文本关系抽取模型的训练方法、装置及可读存储介质与流程
本发明涉及自然语言处理领域,尤其涉及一种文本关系抽取模型的训练方法、装置及计算机可读介质。
背景技术:
实体关系抽取是自然语言处理任务中一个重要研究领域,其主要目的是抽取句子中已标记实体对之间的语义关系,即在实体识别的基础上确定无结构文本中实体对间的关系类别,并形成结构化的数据以便存储和取用。通过实体关系抽取可以构建知识图谱或本体知识库,为自动问答系统提供数据支持,同时实体关系抽取也为其他自然语言处理技术提供理论支持。
在关系抽取中通常面临同一句话中包含多类实体,每两类实体间也包含多种关系,对于这种类型的文本关系分类通常采用通过添加实体类型作为特征来训练一个模型处理所有类别关系。例如,通过训练好的词向量和位置向量特征,利用双向lstm编码实体的上下文信息,然后输出标记实体对应位置的向量,并将其输入至cnn神经网络,以输出两个实体名词对应的语义信息,最终输入至分类器中进行分类。但是该专利在卷积层只利用了实体词对应位置中双向lstm的隐藏层向量,往往会丢失一些语义信息,同时只适合抽取粗粒度下的实体关系抽取任务,并没有进一步考虑到细粒度下实体关系的区别,从而导致实体关系抽取效果不佳。
技术实现要素:
本发明的主要目的在于提供一种文本关系抽取模型的训练方法、装置及计算机可读存储介质,旨在在提供一种文本实体关系抽取模型的训练方法,实现了更细粒度下实体关系的识别,改善了模型抽取实体关系的效果。
为实现上述目的,本发明提供一种文本关系抽取模型的训练方法,所述文本关系抽取模型的训练方法包括以下步骤:
获取训练文本中实体对的向量及所述训练文本中每个字的字向量;
计算所述字向量与所述实体对的向量之间的位置信息,并根据所述位置信息生成位置向量;
将所述字向量与所述位置向量拼接,生成联合字向量;
获取所述实体对的向量对应的关系类别向量;
根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字向量确定所述训练文本的特征向量;
基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。
优选地,所述计算所述字向量与所述实体对的向量之间的位置信息,并根据所述位置信息生成位置向量的步骤包括:
获取所述字向量与所述第一实体的向量之间的第一距离,以及所述字向量与所述第二实体的向量之间的第二距离;
根据所述第一距离和所述第二距离生成位置向量。
优选地,所述根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字字向量确定所述训练文本的特征向量的步骤包括:
计算各个所述联合字向量与所述关系类别向量的余弦相似度;
将所述余弦相似度通过卷积神经网络的处理得到各个所述联合字向量关于关系类别向量的注意力得分;
对所述注意力得分进行最大池化操作,得到最大池化后的注意力得分;
将所述最大池化后的注意力得分进行归一化处理,得到各个所述联合字向量的注意力权重;
将所述注意力权重乘以对应的所述联合字向量得到所述训练文本的特征向量。
优选地,所述基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数的步骤包括:
根据当前所述训练文本的特征向量和关系类别矩阵得到所述训练文本的关系类别得分,其中,所述关系类别矩阵为待训练的参数矩阵;
将所述训练训练文本的关系类别得分和所述关系类别矩阵传递到所述约束损失函数中;
采用所述约束损失函数训练参数的过程中,根据当前所述训练样本的实体对的类型特征更新所述关系类别矩阵中对应的参数。
优选地,所述基于所述训练文本的特征向量采用采用约束函数作为损失函数训练所述文本关系抽取模型的参数的步骤之前还包括:
获取所述获取训练文本中实体对的类型特征,并将所述类型特征与所述训练文本的特征向量拼接,生成所述训练文本的拼接特征向量;
基于所述训练文本的拼接特征向量,执行采用约束函数作为损失函数训练所述文本关系抽取模型的参数的步骤。
优选地,所述获取训练文本中实体对的向量的步骤包括:
识别所述训练文本中的实体对;
将所述实体对替换为对应的类型名称;
根据预先训练的词向量和所述训练文本中的类型名称得到对应的实体对的向量。
优选地,所述基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数的步骤之后还包括:
获取待抽取关系的文本;
获取所述待抽取关系的文本中实体对的向量及所述待抽取关系的文本中每个字的字向量;
将所述实体对的向量和所述字向量输入所述文本关系抽取模型中进行处理,得到对所述待抽取关系的文本中实体对的关系类别的预测结果。
优选地,所述训练文本为医疗文本,所述实体的类型包括症状类实体、疾病类实体、检查类实体、治疗实体、存在类修饰、程度类修饰和诱因类修饰。
此外,为实现上述目的,本发明还提供一种文本关系抽取模型的训练装置,其特征在于,所述文本关系抽取模型的训练装置包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的模型训练程序,所述模型训练程序被所述处理器执行时实现如上所述的文本关系抽取模型的训练方法的步骤。
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有模型训练程序,所述模型训练程序被处理器执行时实现如上所述的文本关系抽取模型的训练方法的步骤。
本发明实施例提出的一种文本关系抽取模型的训练方法、装置及存储介质,通过获取训练文本中实体对的向量及所述训练文本中每个字的字向量,然后计算字向量与实体对的向量之间的位置信息,并根据位置信息生成位置向量,然后将所述字向量与所述位置向量拼接,生成联合字向量,以获取实体对的向量对应的关系类别向量;根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字向量确定训练文本的特征向量;基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。这样,提供了一种识别细腻度高的文本实体关系抽取模型的训练方法,从而改善了实体关系抽取模型抽取实体关系的效果。
附图说明
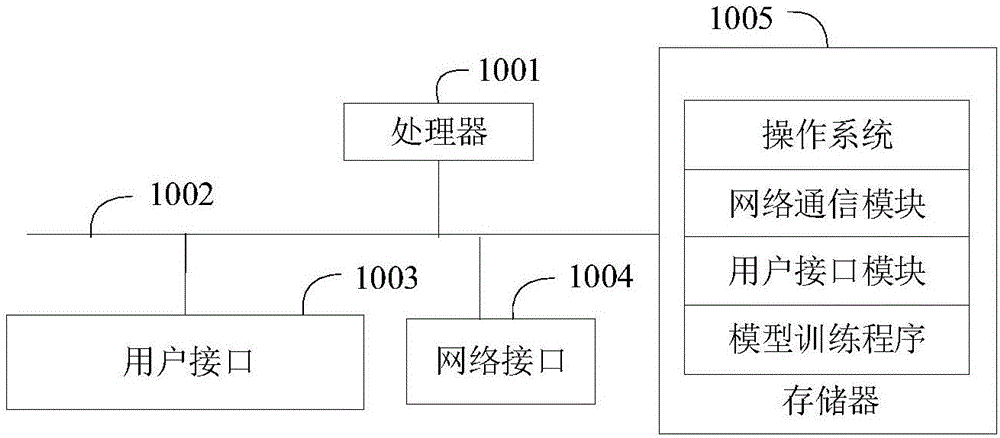
图1是本发明实施例方案涉及的硬件运行环境的终端结构示意图;
图2为本发明文本关系抽取模型的训练方法第一实施例的流程示意图;
图3为本发明根据文本关系抽取模型预测文本实体关系类别的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例的主要解决方案是:
获取训练文本中实体对的向量及所述训练文本中每个字的字向量;
计算所述字向量与所述实体对的向量之间的位置信息,并根据所述位置信息生成位置向量;
将所述字向量与所述位置向量拼接,生成联合字向量;
获取所述实体对的向量对应的关系类别向量;
根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字向量确定所述训练文本的特征向量;
基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。
由于现有技术,在关系抽取中通常面临同一句话中包含多类实体,每两类实体间也包含多种关系,对于这种类型的文本关系分类通常采用通过添加实体类型作为特征来训练一个模型处理所有类别关系。例如,通过训练好的词向量和位置向量特征,利用双向lstm编码实体的上下文信息,然后输出标记实体对应位置的向量,并将其输入至cnn神经网络,以输出两个实体名词对应的语义信息,最终输入至分类器中进行分类。但是该专利在卷积层只利用了实体词对应位置中双向lstm的隐藏层向量,往往会丢失一些语义信息,同时只适合抽取粗粒度下的关系抽取任务,并没有进一步考虑到细粒度下关系的区别,从而导致实体关系抽取效果不佳。
本发明实施例提出的一种文本关系抽取模型的训练方法、装置及存储介质,通过获取训练文本中实体对的向量及所述训练文本中每个字的字向量,然后计算字向量与实体对的向量之间的位置信息,并根据位置信息生成位置向量,然后将所述字向量与所述位置向量拼接,生成联合字向量,以获取实体对的向量对应的关系类别向量;根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字向量确定训练文本的特征向量;基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。这样,提供了一种识别细腻度高的文本实体关系抽取模型的训练方法,从而改善了实体关系抽取模型抽取实体关系的效果。
如图1所示,图1是本发明实施例方案涉及的硬件运行环境的终端结构示意图。
本发明实施例终端可以是pc,也可以是便携计算机、智能移动终端或服务器等终端设备。
如图1所示,该终端可以包括:处理器1001,例如cpu,网络接口1004,用户接口1003,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard)、鼠标等,可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的终端结构并不构成对终端的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及模型训练程序。
在图1所示的终端中,网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;用户接口1003主要用于连接客户端(用户端),与客户端进行数据通信;而处理器1001可以用于调用存储器1005中存储的模型训练程序,并执行以下操作:
获取训练文本中实体对的向量及所述训练文本中每个字的字向量;
计算所述字向量与所述实体对的向量之间的位置信息,并根据所述位置信息生成位置向量;
将所述字向量与所述位置向量拼接,生成联合字向量;
获取所述实体对的向量对应的关系类别向量;
根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字向量确定训练文本的特征向量;
基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。
进一步地,处理器1001可以调用存储器1005中存储的模型训练程序,还执行以下操作:
获取所述字向量与所述第一实体的向量之间的第一距离,以及所述字向量与所述第二实体的向量之间的第二距离;
根据所述第一距离和所述第二距离生成位置向量。
进一步地,处理器1001可以调用存储器1005中存储的模型训练程序,还执行以下操作:
所述根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字字向量确定所述训练文本的特征向量的步骤包括:
计算各个所述联合字向量与所述关系类别向量的余弦相似度;
将所述余弦相似度通过卷积神经网络的处理得到各个所述联合字向量关于关系类别向量的注意力得分;
对所述注意力得分进行最大池化操作,得到最大池化后的注意力得分;
将所述最大池化后的注意力得分进行归一化处理,得到各个所述联合字向量的注意力权重;
将所述注意力权重乘以对应的所述联合字向量得到所述训练文本的特征向量。
进一步地,处理器1001可以调用存储器1005中存储的模型训练程序,还执行以下操作:
根据当前所述训练文本的特征向量和关系类别矩阵得到所述训练文本的关系类别得分,其中,所述关系类别矩阵为待训练的参数矩阵;
将所述训练训练文本的关系类别得分和所述关系类别矩阵传递到所述约束损失函数中;
采用所述约束损失函数训练参数的过程中,根据当前所述训练样本的实体对的类型特征更新所述关系类别矩阵中对应的参数。
进一步地,处理器1001可以调用存储器1005中存储的模型训练程序,还执行以下操作:
获取所述获取训练文本中实体对的类型特征,并将所述类型特征与所述训练文本的特征向量拼接,生成所述训练文本的拼接特征向量;
基于所述训练文本的拼接特征向量,执行采用约束函数作为损失函数训练所述文本关系抽取模型的参数的步骤。
进一步地,处理器1001可以调用存储器1005中存储的模型训练程序,还执行以下操作:
识别所述训练文本中的实体对;
将所述实体对替换为对应的类型名称;
根据预先训练的词向量和所述训练文本中的类型名称得到对应的实体对的向量。
进一步地,处理器1001可以调用存储器1005中存储的模型训练程序,还执行以下操作:
获取待抽取关系的文本;
获取所述待抽取关系的文本中实体对的向量及所述待抽取关系的文本中每个字的字向量;
将所述实体对的向量和所述字向量输入所述文本关系抽取模型中进行处理,得到对所述待抽取关系的文本中实体对的关系类别的预测结果。
参照图2,本发明文本关系抽取模型的训练方法第一实施例,所述文本关系抽取模型的训练方法包括:
步骤s10、获取训练文本中实体对的向量及所述训练文本中每个字的字向量;
在本实施例中,所述训练文本是已经标注出具体实体,且实体间的关系已经明确标注的文本。所述训练文本可以任意文本,所述文本的内容可以是由任意语种的可识别文字记载的内容信息。本领域技术人员可以理解的是,根据不同语种的训练文本训练出的文本关系抽取模型,可以处理对应语种的的文本。由于所述训练文本是标注的文本,因此可以直接通过所述训练文本获取到所述实体对的向量及所述训练文本中每个字的字向量。
具体地,获取所述实体对的向量和所述字向量时,可以先根据所述训练文本中的标注信息确定实体对和对应的文字,然后根据向量映射表将所述实体对和所述训练文本中的每一个字,转化为实体对的向量和每一个字的字向量。
进一步地,由于包含多于一个词的实体不利于特征提取,获取训练文本中实体对的向量时,先将识别的实体对替换为对应的实体类型对应的代码,再根据预先获取的实体类型向量得到对应的实体对的向量,其中实体类型向量可以采用独热(one-hot)向量算法获取。例如:她在外院接受了[类固醇]用于这种[肿胀],并且这些治疗还在继续。这里会将[类固醇]替换成t(治疗类别代号)(类固醇属于治疗类实体),[肿胀]替换成症状s(肿胀属于症状类实体)。
步骤s20、计算所述字向量与所述实体对的向量之间的位置信息,并根据所述位置信息生成位置向量;
在本实施例中,在获取到所述字向量与所实体对的向量时,生成位置向量的具步骤包括:
步骤s21、获取所述字向量与所述第一实体的向量之间的第一距离,以及所述字向量与所述第二实体的向量之间的第二距离;
所述实体对由两个实体组成,因此所述实体对的向量由第一实体的向量和第二实体的向量组成。因此可以先获取所述字向量与所述第一实体的向量之间的第一距离,以及所述字向量与所述第二实体的向量之间的第二距离。例如,所述实体对的向量可以是[类固醇-肿胀]对应的向量,所述字向量可以是“她”对应的字向量,获取“她”相对于实体对[类固醇-肿胀]中两个实体的距离分别为-7和-12。
步骤s22、根据所述第一距离和所述第二距离生成位置向量。
在获取到所述距离时,根据所述距离生成位置向量,例如,所述距离分别为-7和-12,则位置向量为(-7,-12)。
步骤s30、将所述字向量与所述位置向量拼接,生成联合字向量;
在本实施例中,在获取到所述位置向量时,可以将所述位置与所述字向量进行拼接,进而以拼接结果作为联合向量。
步骤s40、获取所述实体对的向量对应的关系类别向量;
步骤s50、并根据所述注意力权重和所述联合字向量确定训练文本的特征向量;
在本实施例中,可以先获取所述实体对的向量对用的关系类别向量,所述关系类别向量为所述实体对对应的类别之间的关系。例如,所述实体对对应的类别为“症状”与“检查”时,可以包含以两种关系:
a)检查证实了某症状或检查结果。
b)因为某症状而采取相应的检查。
所述实体对对应的类别为“疾病”与“检查”时,可以包含以两种关系:
a)检查证实了疾病。
b)为了证实疾病而采取的检查
所述实体对对应的类别为“治疗”与“症状”时,可以包含以四种关系:
a)治疗改善了症状。
b)治疗导致了症状。
c)治疗恶化了症状。
d)治疗施加于症状。
在获取到所述关系类别向量时,可以根据所述关系类别向量计算所述字向量的注意力权重,并根据所述注意力权重生成所述训练文本的特征向量,其中,获得所述训练文本的特征向量的步骤包括:
步骤s51、计算各个所述联合字向量与所述关系类别向量的余弦相似度;
在获取到所述关系类别向量c时,根据所述关系类别c和所述联合字向量v计算余弦相似度g,具体计算公式为:
其中,
步骤s52、将所述余弦相似度通过卷积神经网络的处理得到各个所述联合字向量关于关系类别向量的注意力得分;
在本实施例中,在计算得出所述各个联合字向量相对于单个标签的余弦相似度后,通过卷积神经网络的卷积操作得到各个所述字向量相对关系类别向量的注意力得分,其具体计算公式为:
ul=relu(gl-r:l+rw1+b1)
其中,u1为注意力得分,w1为需要学习的权重矩阵,b1为偏置向量,relu表示修正线性仅作为激活函数,g为步骤s51中计算得出的余弦相似度。
步骤s53、对所述注意力得分进行最大池化操作,得到最大池化后的注意力得分;
在计算出所述注意力得分时,可以对所述注意力得分进行池化操作归一化操作。具体地,可以根据以下公式对所述注意了得分u1进行池化操作:
ml=max·pooling(ul)
其中,ml为池化结果,u1为步骤s52中计算得出的注意力得分,max·pooling()为池化函数。
步骤s54、将所述最大池化后的注意力得分进行归一化处理,得到各个所述联合字向量的注意力权重;
步骤s55、将所述注意力权重乘以对应的所述联合字向量得到所述训练文本的特征向量。
在获取到所述池化结果ml时,可以对所述池化结果ml进行归一化操作,其中,归一化操作的具体公式如下:
β=softmax(m)
其中,β为归一化结果,m为池化后的注意力得分。
在获取到所述归一化结果β时,可以根据所述β和字向量,将文本中所有联合字向量在同一维度上进行相加,得到所述训练文本的特征向量的公式如下:
z=∑lβlvl
其中,z为所述训练文本的特征向量,βl和vl分别为所述训练文本中每一个字的注意力权重和字向量。
步骤s60、基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。
在本实施例中,所述基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数的步骤之前,还可以包括:
步骤s70、获取所述获取训练文本中实体对的类型特征,并将所述类型特征与所述训练文本的特征向量拼接,生成所述训练文本的拼接特征向量;
例如获取所述实体对中第一实体对应的类型的向量
将所述类型特征与所述训练文本的特征向量拼接,从而生成所述训练文本的拼接特征向量。
步骤s80、基于所述训练文本的拼接特征向量,执行采用约束函数作为损失函数训练所述文本关系抽取模型的参数的步骤。
优选地,所述步骤s60包括:
步骤s61、根据当前所述训练文本的特征向量和关系类别矩阵得到所述训练文本的关系类别得分,其中,所述关系类别矩阵为待训练的参数矩阵;
步骤s62、将所述训练训练文本的关系类别得分和所述关系类别矩阵传递到所述约束损失函数中;
步骤s63、采用所述约束损失函数训练参数的过程中,根据当前所述训练样本的实体对的类型特征更新所述关系类别矩阵中对应的参数。
具体地,在获取到所述拼接特征向量rc时,根据以下公式计算所述训练文本的关系类别得分s:
s=wclasses·rc
其中,wclasses代表关系类别矩阵,是一个二维神经网络的参数矩阵,在训练过程中学习,行数和关系类别数量一致,列数和拼接特征向量维度一致,这样通过向量乘法,得到这个拼接特征向量关于不同关系类别的一个得分,即判断为不同关系类别的得分。
然后对所述关系类别得分进行归一化处理,归一化处理的公式为:
其中,p(y|x,θ)为归一化处理结果,e为自然常数,sy表示关系类别为y的得分,γ为关系类别集合。sl为拼接特征向量相对于某一关系类别的得分s,也实质上是拼接特征向量对应的实体对相对于某一关系类别的得分。
最后,依据以下约束函数训练所述文本关系抽取模型的参数:
其中,
需要说明的是,
i通常为模型预测的关系的下标,j为所有关系下标{0-9}。只有当i=j时,
此外,在运行约束函数过程中,i的取值被待识别关系的命名实体对所属的大的关系类别所确定。例如:她在外院接受了[类固醇]用于这种[肿胀],并且这些治疗还在继续。这里大的关系类别为治疗类实体与症状类实体之间具有的关系,根据预先定义好,对应的类别关系只有3种,而不是全局的9种关系类别,此时i对应取值为这三种类别关系的编号。
结合具体实例对约束函数算法的解释:
例如训练样本为:她在外院接受了[类固醇]用于这种[肿胀],并且这些治疗还在继续。
1、该训练样本中命名实体对为治疗类实体与症状类实体之间具有的关系,该大的关系类别下有三种具体的关系类别,那么i取值取值为对应的三种关系类别的编号(取值1,2,3);
2、对于i的每次预测一种关系时,遍历所有关系下标j(取值1-9),所以只有i=1,j=1;i=2,j=2;i=3,j=3三种情况时候,c(i,j)值为1,更新的wclasses行数分别是第1,2,3,行。
需要说明的是,wclasses第1,2,3行也就是用于判断治疗类实体与症状类实体对应的神经网络参数,wclasses第4,5,6用于判断症状类实体与检查类实体对应的神经网络参数,当样本中两个实体对应为症状类实体与检查类实体,同理只有i=4,j=4;i=5,j=5;i=6,j=6时候c(i,j)=1,wclasses4,5,6行才会更新。
现有技术中的文本关系抽取模型在训练过程中,对于任何一个待识别关系的实体对,并不考虑实体对对应的类型,wclasses所有行都有更新,而本发明为待识别关系的实体对对应的特征向量中加入了实体对的类别特征,可以只更新该实体对的类别对应的参数,提高训练效率和准确率,这就是本文提出的文本关系抽取模型的一个关键的发明创新之处。
本发明实施例提出的一种文本关系抽取模型的训练方法、装置及存储介质,通过获取训练文本中实体对的向量及所述训练文本中每个字的字向量,然后计算字向量与实体对的向量之间的位置信息,并根据位置信息生成位置向量,然后将所述字向量与所述位置向量拼接,生成联合字向量,以获取实体对的向量对应的关系类别向量;根据所述关系类别向量和所述联合字向量计算所述字向量的注意力权重,并根据所述注意力权重和所述联合字字向量确定;基于所述训练文本的特征向量采用约束损失函数训练所述文本关系抽取模型的参数。这样,提供了一种细腻度高的文本实体关系抽取模型的训练方法,实现细粒度下实体关系的抽取,改善模型抽取实体关系的效果。
进一步地,参照图3,本发明文本关系抽取模型的训练方法第二实施例,基于上述第一实施例,所述步骤s60之后,还包括:
步骤s100、获取待抽取关系的文本;
步骤s200、获取所述待抽取关系的文本中实体对的向量及所述待抽取关系的文本中每个字的字向量;
步骤s300、将所述实体对的向量和所述字向量输入所述文本关系抽取模型中进行处理,得到对所述待抽取关系的文本中实体对的关系类别的预测结果。
下面说明利用本发明文本关系抽取模型训练及预测的具体过程。
1、设置文本关系抽取模型参数:设置模型训练的梯度下降优化算法为adam,损失函数为自定义的上述约束损失函数。
2、获取已标注的电子病历中的现病史文本作为训练样本,其中标注内容包括实体内容、关系类别以及实体所在样本中位置信息。
3、获取训练样本中的关系类别,例如关系一共有14种,采用14维的独热编码算法向量表示每一种关系类别,得到关系类别向量。
4、将训练文本中待抽取关系的实体用对应的实体类别名代码替换。
5、根据预先训练好的字向量获取训练样本中实体对的向量和训练文本中每个字的向量,其中,字向量的维度是300维。
6、获取训练文本中每个字相对每个实体对的位置向量,其中,位置向量特征包括每一个字到实体对相对距离组成,映射成高维的位置特征向量,位置特征向量维度50维。
7、每次输入文本关系抽取模型的句子批量大小为100,句子根据文本长度设定为固定长度50,通过字向量和位置向量形成联合字向量的维度为400维,因此形成联合字向量矩阵为100*50*400。
8、单个关系类别向量通过标准高斯分布随机采样,每个关系类别向量为400维,因此14种关系对应的关系类别矩阵为14*400,根据该关系类别矩阵计算得到每个联合字向量关于关系类别向量的余弦相似度矩阵100*50*14。
9、为进一步捕获连续联合字向量之间的相对空间信息,引入非线性,将余弦相似度矩阵通过卷积神经网络,参数矩阵维度为2r+1(r=2),偏置b维度为14,即以l为中心,距离为r的局部矩阵做一次卷积操作,卷积核大小为14,得到输出矩阵100*50*14,通过对第3维度进行最大池化操作得到输出矩阵为100*50。对输出矩阵第1维度采用softmax函数进行归一化操作,得到每个联合字向量关于关系类别向量的注意力权重矩阵,维数是100*50。
10、根据上一步中得到的注意力权重矩阵100*50与批量句子对应的的联合字向量矩阵100*50*400得到批量句子对应的特征向量,维度为100*50*400,接着将该特征向量的第2维相加得到100*400维的特征向量,即将每个句子用一个400维的特征向量表示,并将该特征向量拼接实体对的实体类型特征向量得到拼接后的特征向量,其中单个实体类型特征向量为40维,拼接后的特征向量维度为100*(400+2*40)。
11、将拼接后的特征向量输入一层全连接网络进行分类,计算出分为不同类别的概率得分,其中关系类别矩阵的维度为14*(400+2*40),关系类别矩阵中的参数在训练过程中学习。
12、当文本关系抽取模型经过训练数据的多次训练达到稳定时,输入待抽取关系的文本,依照上述步骤3至11进行处理,得到待抽取关系的文本的关系类别预测结果。
在本实施例中,在根据所述文本关系抽取模型的训练方法得到文本关系抽取模型时,根据所述文本关系抽取模型进行文本中实体对的关系类别的预测,提供了一种准确高效的文本关系抽取方法。
此外,本发明实施例还提出一种文本关系抽取模型的训练装置,所述文本关系抽取模型的训练装置包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的模型训练程序,所述模型训练程序被所述处理器执行时实现如上各个实施例所述的文本关系抽取模型的训练方法的步骤。
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有模型训练程序,所述模型训练程序被处理器执行时实现如上各个实施例所述的文本关系抽取模型的训练方法的步骤。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是智能移动端,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!