一种基于yolo和质心跟踪的门店入店率统计方法与流程
本发明涉及监控视频、深度学习、计算机视觉、行人检测,特别是涉及一种基于yolo和质心跟踪的门店入店率统计方法。
背景技术:
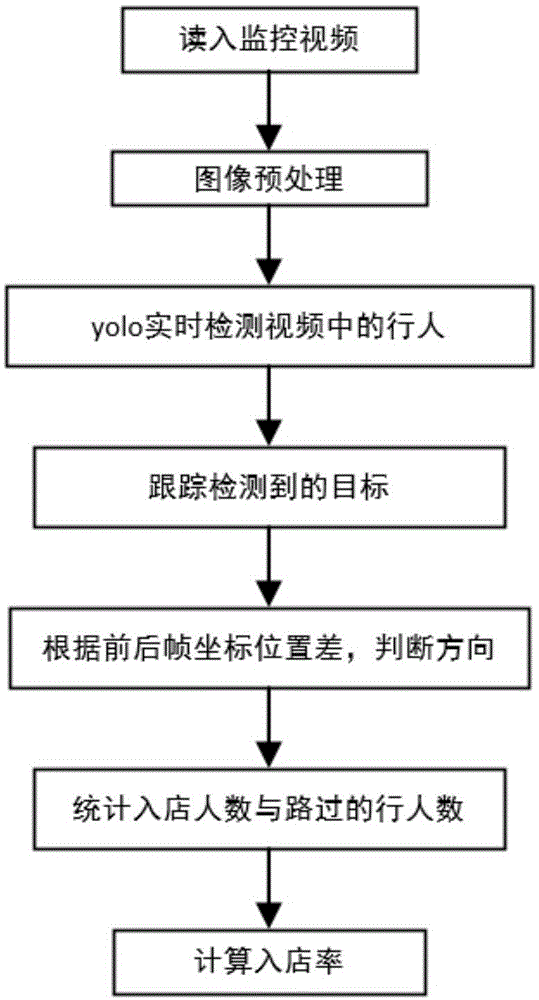
:现如今有一个比较糟糕的状态,每天在店铺门口经过的人很多,但是进店的就很少,然而大的客流量意味着高价房租,高运营成本,如果高的成本得不到相应的报酬,无疑是店铺走向衰亡的开始。为避免这种情况发生,大多数店铺会通过举办活动来吸引客流,例如满赠活动、抽奖、打折等,作为店铺需要了解这些活动中有哪些是对行人心理的正确解读,在店铺门口安装一个摄像头统计客流量与入店的人数,从而能得出哪些积极活动更受行人的注意。店铺的运营成本包括基础设施和员工工资,通过门店入店率统计方法分析每天每个时段的客流量与入店率来分配员工在岗人数,可以有效降低人力资源的浪费并降低运营成本。既有的行人计数主要分为三类,即人工计数、基于传感器的行人计数与基于计算机视觉的行人计数。人工计数费力费才,对于大的人流量来说人工计数就会劣势很多;对于传感器进行行人计数具有局限性,如今红外线属于一个较为普遍的传感器计数方法,为求检测的精度只能设置单通道,不适用于公共场所的大量的行人计数;基于计算机视觉的行人计数可以通过实时的视频分析来获取客流量,具有普适性和便捷性。对于行人检测,已有的方法中,有利用方向梯度直方图作为行人检测的描述子,再用svm进行分类,这种方法精度不是很高,容易误检,而基于深度学习的目标检测方法one-stage和two-stage具有较高的精度,但是运算速度慢,无法达到实时目标检测的效果。技术实现要素:为实现上述发明目的,本发明提供一种基于yolo和质心跟踪的门店入店率统计方法,该方法算法简单,利于软件实现,通过目标检测和质心跟踪算法实现行人运动方向的统计。本发明解决其技术问题所采用的技术方案如下:一种基于yolo和质心跟踪的门店入店率统计方法,包括以下步骤:1)读入高角度监控视频,基于yolov3的检测模型检测行人:读取门店门口监控视频,对输入的每帧图像进行预处理,设置门店营业时间区间,加载yolov3模型;2)启用质心跟踪算法:对检测到的行人,创建对象跟踪器跟踪在框架中移动的对象,直到到达第n帧,重新运行目标检测器;3)计算入店率:跟踪行人目标,通过前后帧的帧间差,计算出行人的运动方向,通过实际的经过门店门口人数与实际入店人数,计算入店率。进一步,所述步骤1)中,输入图像通过特征提取网络darknet53提取特征,从三种不同尺度的特征图谱上进行预测任务的步骤。再进一步,所述步骤2)中,启用质心跟踪算法,对每帧中检测到的对象传入边界框坐标,通过这些边界框坐标,计算出第n帧时的质心坐标(xn,yn),并为它们分配唯一的id,计算新边界框与现有对象之间的欧氏距离,质心跟踪算法假定它们之间具有最小欧氏距离的质心是相同的目标id。更进一步,所述步骤3)中,跟踪行人目标,通过目标的第n帧与第n-1帧的帧间差,计算出行人运动方向,并根据统计出的门店门口实际经过数与入店数得出出入店率。与现有技术相比,本发明技术方案的优点是:(1)本发明提供了一种基于yolo和质心跟踪的门店入店率统计方法,解决了现有检测精度不高且检测模型难以具有实时性的问题。(2)本发明在复杂的环境下,比如人流量较大和光照发生变化的环境下,也具有较高的精度和较快的检测速度。(3)本发明实时的对入店率进行统计,能够较好的帮助门店提高入店转换率和节约运营成本。附图说明图1是行人入店率统计方法的流程图。图2是yolov3的网络结构图。具体实施方式以下结合附图对本发明的原理和特征进行描述,所举实例只应用于解释本发明,并非用于限定本发明的应用。参照图1和图2,一种基于yolo和质心跟踪的门店入店率统计方法,包括以下步骤:1)读入高角度监控视频,用基于yolov3的检测模型检测行人,过程如下;1.1、读取监控视频:在门店门口的摄像头为本发明提供视频数据并预处理每帧图像,将每帧图像的分辨率调为416*416,设置门店营业时间区间,可让程序只关注于营业时间,减少额外的计算资源;设置skip-frames,对象检测在计算上很昂贵,但是它确实有助于我们的跟踪器重新评估帧中的对象,在本发明中,默认检测器模型在检测对象之间跳过50帧。1.2、yolov3实时检测视频中的行人首先对yolov3进行初始化,读取参数文件,解析yolov3模型,加载模型权重。将处理过的视频图像数据同步到gpu显存中,进入yolo网络层处理。yolov3使用的特征提取网络是darknet53,这个网络由残差单元叠加而成,使得训练深层网络难度大大减小。每帧输入的图像首先通过特征提取网络提取特征,输出s*s的卷积特征图,并将输入图像分为s*s个gridcell,通过预测层使用anchorboxes预测目标类别和坐标。boundingbox坐标(bx,by,bw,bh)预测公式为:bx=σ(tx)+cxby=σ(ty)+cy其中tx,ty,tw,th为yolov3为每个boundingbox预测的中心点坐标与预测边框的宽、高,cx,cy为框的中心坐标所在gridcell网格的坐标偏移量,pw,ph为预测前anchor的宽高。在yolov3中一个gridcell有三个anchor,当groundtruth中的某个物体的中心坐标落在那个gridcell中就由该gridcell预测该物体,在选择计算bx,by,bw,bh的loss时,选择三个anchor中confidence最高的那个anchor计算groundtruth的损失,如果没有目标中心点落在该gridcell中,则不计算bx,by,bw,bh的loss,yolov3采用的多分类损失函数为二分类损失函数binary_cross_entropy:其中y(i)为二分类标签值,i∈{1,2},x(i)为预测输出值,值在0~1之间。最后对保留的目标框进行极大抑制处理,去掉重复框,选取目标类别出现概率最高的目标框,并输出其具体坐标。2)启用质心跟踪算法,保持唯一id的分配,过程如下:2.1、通过边界框坐标计算质心在每个帧中为每个检测到的对象传入一组边界框坐标(startxn,startyn,endxn,endyn),通过这些边界框坐标,计算出第n帧时的质心坐标(xn,yn),并为它们分配唯一的id,其中:视频帧中的对象id序列为:id={id1,id2,...,idj}其中,idj为一个对象目标,j∈n。2.2、计算新边界框与现有对象之间的欧氏距离对于视频流中的第n+1帧,应用计算对象质心的步骤2.1;为了不破坏对象跟踪,我们首先需要确定是否可以将第n帧的质心与第n-1帧时的质心相关联,而不是为每一个检测到的对象分配新的唯一id。为了完成这个过程,我们计算在视频中第n帧共出现的个i目标质心和第n-1帧出现的所有id质心之间的欧氏距离d:其中(xin,yin)为第n帧中第i个目标质心的坐标,0≤i≤i,(xj(n-1),yj(n-1))为第n-1帧中idj的质心坐标,j∈n。质心跟踪算法假定它们之间具有最小欧氏距离的质心是相同的目标id,即id(i)=idj,其中(i),j满足d(i)j=min{dij}。2.3、注册新对象对于与任何现有对象质心无法相关联的目标,我们需要注册为新对象,为其分配新的对象id,并存储该对象的边界框坐标的质心,然后重复2.2,为视频流中的每一帧重复该步骤流程。2.4、取消注册旧对象对象跟踪算法还需要能够处理对象何时丢失,消失或离开视野,对于我们的发明,当旧对象无法与现有的任何对象匹配50个连续帧时,我们将取消注册对象id。2.5、创建可跟踪对象为了方便跟踪和计算视频流中的目标,需对可跟踪的目标进行存储,可跟踪对象的条件为:它是对象id,它是之前的质心,该目标未被计算过。存储质心是为了能够方便后续计算该质心的运动方向。3)计算入店率,过程如下:3.1、确定入店出店人数设置视频区域的门线纵坐标位置为h,首先确定质心的运动方向,通过对同一目标id第n帧质心纵坐标与所有前n-1帧的质心坐标平均值的差值(δxn,δyn)来确定目标的运动方向,其中差值计算为:记入店状态为‘1’,出店状态为‘-1’,对行人入店出店行为判别如表1所示,其他情况不作判别依据。δynynyn-1状态>0>h<h1<0<h>h-1表13.2、确定在门外经过的人数为了精确的确定在门店外的客流量,计数分为两部分,一是经过左边视频边界线的人流量,二是经过右边视频边界线的人流量,设置左边视频边界框横坐标位置为w1,右边视频边界框横坐标为w2。记向右经过一个目标,状态为‘r’;向左经过一个目标的状态为‘l’,对行人经过门店行为判别如表2所示,在门店总的经过的人数为两种状态人数之和,其他情况不作判别依据。δxnxnxn-1判断>0>w2<w2r<0<w1>w1l表23.3、计算入店率当在视频监控区间出现从门店出去的人时,会扰乱门外经过人的计数,所以我们采用如下公式来准确的计算t时刻的入店率ηt。其中it为到t时刻的总入店人数,ct为到t时刻的在门店两侧检测到的总的经过人数,ot为到t时刻的总出店人数。实例:一种基于yolo和质心跟踪的门店入店率统计方法的实施方案如下:(1)选取实验数据本发明选取的实验数据为自己采集的实验楼的人流量视频,时长为5min,记录着在这一小时内在实验门口经过的人与进出实验楼的人流量。本发明采用的是yolov3模型,首先需对图像进行预处理,将输入的每一帧图像分辨率调为416*416。如附图2,yolov3使用的特征提取网络是darknet53,这个网络由残差单元叠加而成,使得训练深层网络难度大大减小,不同于之前的yolo版本,yolov3从三种不同尺度的特征图谱上进行预测任务。每帧输入的图像首先通过特征提取网络提取特征,输出13*13的卷积特征图,一共1024个通道,经过一系列的卷积操作得到第一个特征图谱,大小不变,通道数减少为75个通道,在这个特征图谱上做一次预测;将79层的13*13*512的featuremap进行一次卷积和一次*2上采样,生成26*26*256的featuremap,将上采样特征与61层的卷积特征连接,经过一系列卷积特征得到一个26*26*75的特征图谱,在这个特征图谱上做第二次预测;将输入的91层的26*26*256的特征图谱进行一次卷积一次*2上采样,生成52*52*128的featuremap,同时将上采样特征与36层的卷积特征连接,经过卷积操作得到52*52*75大小的特征图谱,在这个特征图谱上做第三次预测。在多尺度特征图谱下做预测,提高了小目标检测的精度。(2)实验结果按照实施例1中的步骤(1)加载模型完毕之后检测行人,计算通行人数与进出门口的人数,结果检测到的入店率精度如表3所示:检测行为检测率行人80%入店66.7%出店90%入店率94%表3。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1