能马甲8分布有多个换能器91或者微流电击装置92。
换能器91是利用某些单晶材料的压电效应和某些多晶材料的电致伸缩效应来将电能与声能进行相互转换的器件。因其电声效率高、功率容量大以及结构和形状可以根据不同的应用分别进行设计,在功率超声领域应用广泛。
微流电击装置92将电流直接进入人体内从而在人体表面引起的轻微电击,电流强度小于1微安,从而不会对人体造成伤害。
中央处理器7控制换能器91、微流电击装置92或者可控充气气囊93与扬声器1同步动作,从而产生与虚拟声源6相对应的动作反馈。
在其他的实施例中,智能穿戴设备还可以为智能外套或者智能头盔等装备。
如图3所示,智能马甲8沿受体2表面分为多个独立控制的反馈区域81。
反馈区域81按照点阵式设置且每个反馈区域91分别设有换能器91或者微流电击装置92。
中央处理器7设有一个点阵驱动器71。
点阵驱动器71与换能器91或者微流电击装置92相连接,并对换能器91或者微流电击装置92进行独立的控制。
如图4至图6所示,智能马甲8至少具有以下三种工作模式其中之一:
贯穿模式,用于模拟利器或者子弹对人体产生的贯穿感觉,在此模式下,受体两个表面上相对应的且不相邻的两个反馈区域(81a,81b)进行反馈动作,两个反馈区域(81a,81b)可以同时进行反馈动作,也可以靠近虚拟声源6的反馈区域(81a)的先进行反馈动作,另一反馈区域(81b)随后进行反馈动作,虚拟声源位于受体一侧或者先位于受体一侧然后跳跃至受体另一侧。
剐蹭模式,用于模拟外部环境中的物体对人体产生的剐蹭或者抚摸的感觉,在此模式下,受体表面上的多个相邻的反馈区域(81c,81d,81e,81f)按照一条路径a依次进行反馈动作,多个反馈区(81c,81d,81e,81f)域按照点动的方式动作,另一个反馈区域动作时前一个反馈区域停止,虚拟声源沿与路径a相对应的范围进行移动。
切割模式,用于模拟利器对人体产生的切割感觉,在此模式下,受体表面上的多个相邻的反馈区域(81c,81d,81e,81f)按照一条路径a依次进行反馈动作,多个反馈区域(81c,81d,81e,81f)按照自锁的方式动作,另一个反馈区域动作时前一个反馈区域继续保留,直至整做反馈动作完成,虚拟声源沿与路径a相对应的范围进行移动。
采用以上技术方案的基于声场定位的现实模拟方法,通过三轴声场定位技术拟合出一个虚拟声源并将该虚拟声源与其他的场景信息相对应并匹配,由此获得一个将虚拟场景现实化的一个真实体验。该方法还针对虚拟声源的方位在相应的反馈位置执行反馈动作,通过对受体进行刺激,从而进一步增加现实代入感。
实施例2
图7示意性地显示了根据本发明的另一种实施方式的用于现实模拟的智能穿戴设备。与实施例1的不同之处在于,智能马甲或者智能外套沿受体表面设有多个可控充气气囊93。
每个可控充气气囊93对应智能马甲或者智能外套的一个或者多个反馈区域。
可控充气气囊93分别与排气阀931和充气泵932相连接。
排气阀931和充气泵932与中央处理器7相连接。
中央处理器7通过排气阀931和充气泵932控制可控充气气囊93的充放气。
当可控充气气囊93充气时,智能马甲或者智能外套对受体的相应区域产生挤压刺激。由此智能马甲或者智能外套通过可控充气气囊93实现撞击模式,撞击模式用于模拟外部环境中高速运动的物体对人体造成的撞击感觉,从而可以突出冲击的感觉。
以上所述的仅是本发明的一些实施方式。对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!